コスト指標は必ずしも適切か?
3つの要点
✔️ 様々なコスト指標の長所と短所について議論
✔️ コスト指標間で矛盾が発生する場合について議論
✔️ コスト指標を用いた比較が公平でなくなる場合について議論
The Efficiency Misnomer
written by Mostafa Dehghani, Anurag Arnab, Lucas Beyer, Ashish Vaswani, Yi Tay
(Submitted on 25 Oct 2021 (v1), last revised 16 Mar 2022 (this version, v2))
Comments: ICLR2022
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
機械学習モデルの効率(efficiency)は、モデルの開発・利用における非常に重要な要素です。
例えば推論にかかるコストは、実際にそのモデルを利用する上での使いやすさや利用可能なハードウェアの制限に直結します。モデルの学習時にかかるコストによる経済的・環境的影響も考慮すべき重要な点でしょう。そのため、学習するパラメータの数、浮動小数点演算数(FLOPs)、速度/スループットなど、モデルの効率に関する指標は数多く存在しています。
ですが、これらの効率に関する指標全てが網羅されているわけではなく、例えばパラメータ数とFLOPsのみなど、一部の指標のみが報告される場合も多く存在します。しかし、モデル効率に関する指標のうち一部のみに基づいてモデル効率を判断することは適切であると言えるでしょうか。
本記事では、一般的に用いられるモデルコストの指標の長所と短所、一部の指標に基づく判断のリスクなど、この問題について様々な調査を行った研究について紹介します。
コスト指標について
はじめに、機械学習モデルの効率に関する様々なコスト指標について紹介します。
・FLOPs
FLOPsは、モデルの計算コストの代理としてよく用いられている指標であり、浮動小数点の乗算・加算演算の数(number of floating-point operations)を示しています。なお、コンピュータの処理速度の指標として用いられるFLOPS(FLoating-point Operations Per Second)とは別の指標です。
論文で報告されるFLOPsは理論値により計算されており、これはモデルのどの処理を並列化できるかなど、実用的な要素は無視されていることに注意が必要です。
・パラメータ数(Number of Parameters)
学習可能のパラメータ数は、計算量の間接的な指標として用いられています。スケーリング則(Scaling Law)に関する多くの研究、特にNLP領域では、主要なコスト指標としてパラメータ数が利用されています。
・速度(Speed)
速度は、異なるモデルの効率を比較するための最も有益な指標の一つです。速度測定の際には、実際の設定を反映するために、パイプラインのコストを考慮する場合もあります。
当然ながら、速度は使用するハードウェアや実装に依存するため、比較にはハードウェアを固定するか、使用するリソースに基づく正規化が重要となります。
報告される速度指標には、以下のようないくつかの形式が存在します。
- Throughput:特定の時間内に処理された例またはトークンの数("examples per second"または"tokens per second")。
- Latency:ある例または例のバッチを与えられたモデルの推論時間("seconds per forward pass")。バッチ処理により生じる並列性が無視されるため、ユーザーの入力が必要なリアルタイムシステム等で重要な要素となります。
- Wall-clock time/runtime:一定の例のセットをモデルが処理するのにかかった時間。モデルが収束するまでの総トレーニング時間など、トレーニングコストの測定によく利用されます。
- Pipeline bubble:各バッチの開始時と終了時にコンピュータデバイスがアイドル状態になっている時間。プロセスの非パイプライン部分の速度の間接的な指標となります。
- Memory Access Cost:メモリアクセスの回数。通常はランタイムの大部分を占めており、GPUやTPUなどでモデルを実行する際の実際のボトルネックとなります。
これらのコスト指標は、モデル効率の様々な側面を反映しています。
ただし、これらの指標は必ずしもモデル設計に固有ではなく、モデルが動作するハードウェアや、実装されているフレームワーク、プログラミングスキルなどの様々な要因に依存しています。
例えばFLOPsはハードウェアに依存しないものの、必ずしもモデルの速度に結びつくとは限りません。
一方、実際の環境でのモデル効率をよりよく反映しているスループットやメモリ使用量は、ハードウェアや実装に大きく依存しています。このように、それぞれのコスト指標が異なる要因に依存していることが、比較の難しさに繋がっていると言えます。以降では、パラメータ数、FLOPs、速度に焦点を当てて、モデルの効率の指標について議論を進めていきます。
