
カクカクした映像でもFPSを上げてぬるぬる動かせる!Depth-Aware Video Frame Interpolation
3つの要点
✔️深度情報を踏まえたビデオフレーム補間技術
✔️近傍ピクセルからコンテキスト情報収集
✔️計算量とモデル容量を削減しつつ、各種データセットでSoTAを達成
Depth-Aware Video Frame Interpolation
written by Wenbo Bao, Wei-Sheng Lai, Chao Ma, Xiaoyun Zhang, Zhiyong Gao, Ming-Hsuan Yang
(Submitted on 1 Apr 2019)subjects : Computer Vision and Pattern Recognition (cs.CV)
ビデオフレーム補間は長年に渡って研究が取り組まれてきており、最近のディープラーニングでも広範囲に研究されています。
以下の手法が今までにも行われてきました。
- CNNによって中間画像を直接合成する手法等→結果が不鮮明になることが多い。
- オプティカルフローを推定する手法→ぼやけが抑えられますが、動きが大きくなると移動量の推定が困難になる。
- AdaConvやSepConv等、補間カーネルを推定して、広い近傍から合成する手法→多大な計算量を消費します。
既存手法の共通の特徴として、深度情報を暗黙的に処理していましたが、提案手法では明示的に深度を推定し、遠いオブジェクトより近いオブジェクトを優先する中間状態の推定を行います。それに加えて、コンテキスト情報を学習して高品質画像合成を実現します。
アルゴリズムの概要
フレーム補完の目的は、入力フレームI0(x)とI1(x)が与えられた時、 時刻t (0<t<1) における中間フレームItを合成する事であり、提案手法もそれに準じます。
F0→1およびF1→0 のオプティカルフロー(時間的に連続するデジタル画像中で物体の動きをベクトルで表現したもの)を推定し、順方向または逆方向へ、同じ座標を通過するフローベクトルを集約する事で、中間フレームを合成します。
提案手法では、深度情報を考慮しながらフローベクトルを集約します。
Depth Aware Flow Projection
単純平均でフローを集約するのではなく、提案手法では深さを考慮します。
D0はI0の深度マップであると仮定します。
S(x)は時間tで位置xを通過するピクセルのセットを示します。
重みw0は深さの逆数です。
フロー Ft→0 は、次のように表され

