言語モデルは非言語概念空間にgroundingできるか?
3つの要点
✔️ 言語モデルは少数の例のみで実世界に近い概念空間へのgroundingを行うことができるか?
✔️ グリッド上の二次元空間や三次元色空間と、言語空間とのマッピングを学習できるかを検証
✔️ GPT-3でランダムでないある程度の精度を達成
Mapping Language Models to Grounded Conceptual Spaces
written by Roma Patel, Ellie Pavlick
(Submitted on 29 Sep 2021)
Comments: ICLR2022
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
GPT-3などの大規模な事前学習済みの言語モデルは、様々な自然言語タスクで優れた結果を示しています。
このようなモデルは、質問への回答や流暢な文の生成に加え、物理的に観察したことのない物体、特性について推論する能力などから、言語空間内の概念の構造をよく把握していることがわかります。
この記事では、テキストデータのみで学習した言語モデルが、例えば実世界の空間情報のような概念空間へのgroundingを学習することができるのか、という疑問に取り組んだチャレンジングな研究について紹介します。(この論文はICLR2022にAccept(Poster)されています。)
実験設定
モデル
実験にはGPT-2、GPT-3モデルを利用します。パラメータ数は124M,355M,774M,1.5B,175Bからなります。また、これらのモデルのパラメータを更新するのではなく、少数の例を与えることで動作を制御します。
より具体的には、質問文が"World:~~"、回答が"Answer:~~"のような形式のタスク例をモデルに与えた後、新しい質問文と"Answer:"というデータをモデルに与えることで、質問に対する回答を生成させることができます(これはin-context learningまたはfew-shot promptingと呼ばれています)。
groundingされた概念領域(Grounded concept domain)
実験では、次の図で示されるように、二次元空間での方向やRGB空間内での色など、実世界につながる(groundingされた)概念に関連する三つの問題について取り上げます。

それぞれの説明は次の通りです。
Spatial Terms
この問題では、6つの空間概念(left, right, up, down, top, bottom)について考えます。具体的には、複数の"0"と一つの"1"をグリッド状に並べて二次元空間を表現したものを質問("World:~")として言語モデルに与え、"1"がどの場所にあるかを言語モデルに回答させます。
Cardinal Directions
このタスクでは、東西南北とその間の8方位をグリッド二次元空間で表現します。
Spatial Termsと似ていますが、"northeast"のようなcompositional terms(複合語?)を含んでいるという違いがあります。
RGB Colours
色の名前(red,cyan,forest greenなど)をRGBコードで表現した、RGB367色のデータセットを利用し、3次元空間での色の表現について考えます。
例えば、"RGB:(255,0,0)"が質問として与えられれば、回答として"Answer:red"が正解となります。
ただし、実験に用いる言語モデル(GPT-x)はCommonCrawlコーパスで学習されているため、事前学習時にこれらのドメインに遭遇している可能性があります。
例えば、(255,0,0)と"red"を対応させている表などは、インターネット上に多く存在しているでしょう。
このようなデータを単純に記憶したのみでモデルが成功することを避けるため、上述したタスクに追加の回転処理を行います。
例えば、RGBカラードメインでの回転例は以下の通りです。

言語モデルが空間内の概念(この例では色)間の構造関係を把握できていれば、空間構造が壊れない回転処理がなされてもタスクを解決できるはずです。
逆に、空間内の概念をランダムに割り当てた場合、性能はランダムレベルにまで低下するはずです。実験では、オリジナルの世界に加え、90°、180°、270°回転した世界、ランダムな世界についてモデルの評価を行います。
モデルが望ましい形で概念のマッピングに成功していれば、オリジナル・回転した世界では高い性能が、ランダムな世界では低い性能が得られることが予想されます。
評価指標は以下の通りです。
- Top-1 Accuracy:生成された回答の最初の$n$個のトークンの中に、ground truthまたはその部分文字(単語)列がある場合に精度は1となります。例えば、ground truthが"deep tuscan red"の場合、モデルの回答が"tuscan red"や"red"では1の精度が、"deep red"や"wine"や"vermilion"では0の精度が得られます。元論文の付録では、部分一致ではなく完全一致のみで精度を計算した場合の実験も行われています。
- Top-3 Accuracy:モデルの1~3番目に確率が高い回答シーケンスの三つのいずれかに正解が存在すれば1の精度が得られます。
- グラウンディング距離(Grounding Distance):モデルの誤りの度合いを評価するために用います。モデルが生成した回答がドメイン内の単語(例えば色ドメインならば"pink"など)であれば、その空間内の二点間のユークリッド距離を評価に利用します。回答がドメイン外であれば、非常に大きい値をこの指標の値として設定します。
グラウンディング距離について、ground truthと予測結果に対するこの指標の結果の例は以下のようになります。