コスト指標間の不一致の可能性
次に、先述したコスト指標の間に不一致が生じる可能性がある場合について説明します。
パラメータの共有
パラメータの共有を行うモデルの場合、パラメータを共有しないモデルと比べて、FLOPsや速度が変わらないまま、学習可能なパラメータ数が少なくなってしまいます。
例えば、パラメータの共有を行うUniversal TransformerとバニラTransformer等の比較を行った場合は以下のようになります。
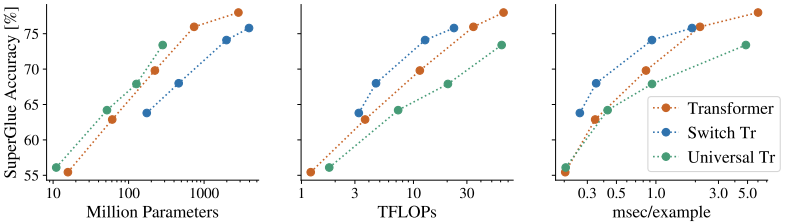
パラメータ数のみ(図の左)を見た場合、Universal Transformerは他モデルと比べて効率的に見えます。しかし、FLOPsやスループット(図の中央・右)を見ると、Universal Transformerの相対的な順位は下がっています。このように、パラメータの共有を行うモデルでは、パラメータ数はコスト指標として有効ではありません。
スパース性の導入
スパース性(Sparsity)をニューラルネットワークに導入する場合にも、コスト指標の不一致が生じることがあります。
例えばMixture of Experts (MoE)のように、入力例に応じてニューラルネットワーク内の異なる重みの部分集合を利用する場合、パラメータ数が非常に大きくなりますが、品質に対するFLOPsは改善することができます。また、演算に多くのゼロ(またはゼロに近い値)が含まれるようにした(スパース化)モデルでは、FLOPsを大幅に削減することができます。
先程の図では、MoEを利用したSwitch transformerの場合が示されており、品質に対するパラメータ数は好ましくありませんが、品質とFLOPs、速度の比較では非常に良好な結果を示しています。
また、スパースなモデルは理論上のFLOPsの大きな削減に繋がりますが、速度の大幅な上昇には繋がりにくい点に注意が必要です。
例えばMoEでは、モデルのどの部分を利用するかというルーティング部分やバッチ処理の効果的な使用が難しい等の理由により、追加のオーバーヘッドが生じます。また、演算に多くのゼロが含まれるようにしたモデルの場合でも、メモリアクセスに大幅なコストがかかるため、低レベル演算処理の効率を対応する密な計算と同等にすることはできません。
並列化の度合い:モデルの深さと幅のスケーリングの比較
モデルサイズを変更したい場合、最もシンプルなのはモデルの深さ(層の数)と幅(隠れ次元数)を変更することです。
ここで、実際にVision Transformerの深さ(D)と幅(W)を変更した場合、様々なコスト指標とモデル精度がどのように変化するかを調査した場合は以下のようになります。
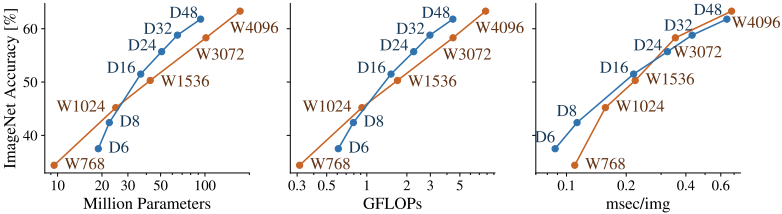
この図では、パラメータ数とFLOPsから考えると、低コスト領域では幅を、高コスト領域では深さを大きくするほうが、より少ないコストで性能を高めることができると判断できます。
しかし、速度(msec/img)では異なる傾向が見られます。
例えば、W3072とD48を比較すると、FLOPsやパラメータ数から判断すると、D48の方が同等のコストで明らかに優れた性能を示しているように見えます。
しかし、速度を比較した場合、(並列処理が多くなるため)W3072はD48と比べて明らかに悪いと判断することはできません。このように、並列化の度合いの違いに伴い、コスト指標間で一致しない結果が得られる場合が存在します。
対象プラットフォームと実装
ハードウェアや実装によっても、コスト指標の不一致が生じる場合があります。
例えば、モデルコストを削減する手法を導入した場合に、GPUとTPUで速度効率の改善度が異なることがあります。また、ViTにおいてCLSの代わりにグローバル平均プーリングを行うことでTPU-V3のメモリコストを大幅に削減することができますが、これはTPUの仕様によるものです。このように、ハードウェアや実装が、モデルのコスト指標に影響を及ぼす場合も存在します。
考察
機械学習コミュニケーションにおいて、コスト指標は主に以下のような目的に用いられます。
- コスト指標を利用して、異なるモデルの効率を比較する。
- 同一のコスト設定で、異なるモデルの品質を比較する。
- (NASなどで)品質とコストの適切なトレードオフとなるモデルを選択する。
こうした目的にコスト指標を用いることは、時に正確でない結論に繋がる可能性があります。
異なるモデルの効率比較
まず、(1)コスト指標により異なるモデルの効率を比較る場合すについて考えます。
次の図では、異なるモデルのFLOPs、パラメータ数、実行時間、精度を比較した場合が示されています。
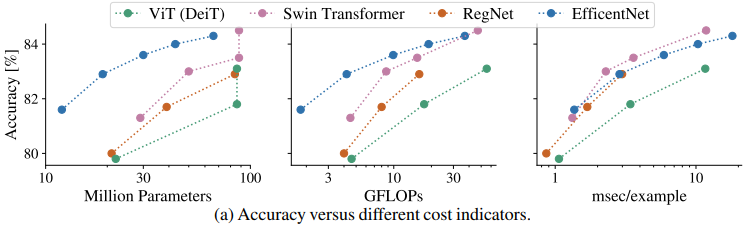
これらのモデル精度-コスト指標の関係を見ると、各モデルの相対的な関係はコスト指標によって異なります。