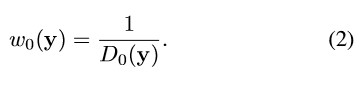
これは、近いオブジェクトの寄与を増やした投影フローとなります。
オプティカルフローからの計算では、フローが通らない座標がある場合があります。
そのような穴を埋めるために、周辺フローの平均値を利用します。
Video Frame Interpolation
アーキテクチャ全体を図に示します。
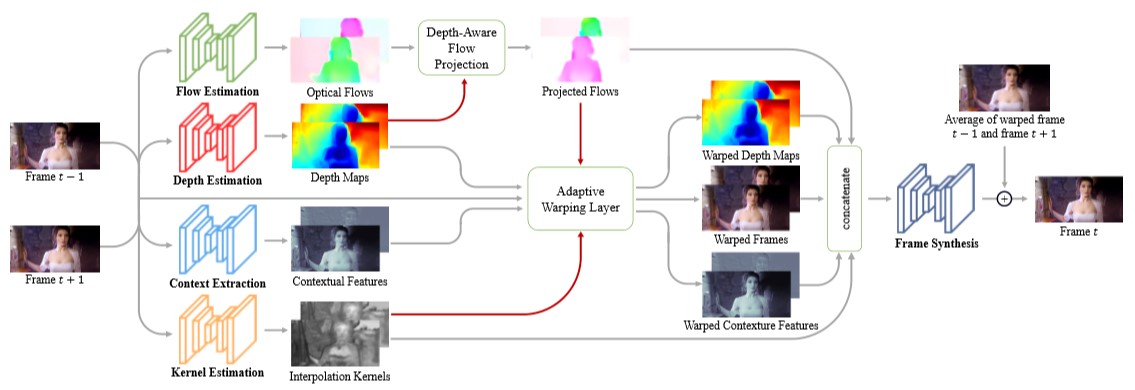
深度認識フロー投影レイヤーによって中間フローを推定し、入力フレーム、深度マップ、適応ワーピングレイヤー内のコンテキスト情報をワープします。最後に、フレーム合成ネットワークによって出力フレームを生成します。
Flow estimation.
フロー推定ネットワークとして、事前学習されたPWC-Netから初期化します。
Depth estimation.
事前学習済み砂時計アーキテクチャから初期化して深度推定ネットワークとして使用します
Context extraction.
図の設計でコンテキスト抽出ネットワークを構築し、ゼロから学習します。
Kernel estimation and adaptive warping layer.
ローカル補間カーネルは、大きな近傍からピクセルを合成するのに効果的です。適応ワーピング層は、ウィンドウ内で入力画像をサンプリングすることによりピクセルを合成します。
深度認識フロー投影レイヤーが生成した補間カーネルと中間フローを使用し、入力フレーム、深度マップ、コンテキスト情報をワープする適応ワーピングレイヤーを適応します。
Frame synthesis.
フレーム合成ネットワークは、ワープされた[入力フレーム、深度マップ、コンテキスト情報、投影フロー、補間カーネル]を、入力として受け取ります。3つの残差ブロックで構成される合成ネットワークであり、出力フレームをより鮮明に見せる事を重視しています。
Implementation Details
学習にはVimeo90Kデータセットを用います。
トレーニング用に、256×448ピクセルの解像度の51312個のフレームシーケンスを含みます。
開始時刻と終了時刻の中間フレームを予測するようにモデルは学習しますが、テスト時には任意の時刻を生成できます。
映像を上下左右に反転させ、時間も逆転させることによってデータを増強します。
Experimental Results
画像解像度が異なる複数のビデオデータセットで中間フレーム生成能力を評価します。
Vimeo90K、Middleburyベンチマーク、UCF101、HD videos
MiddleburyデータセットではIE(平均内挿誤差)とNIE(正規化内挿誤差)を計算します。この値が小さいほど高精度であることを示します。Vimeo90K、 UCF101、HDでは、 PSNR(ピーク信号対ノイズ比)とSSIM(構造的類似性)を計算します。


深度推定ネットワークをゼロから初期化し学習しているDA-Scraモデルは、深度推定ネットワークを持たないDA-Noneモデルよりも劣ります。
事前学習された深度推定モデルを利用するDA-Pretモデルは大幅な精度向上を示し、そこからさらに学習したDA-Optiモデルはさらに精度を改善します。

事前学習されたconv1(PCF)
学習されたconv1(LCF)
学習された階層的機能(LHF)
深度マップ(D)
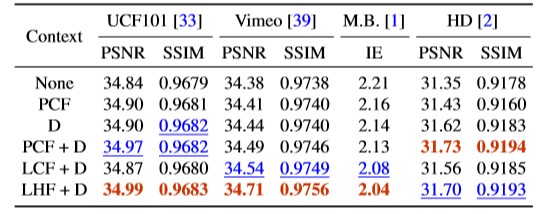
コンテキスト情報を使用しないと、うまく画像を作れず、ぼやけた結果が生成されます。コンテキスト機能を導入することにより、パフォーマンスは大幅に向上します。学習した階層機能が、Vimeo90KおよびMiddleburyデータセットの大幅な改善につながることを実証します。深度マップと階層機能の両方を使用するモデルは、より鮮明で明確なコンテンツも生成します。
まとめ
深度情報を明示的に利用して、オブジェクトの前後関係を検出する、新しいビデオフレーム補間アルゴリズムを提案しました。
提案モデルはコンパクトで効率的です。
多様なデータセットでの評価によると、提案手法が既存のフレーム補間アルゴリズムに対して良好に機能することを示しています。
すでにこの技術はDain-Appと言うソフトウェアに使われております。特に下の動画で34sからの羽の動きはかなり滑らかになっていることがわかります。



この記事に関するカテゴリー