この表では、GPT-3モデルの実際の予測結果が示されています。例えば、ground truthが"dark red"のときに"wine"が予測された場合、グラウンディング距離は76.5と求められます。
ベースライン
ベースラインとして、以下の二つのランダムベースラインを設定します。
- R-IV(Random In-Vocabulary):モデルの全語彙の中からランダムなトークンを選択します。(当然ながら、全てのタスクでほぼゼロの性能を示します。)
- R-ID(Random In-Domain):ドメイン内の単語(例えば色など)をランダムに選択します。
実験結果
未見世界への一般化能力について
三つのタスクのうち、Spatial Terms・Cardinal Directionsについて実験を行います。モデルに与える入力例は以下のようなものとなります。
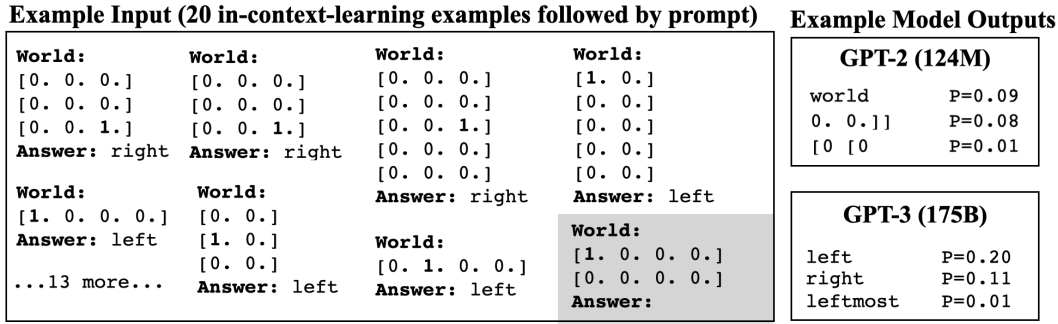
ここで、評価時に各タスクに含まれる概念(方向や方位)は、モデルに事前に与えるデータの中に全て含まれています。つまり、学習時に"right"と"left"のみが登場していたにも関わらず、評価時には"up"や"down"も登場する、といったことはありません。データは八方位または上下・左右のペアからなる概念について、20個の例がモデルに与えられます。
結果は以下の通りです。
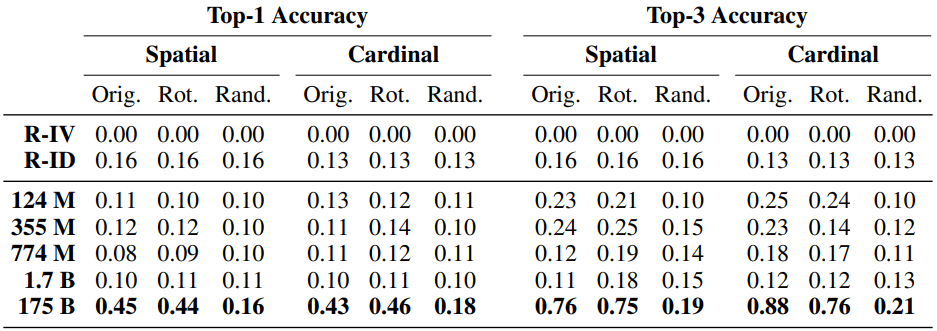
パラメータ数が最大のモデル(GPT-3)では、オリジナル・回転された世界の両方で、top-1精度0.45程度の性能を示しており、ランダムな世界では性能が低下しています。これは、精度は高くはないものの望ましい結果であり、モデルはある程度、二次元空間への一般化に成功していると言えるでしょう。
一方、それ以外のモデルについては、R-ID設定をも下回る性能となっており、学習にほぼ失敗しているといえます。
未見の概念への一般化能力について
次に、RGB Coloursを含めたタスクについて実験を行います。このとき、モデルに与える入力例は以下のようなものとなります。

