AIには解けない「もっと難しい」QAデータセットが登場
機械による自然言語の理解を目指し、文書読解(Reading Comprehension/RC)や質問応答(Question Answering/QA)といったタスクにおける研究が盛んに行われています。データセットでの正答率を上げることで、こうした能力を学習できるモデルを作成することを目的としていますが、既存の文書読解データセットであるSQuADなどでは、ニューラルネットワークを用いた手法が九割近い正答率(執筆現在)を達成しており、既に「やり尽くされた」タスクになってしまっています。
文書読解分野のさらなる成長を促すために本研究では、現在の手法ではなかなか解けないような問題を多く含むデータセット「DROP」が新たに公開されています。本データセットは人間の正答率が96.4%であるのに対し、様々なタスクで性能が良いと話題のBERTでもその正答率が32.7%と、機械にとって難しいデータセットになっています。
論文:DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
データセット:https://allennlp.org/drop
新たなデータセットの必要性
文書読解または質問応答は、パラグラフとそれに関する質問が与えられ正しい回答が選択できるかを評価するタスクです。文書読解タスクではSQuADというデータセットがベンチマークとして広く用いられています。発表から現在まで、SQuADにおける正答率の向上を目指し様々なモデルが提案されており、最も正答率が高いものは記事執筆現在で89.474%(F1値)となっています(スコア一覧はこちらで確認できます)。SQuADを人間が解いた時の正答率は89.452%であるため、既に機械が人間のパフォーマンスを超えている状態です。
一方でSQuADに含まれる問題は、その答えがパラグラフ内にズバリ書いてあるなど比較的な簡単なものが多いと言えます。機械の性能が人間の正答率を超えた今、簡単なデータセットで性能を争うような研究では文書読解を達成するという目標に近づくことができません。
そこで現在のモデルでは解くことが難しいデータセットを作ることで、さらなる技術の発展を促す必要があります。具体的には、パラグラフ全体にまたがる情報(Discrete Reasoning Over the text in the Paragraph)を理解していなければ解けないような問題に焦点を当てたデータセットが求められています。
例えば「A君が170cm、B君が165cm、C君は180cm」というような、数値的な情報が述べられた文章に対して「最も身長が高いのは誰ですか?」といった質問をしたとき、現在のモデルは正しく正解を選ぶことができません。これは文章の中での事実関係を正しく捉えることができないだけでなく、現在のニューラルネットワークを用いた手法では数値の比較や演算をうまく扱うことができないことに起因しています。もちろんこうした問題は人間であれば容易に正解することができるため、機械の文書読解能力が人間に及んでいないことを示した問題ということができます。逆にこのような問題を機械が解けるようになれば、この内容に関しては機械の読解能力が人間レベルに達したということができます。本論文では、こうした「人間に解けるが機械には解けない」問題を多く含んだデータセットを作成することを目的としています。
SQuAD論文:Know What You Don’t Know: Unanswerable Questions for SQuAD
どのようなデータセットか
作成方法
