
GANが生成したデータは何?
3つの要点
✔️ その1 GANはbiasを保持するだけではなく、悪化させる。
✔️ その2 GANは学習データの分布を学べていない。
✔️ その3 人とAIどちらで評価しても同じ結果となった。
written by Niharika Jain, Alberto Olmo, Sailik Sengupta, Lydia Manikonda, Subbarao Kambhampati
(Submitted on 26 Jan 2020)
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Image and Video Processing (eess.IV); Machine Learning (stat.ML)
はじめ
今回ご紹介する論文は技術的な内容ではなく、今盛んに行われているGenerative Adversarial Networks(GAN)の使用に関するファンダメンタルな内容になります。GANの基礎についてはこちらの記事をご確認ください。
この内容は一時期SNSで、多くの方が議論をして流行っていたと思います。結局、GANが生成したデータってなんなの?それってData augmentation(以下、DA)に使えるの?と言った疑問に対して人とAIを用いて、GANの生成データを評価したって内容です。
注意点として、GANはまだまだ発展途上であり、結論はまだ先にあると思います。この論文の結果が全てではありません。
紹介
画像認識のDeep learningは、コンピュータービジョンの分野で大きな進歩をもたらしました。そこから研究者はAIがデータに対してoverfittingせずに、実世界に一般化できるように日々研究を行ってきました。実世界への一般化をさせるためにも学習のサンプルサイズを増やしてtest時の精度を高めることが重要です。そのため、DA手法が登場しました。古典的な手法としては、回転や平行移動などの学習サンプルに対してアフィン変換を実行することがもともとのスタート地点だと思います。変換されたサンプルは元のtrainおよびtestと同じ実世界の分布を表す必要があり、これらの方法でtrainサンプルを増やすことで、分類器が実世界の分布を学習する可能性が高くなることを期待しています。
しかし、trainサンプル自体が希少な場合や個人情報を含むものはもともとのサンプルサイズが小さかったり、権利の関係でDA手法がうまく適応できない場合があります。これらの解決方法としてGANが考えられています。特に近年では少量データに対してGANを使用することでこれらの問題を解決できるのではないかと言った検討が行われています。
しかし、著者たちはGANの使用に関して1つの危機感を感じています。それは、GANが完璧に学習データの分布を模倣し、学習データにはあるが今まで見えなかったデータを我々に見せている。また、今までなかったデータを錬金術していると勘違いしていないか?ということです。そのため、容易にGANでDAをしているのではないか。
GANは意外と学習データの分布を学習できていないという内容で、ICLR2018で発表されています。それは誕生日のパラドックスを応用したGANの多様性評価として採択され、ICLRで高スコアを獲得しています(2017年に論文自体は発表されました)。
かなり独自な路線で評価しており、この論文も面白いのでおすすめです。
著者たちが言いたいことを簡単にいうと、GAN自体の学習データに対して配慮されていないのではないか?と言いたいのです。
そこで著者たちはGANが生成した画像を人とAIによって調査するという検討を始めました。
検討
Best Engineering Schoolsにランキングされたアメリカの大学47大学の工学系教授たちの顔を収集し、GANによって顔を生成します。生成された顔画像がどのような傾向を持つか人とAIがそれぞれ1枚ずつ確認していくと言った内容です。
収集方法
収集方法は至ってシンプルです。
- 選出された大学の工学系教授の顔写真を収集する。
- ロゴやアイコンなどが含まれるものは削除する。
- 背景の情報にGANが影響されないように、背景が単色のものに統一する。
- 顔の位置が同じになるように切り出し、画像サイズを64×64に統一する。
- 収集された画像は人によって最終チェックを行う。
最終的に17,245枚の顔画像を収集しています。
評価
元のデータセットとGANの生成画像について、性別と肌の色について評価を行います。事前の情報として、元のデータセットは「男性・白色系」に偏りがあります。そのためGANによる生成も同じ程度の偏りが起きることは予想されます。
今回はDCGANを用いて、画像生成を検討しています。シード値を変えて3回検討を繰り返し、それぞれから画像を生成します。学習回数は50epochで固定しています。
生成された画像は以下のようなセットで被験者たちに示されます。

