チャート要約のための大規模ベンチマーク、Chart-to-textが登場!
3つの要点
✔️ 2つのデータセットと44096枚のチャートからなる大規模ベンチマーク、Chart-to-textを構築
✔️ 本データセットと最新のニューラルネットワークモデルを用いてベースラインを作成
✔️ ベースラインに対して評価指標と人間による評価を行った結果、自然な要約を生成し、妥当なBLEUスコアを達成した
Chart-to-Text: A Large-Scale Benchmark for Chart Summarization
written by Shankar Kantharaj, Rixie Tiffany Ko Leong, Xiang Lin, Ahmed Masry, Megh Thakkar, Enamul Hoque, Shafiq Joty
(Submitted on 12 Mar 2022 (v1), last revised 14 Apr 2022 (this version, v3))
Comments: ACL 2022
Subjects: Computation and Language (cs.CL)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
棒グラフ、折れ線グラフ、円グラフなどのデータビジュアライゼーションは定量的なデータを分析するために必要不可欠であり、チャートから自然言語による要約を行うAutomatic chart summarizationは図表から人々が重要な洞察を得ることを補助する重要なタスクになります。
しかし、このチャート要約タスクは、主に以下の2つの問題によりこれまであまり注目されてきませんでした。
- 最新のニューラルネットワークモデルを用いて本タスクを行うための大規模なデータセットがない
- 最新のニューラルネットワークモデルを用いた本タスクにおける強力なベースラインが存在しない
本稿では、上記の問題を解決するために、44096枚の幅広いトピックと様々な種類のチャートからなる2つのデータセットを用いてチャート要約タスクの大規模ベンチマークを構築し、最新のニューラルネットワークモデルを用いてベースラインを作成した論文について解説します。
Chart-to-text Dataset
本論文では、以下の手順でデータセットを構築しました。
データ収集
ニュースサイト、教科書、ウェブサイトなどの様々なソースを検索した結果、以下の2つの十分な数と種類のテキストでの説明付きのチャートを持つソースを見つけることができました。
- Statista: 経済・市場・世論調査など幅広いトピックに関するチャートを定期的に公開しているオンラインプラットフォームであり、2020年12月に公開された34810枚のウェブページから合計34811件のチャートを取得した
- The Pew Research: 社会問題・世論・人口変動の傾向に関するデータの記事を発行しているウェブサイトであり、2021年1月に公開された3999枚のWebページから合計9285枚のチャートを取得した
取得した各チャートについて、画像・周辺のパラグラフ・関連するテキストをダウンロードし、手作業で各チャートを単純なものと複雑なものに分類しました。
データアノテーション
収集した2つのウェブサイトの各チャートに対して、その要約文のアノテーションを行いました。
Statistaから取得したチャートに関しては、「チャートに付属するテキストにおいて、その最初の文はチャートの簡潔な要約を記述し、残りの部分は背景情報(歴史など)を含むことが多い」という推測に基づき、チャートに付属するテキストの最初の部分をチャートの要約文としてアノテーションを行いました。
一方、The Pew Researchではウェブページ内に多くのチャートが含まれるため、単純にチャートに付属するテキストを取得することが困難という問題点があったため、下図の手順でアノテーションを行いました。