例えばパラメータ数やFLOPsを見た場合、EfficientNetsが良好なトレードオフを示しています。しかし、精度-スループットのグラフでは、SwinTransformerの方が優れているように見えます。
このように、どのコスト指標により比較するかで最適なモデルが異なってしまう場合が存在します。また、コスト指標間の相関関係を示すプロットは以下のようになります。
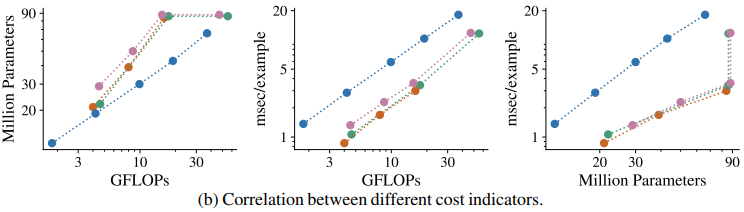
この図を見ると、FLOPsを固定した場合、EfficientNetは他のモデルと比べてモデルパラメータ数が少なく抑えられています。
一方、FLOPsに対するスループットを見ると、EfficientNetは他のモデルと比べてスループットが劣っていることがわかります。また、Transformerベースのモデルでは、パラメータ数が同一でも、その他の指標が大きく変化しています。
これは、モデルの入力解像度が変更され(224×224→384×384)、エンコーダへの入力トークン数が異なることに起因しています。逆に言えば、モデル設定の変更が、一部のコスト指標にのみ大きな影響を与える場合がある、ということがわかります。
異なるモデルの品質比較
次に、(2)同一のコスト設定で、異なるモデルの品質を比較する場合について考えます。
このとき、モデルのパラメータ数を同一にして比較する場合と、FLOPs等の計算コストを同一にして比較する場合の二パターンが主に用いられるため、順番に取り上げていきます。
パラメータ数を同一にして比較する場合の問題点
まず、パラメータ数を同一にしてモデルの比較を行う場合の潜在的な問題点について検討します。
・トークンフリーモデル
トークンフリーモデルでは、トークンレベルではなく、文字やバイトレベルでのモデリングを行います。
この場合、埋め込み行列に由来する多くのパラメータが削除されることになるため、非トークンフリーモデルとの公平な比較が非常に困難となります。
・スパースモデルとMixture-of-Expert
先述の通り、スパース性を利用するモデルでは、パラメータ数を同一にしてモデル比較を行うことは明らかに不公平となります。
先程の例では、同一パラメータ設定でSwitch TransformerとバニラTransformerを比較すれば、常にバニラTransformerの方が有利になってしまいます。
・ビジョントランスフォーマーとシーケンス長
Vision Transformerのように、シーケンスの長さを変更することができるモデルでは、同一のパラメータ数でも計算コスト(FLOPsや速度)が大きく異なるアーキテクチャを作成することができます。そのため、このタイプのモデルをパラメータ数で比較するべきではありません。
例えば以下の表では、パッチサイズ(シーケンス長)が異なる場合のViTのコスト指標が示されています。

表の通り、モデルによってはパラメータ数が同一でもその他の指標が大きく変化する場合が存在します。
計算コストを同一にして比較する場合の問題点
一方、計算コストを同一にしてモデルを比較する場合にも問題が生じる場合があります。
例えば、提案手法がモデルのパラメータ数に影響を与えない形で計算量を削減している場合について考えます。このとき、ベースラインと比較を行いたい場合に、計算量が一致するまでベースラインの層や隠れ次元数を削減することが考えられます。
しかしこの場合、ベースラインは単純なパラメータ数の削減により、モデルの容量が大幅に不足するハンディキャップを負うことになります。
例えばPerceiver IOでは、ベースラインBERTは計算量マッチ比較において、パラメータ数が20M、層数は6まで縮小されています。なお、比較の対象となった提案手法のパラメータ数は最大で425M、層数は40です。総じて、計算量のマッチングによる比較を公正に行うことは自明ではなく、困難な問題であるといえます。
公正な比較を簡単に行うことができない場合には、最適な比較設定を見つけるために最善な努力をし、可能であれば複数の候補を示すことが勧められます。
NASにおけるコスト指標
NASでは、モデルリソースの制約として、損失関数にコスト指標を追加することが多いです。
例えばパラメータ数、FLOPs、メモリアクセスコスト、実レイテンシーなどが用いられます。これまでに示されたとおり、コスト指標は互いに異なる結論に繋がる可能性もあるため、アーキテクチャ探索時のコスト指標の選択には細心の注意が必要です。
まとめ
本記事では、様々なコスト指標の長所や短所や、コスト指標間での相違が発生する場合などについて広範な議論を行った論文について紹介しました。
最近の研究では、パラメータ数やFLOPsなどのコスト指標に基づき異なるモデルの比較を行うことがよくあります。
しかし、各指標には様々な長所や短所があり、公平な評価に用いることが難しい場合も存在します。そのため、利用可能な全てのコスト指標を用いて比較を行うべきであると言えるでしょう。



この記事に関するカテゴリー