本研究ではWikipediaを用いてデータセットを作成しています。難しい問題を作る上で、数値情報や時系列情報を問題に織り込むことが重要であるため、こうした情報を多く含む事件状況や人物の経歴などの記事を重点的に収集しています。今回のデータセットでは、主にフットボールに関する記事や歴史に関する記事を重点的に抽出し、加えて数字を最低20個含む記事を抽出しました。
ベースラインモデルでの評価
上記の手順で作成されたデータセットを、既存の手法でどの程度解くことができるのかを下表で示しています。人間が解いた時の精度がテストセットの完全一致率(Exact Match/EM)で94.09%であるのに対し、これまで提案されてきたQAの手法(SQuAD-style RC)は30%に満たないなど、非常に難しいデータセットになっていることがわかります。
さらにデータセットを作った本人である筆者が、このデータセットの特徴を踏まえて作成したモデル(NAQANet)であっても44.07%の正答率となっており、50%に満たない正解率であることがわかります。しかし、このデータセットに関する論文が出た時は人間と機械の間に50%程度の開きがあったのに対し、もう既に7月現在で、差は32.5%程まで縮んでいます。今後はこの差を埋められるような手法が提案されていくと期待できます
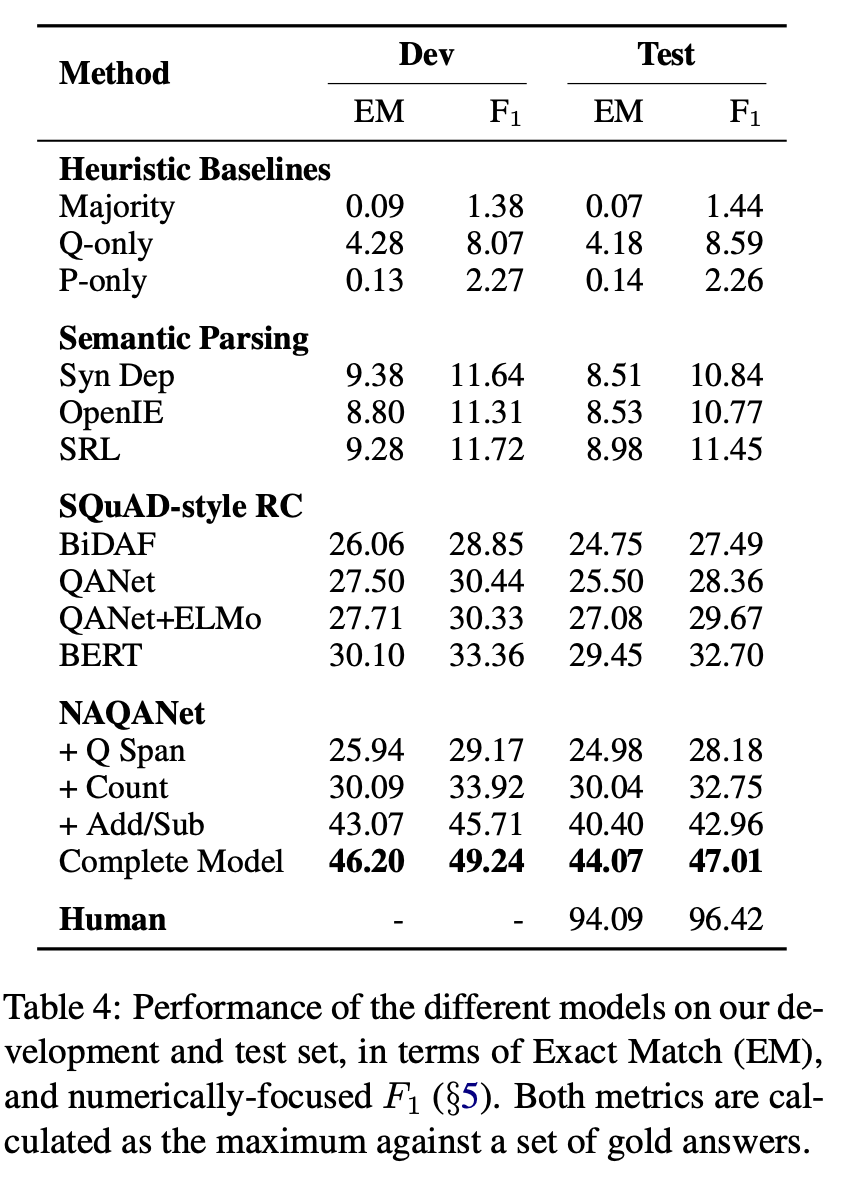
データセットの構成
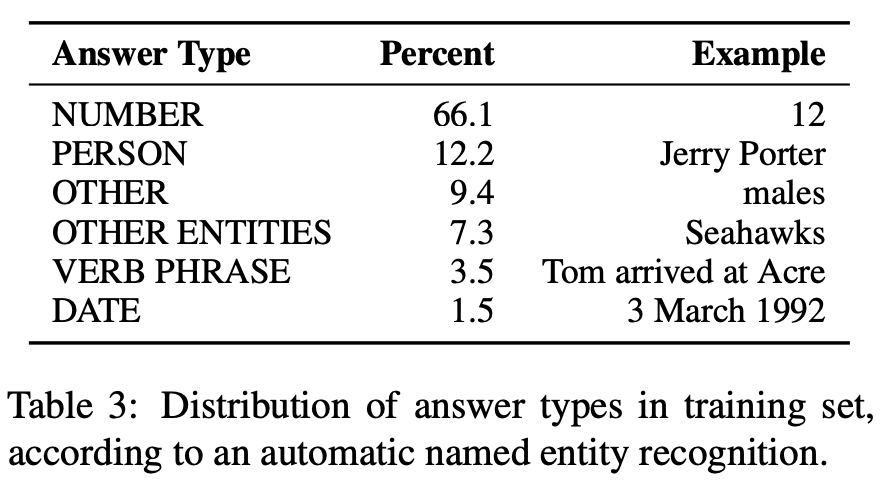
最後にデータセットの解答タイプと問題形式についての情報を確認します。
下表は、データセットに含まれる問題に対する正解の種類を表しています。表より、66.1%と高い割合で数値が答えとなるような問題が含まれていることがわかります。これはデータセットを作成する際に、試合や人物の時系列情報を用いていることや、既存手法であるBiDAFが解くことができない問題を多く作成しているためです。このことから、本データセットは数値を上手く扱えるようなモデルを作成することができれば、半分以上の問題が解けるといえます。
以下のグラフは(a)回答を文章からから抜き出すタイプの問題、(b)数値を回答するタイプの問題について、問題の書き出しの割合を示しています。(a)の問題では、who・what・whichという主要な疑問詞がバランスよく含まれており、(b)ではhow manyという書き出しに続いて、yeards・pointsといった計算を求めるような問題が多く含まれていることがわかります。データセットにフットボールに関する記事を用いているため、fieldやyards、pointsといった単語にその影響を見ることができます。外部知識を用いて本データセットに取り組む際に、スポーツなどのドメインが近い記事を用いることで性能の向上があると考えられます。

(クリックで拡大できます)
まとめ
本研究では、これまでの文書読解で用いられてきたデータセットに比べて「人間が解けるのに機械が解けない問題」に特化したデータセットになっています。特に現在のモデルでは解き難い「数字を扱う問題」や「パラグラフ全体にまたがる情報を用いて解く問題」が多く含まれており、こうした問題をどのように取り扱うかが本データセットの正答率をあげる鍵となります。このような問題はチャットボットでトーク履歴を用いた質問応答を行うなどの、実際に自然言語処理を応用する場においても付きまといます。製品の質問応答モデルの性能をあげるためのステップとして、本データセットに取り組んでみてはいかがでしょうか。




この記事に関するカテゴリー