ここで、評価時に各タスクに含まれる概念(方向や方位や色)の中には、モデルに事前に与えるデータの中に含まれていないものが存在します。つまり、学習時に"right"と"left"のみが登場し、評価時に"up"や"down"が登場する、といった場合が発生します。
より具体的には、Spatial Terms・Cardinal Directionsについては、事前に20例与えられるデータは、$n-1$個の概念を含んでおり、評価時には残りの一つが含まれるデータが利用されます。
RGB Coloursでは概念数が多いため、事前に与えられるデータには60の例が与えられています。
結果は以下の通りです。
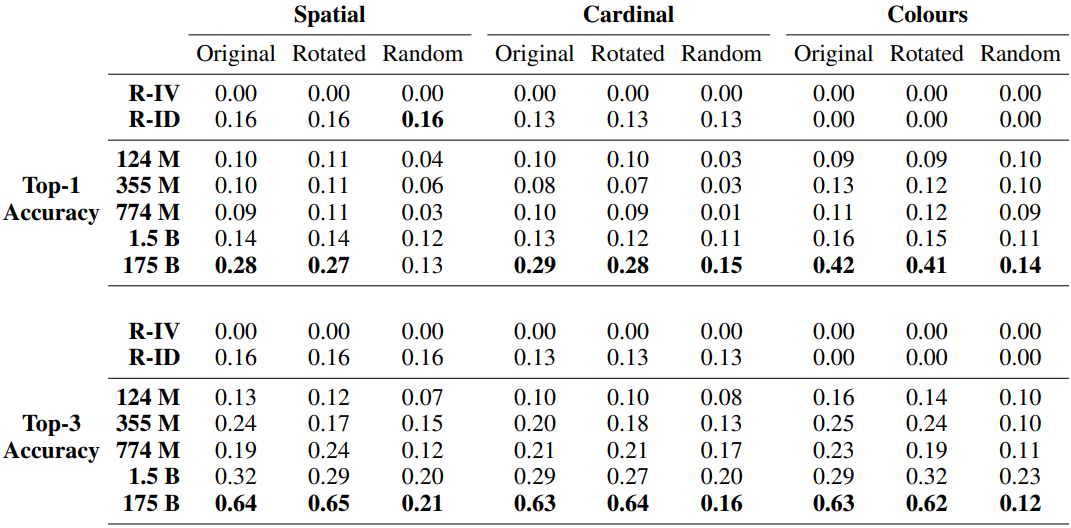
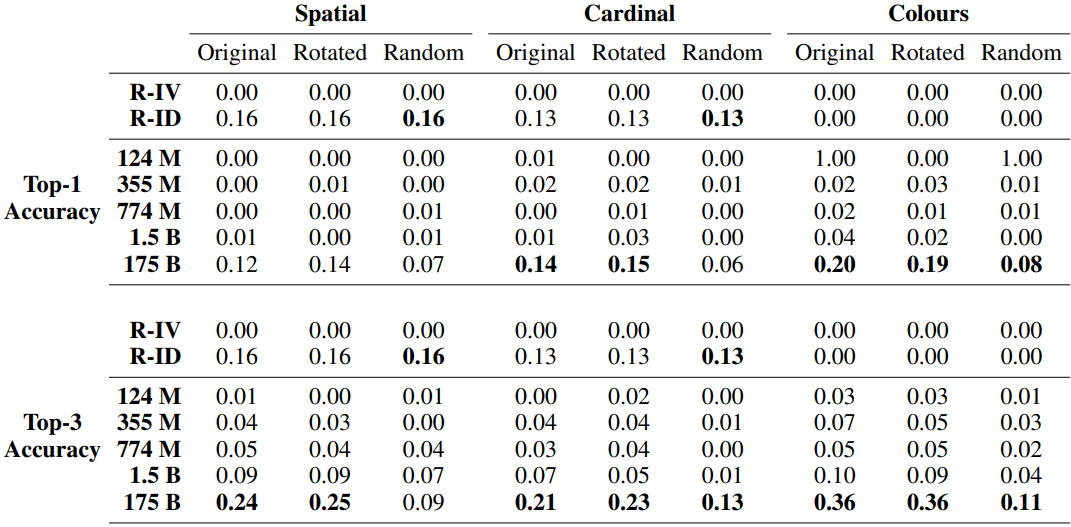
先程と同じく、パラメータ数が最大のモデル(GPT-3)では、ランダム以上の性能が得られました。特にRGB Coloursタスクでは、タスクの難易度に反して40%以上のTop-1精度を示しており、望ましい結果が得られたと言えます。なお、部分一致ではなく完全一致のみでTop-1、Top-3精度を計算した場合の結果は以下のようになります。
また、RGB Coloursタスクについて、平均グラウンディング距離を求めた結果は以下のようになります。
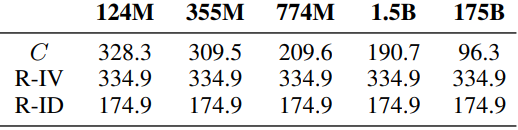
最大のモデルでは、ランダムと比べて有意に良好な結果が得られています(数値は小さいほど良い)。また、モデルの予測結果がそのドメイン内の概念であるか(例えばCardinal Directionsタスクならば八方位のどれかが生成されたか)についての調査では、最小のモデルは53%、最大のモデルでは98%がドメイン内の回答が得られていました。
まとめ
この記事では、テキストデータのみで学習された言語モデルが、三次元色空間や二次元空間のような(実世界に近い)概念空間へのグラウンディングを行うことができるかについて取り組んだ、groundingに関連する非常に興味深い問題を取り扱っている研究について紹介しました。
実験の結果、非常に多くのパラメータを持つGPT-3では、この試みにある程度成功しました。
この結果は、テキストのみで学習された言語モデルが、ごくわずかな例により、言語空間と異なる概念空間へのマッピングあるいはグラウンディングに成功できるかもしれないという興味深い可能性を示唆しているかもしれません。





この記事に関するカテゴリー