セットのイメージ図
そして、表示された画像に対して被験者は以下の設問に答えていきます。
性別に関する検討は以下の設問を画像ごとに選択します。
- 実画像に対してこの顔は
a.男性の特徴を持つ
b.女性の特徴を持つ
c.どちらにも当てはまらない - 生成画像に対してこの顔は
a.男性の特徴を持つ
b.女性の特徴を持つ
c.どちらにも当てはまらない
肌の色に関しても同様に以下の設問を画像ごとに選択します。
- 実画像に対してこの顔は
a.白っぽい
b.白くない
c.どちらにも当てはまらない - 生成画像に対してこの顔は
a.白っぽい
b.白くない
c.どちらにも当てはまらない
こう言った検証では被験者の質にも影響があります。
例えば、全ての画像にランダムに回答したり、同じ答えを連続したり。被験者の質は高くないとこう言った検証では結果がおかしくなります。
そこで、Amazon’s MTurk3 を活用します。以前にも複数のタスクを完了して高い評価を得ているマスター資格を持つMTurkワーカーを132人(7分/1.2$)で採用します。各作業者は52枚の画像セット(50枚が実画像と生成画像で、残り2枚は有名人の高画質画像)を評価します。高画質な有名人画像は、ランダムに答えている作業者やBotによる回答を判断するのに活用されています。ここまでの評価は人による人海戦術で行われます。
次は今までの評価をAIでも行います。
用いたAIはMicrosoft Azure Cognitive Services’ Face API4です。このAIを用いた理由は性別と肌の色に関する3つの顔データでSOTAを獲得したためです。
結果
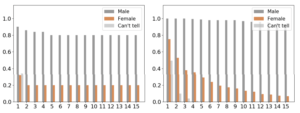
生成されたデータと元のデータでの性別と肌の色については以下の図のような結果になりました。

左の図は顔の特徴が女性の割合がオレンジで示されています(灰色は男性)。右の図は肌の色が白でない割合が青で示されています。
見ての通り、生成データによって優位に偏りが増強されています。本来ならば学習データの分布を学習できるため、偏りを保持することは正しい学習とも言えますが、この結果は明らかに偏りが悪化しています。この結果からもGANが学習データの分布を意外と学習できていないことがわかります。
また、15人の被験者の信頼性評価を表した以下の図では、左の実画像のグラフにおいてはそれぞれの被験者が同じくらいの信頼を持って男性と女性を判断しています。しかし右の合成画像では画質が悪くなり、信頼性が悪くなる可能性があるにかかわらず、男性という判断への信頼性がほとんど変わりません。すなわち、自信を持って男性と答えることができるのです。これは肌の色も同様な結果を示します。
また、AIも同様な結果になっています。
実例
著者たちは実例にSnapchatをあげています。このアプリにもGANの技術が応用されており、その1つに顔をより男性的に、または、女性的に変換する画像フィルター機能があります。ここまでの内容を読んだ方ならなんとなく推測はつきますよね。
皆さんが思い浮かべた通りです。女性的?とは肌が白いという偏りがこのフィルターにも見られると主張しています。実例についてはご紹介だけにしておきます。詳しく知りたい方は原著をお読みください。
まとめ
今回の結果からは使用方法に配慮することが重要だということに気付きます。例えば、男性と女性の割合を半々にすれば、ここまで悪影響はしないと思います。ただし、この考えは明らかに性別という差がわかるから言えることです。また、この合成データを学習に使えば、テストデータへの回答も偏ることが予想できます。今回で言えば、男性といっておけば80%分類できそうですし、さらに髪が長い時だけ、女性と答えることでかなり簡単に分類精度が上がったように見せることはできそうですね。
実例においてSnapchatが挙げられていますが、ただ単に遊びのツールとしてはいいと思います。しかし、こう言った技術が人の信頼を予測するようなAIに応用されたら怖くないですか?
例えば、データによっては男性より女性の方が信頼できる。逆もまた然り。こういたAIが容易に作り出されてしまいます。
また、著者たちも論文中に述べているように医療データへの応用はかなり影響があると言っています。例えば、少量なデータでのDAを行います。その生成データを用いて分類や検出モデルを構築しても、テストデータも多くはないため、偏っていると考えられます。そのため、テストデータの分け方や評価方法1つでいくらでも性能をあげているように見せることは可能です。
今後もっとGANの性質や特性がわかるようにこういた研究は続けていって欲しいですね。
ただし、これはGANはまだまだ発展途上であり、この論文の結果が全てではありません。
条件付きであればある程度の影響は抑えることは可能だと思いますし、論文中で引用された参考文献も特定のGANに対する研究です。全てのGANが評価されたわけではありません。GANの種類によっては変わるかもしれません。こう言った問題に対処するために分類というものに最適化させる3-player GANもあります。すなわち使い方を気をつけるべきは人であり、理論もわからず、雰囲気で使用せずに、AIにも得意・不得意があることを知ることが大切だと思います。



この記事に関するカテゴリー