- state-of-the-artのOCRモデルであるCRAFTを用いてチャートからテキストを検出
- 検出されたテキストを勾配ブースティングによりタイトル・軸ラベル・凡例・データラベルのいずれかのカテゴリに分類
- 各チャートと関連するパラグラフに対してアノテーションを行う
データセットの解析
下の表に示すように、作成されたデータセットには棒グラフ(Bar)や折れ線グラフ(Line)などの様々な種類チャートが含まれており、政治(Economy&Politics)・社会(Society)・健康(Health)などの幅広いトピックをカバーしていることが分かります。
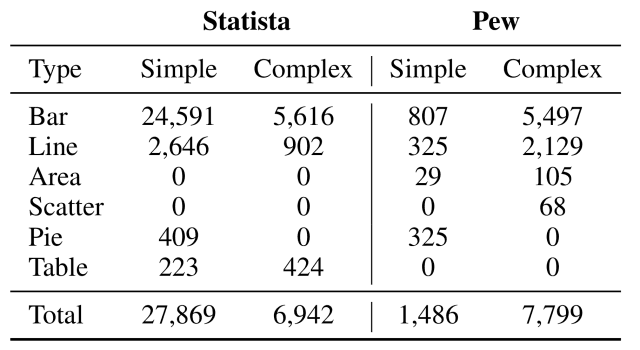
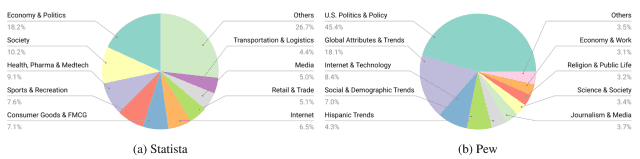
Chart-to-text Baseline Models
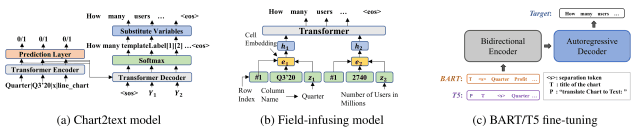
本論文では、下図の3つのモデルを用いてベースラインモデルを作成しました。
-
Chart2text model(Obeid and Hoque, 2020): Gon et al.(2019)のdata-to-textモデルに基づき、chart-to-text用に変更したTransformerモデル
-
Field-infusing model(Chen et al., 2020): concept-to-text work(Lebret et al., 2016)を基に作成されたモデル
- BART(Lewis et al., 2020): ノイズ除去の事前学習を目的としたseq2seq Transformerアーキテクチャを採用したモデルで、テキスト生成タスクのために事前学習されている
- T5(Raffel et al., 2020): 様々なNLPタスクをtext2textに変換する統一的なseq2seq Transformerモデル
入力に関してデータテーブルがある場合はそれをそのまま使用し、ない場合は全てのOCRテキストを上から下へ順番に連結したものを入力としてモデルに与えています。
Chart-to-text Evaluation
最後に、ベースラインに対して評価指標による自動評価と人間による評価を行いました。
Automatic Evaluation
自動評価には、以下の5つの評価指標が用いられました。
- BLEU: 正解文とモデルによる生成文がどれだけ類似しているかを測る指標
- CS(Content Selection): BLEUと同じく正解文とモデルによる生成文がどれだけ類似しているかを測る指標
- BLEURT: モデルベースの評価指標であり、生成文がどの程度文法的に正しいかを測る指標
- CIDEr: TF-IDFで重み付けされたn-gramオーバーラップを計算し、画像に対するキャプション生成モデルを評価する際に用いる指標
- PPL(Perplexity): 言語モデルに用いられる評価指標であり、生成文中の単語において、正しい単語を正しく予測できていれば小さくなる
上記の評価指標を用いた結果を下に示します。(TAB-はデータテーブルを使用したモデル、OCR-はOCRで抽出されたデータを使用したモデルを指しています)
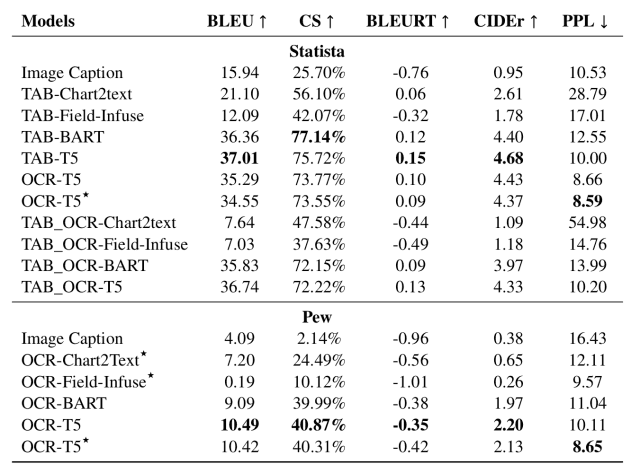
この表より、以下のことが分かりました。
- 大規模事前学習モデル(BART、T5)により要約性能が大幅に向上していることがわかる
- Statistaではデータテーブルがある場合、Chart2textモデルとField-Infuseモデルはデータテーブルから情報を抽出することができるが、質の高い要約文を生成することが困難である(これらのモデルが大規模な事前学習を行なっていないためと思われる)
- 一方、TAB-BARTとTAB-T5は構造化された適切な要約文を生成することができている
- OCRベースのモデルは一般的に質の高い要約文を生成することができるが、OCR処理によって入力データにノイズが入るため、関連情報を抽出する能力が若干低くなっている
このように、BARTやT5といった大規模事前学習モデルが最も良い要約性能を持っていることが分かりました。
Human Evaluation
本論文では生成された要約文の品質をさらに評価するために、英語を母国語とする4人のアノテーターによる、Statistaデータセットからランダムにサンプリングした150枚のチャートについての評価を行いました。
各チャートについて、アノテーターは以下の3つの基準に基づいて要約文を比較しました。
- Factual: どちらの要約文がより事実に基づいて正しいか(すなわち、言及された事実がチャートによって裏付けられているか)
- Coherence: どちらの要約文がより首尾一貫しているか(すなわち、文章がうまく繋がっているか)
- Fluency: どちらの要約文がより流暢で、文法的に正しいか
各基準についてアノテーターは、前者の方が良い(Summary 1 Win)、後者の方が良い(Summary 2 Win)、引き分け(Tie)のいずれかを選びました。
比較結果を下に示します。

この結果より、TAB-T5はOCR-T5と比較して、3つの基準全てにおいて(特にFactualにおいて)有意に優れていることが分かりました。
加えて、データテーブルを入力としないOCR-T5モデルでは、下図のようにhullucination error(赤で示された部分で、出力時に与えられた入力と異なる内容を持つ文を生成してしまう)やfactual error(青で示された部分で、チャートのある数値を別のデータの数値と誤認してしまう)が多くなる傾向が見られました。

これは、OCRテキストから事実に基づいて正しい文を生成できないことが多いためだと考えられ、こうした問題を解決することが今後の課題になります。
まとめ
いかがだったでしょうか。今回は、チャート要約のための大規模ベンチマークを構築し、最新のニューラルネットワークモデルを用いてベースラインを作成したChart-to-textについて解説しました。
本論文により作成されたデータセットを用いたベースラインにより、特に大規模事前学習モデルにおいてチャートを適切に要約することができた一方、データテーブルを利用できない場合には性能が著しく低下するなど、チャート要約タスク特有の課題も明らかになり、今後の動向に注目です。
今回紹介したデータセットの詳細やベースモデルのアーキテクチャは本論文に載っていますので、興味がある方は参照してみてください。



この記事に関するカテゴリー
