gaCNN : CNNのアーキテクチャを遺伝的アルゴリズム(GA) で最適化!
3つの要点
✔️ CNNを進化させるための計算効率の良いGAを開発
✔️ FashionMNIST・ MNISTで検証し、競合16手法のうち12手法の精度を上回る
✔️ 従来は 数日以上かかっていた最適化を 1日以内に圧縮することに成功
gaCNN: Composing CNNs and GAs to Build an Optimized Hybrid Classification Architecture
written by Laurence Rodrigues do Amaral
(Submitted on 28 Jul 2021)
Comments:Published in 2021 IEEE Congress on Evolutionary Computation (CEC)
Subjects: Computer Vision and Pattern Recognition (cs.CV)
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
背景
CNNのアーキテクチャの改良は近年めざましく、それに伴い分類精度も高くなっています!しかし、CNNのアーキテクチャはより複雑になる一方で、アーキテクチャを最適化する部分は「人の力」によるものが大きくなっています。
そこで、GA(遺伝的アルゴリズム)で CNNのアーキテクチャを最適化する手法として「gaCNN」を提案している論文について紹介していきます!
提案手法で述べられている 主な要素は以下の通り
- 遺伝子エンコード戦略 (gene encoding strategy)
- Mutation 演算子
- 異種 (heterogeneous) 活性化関数
- 適合度評価 (fitness evaluation) 戦略
+ ベンチマークデータセットを用いてテストした良いCNNsアーキテクチャを効率的に識別する。
関連研究
GAを用いてCNNの進化を行うには、遺伝子の演算をうまく行う必要あり!
CNNを表現する2つの遺伝子の符号化戦略を提案 (Sunら)
1番目の遺伝子 : 畳み込み層, pooling層
2番目の遺伝子 : 全結合層
Evolving Deep Convolutional Neural Networks for Image Classification
遺伝子の各部分は 1つの層を表し、層の種類に応じたランダムなパラメータ値をもつ。
Crossover
Slack Binary Tournament で選択された 2つの 親 となる 解を用い、同タイプの層を入れ替える (重みや バイアスの初期化戦略も変更可能)。
提案手法
Intro
提案する進化的アルゴリズムは、EvoCNN[25]を拡張したもの
この論文での Contribution
- 異種(heterogeneous) 活性化関数を追加 ReLU、Sigmoid、Tanh
- 特殊な Mutaion Operator を導入 追加、削除、変更、ブロック追加
上記の要素を用いてネットワークアーキテクチャを修正することで探索空間を探索する異なるMutation アプローチの追加を行っている。
- 符号化戦略 Sunら [25]と同様であるが、若干の変更が加えられている
本節は以下のように構成される。
- アルゴリズムの初期化について
- Gene Encoding 戦略について
- 遺伝子の Operatorについて
- Crossover, Mutation, そして、集団選択戦略、Fitness Evaluation
Gene Encoding (遺伝子の符号化)
この論文で提案される gene は、「Layers」と「Activations」の2つから構成される
- Layers
CNNの層の並びを格納し、各層は3つの異なるタイプ(畳み込み層、プーリング層、全結合層)から選択
- Activations
全ての層の活性化関数のシーケンスを格納し、各活性化は3つの異なるタイプ(ReLU、Sigmoid、Tanh)に割り当てる。
(また、プーリング層は一般的に、ネットワークの次の層に対して活性化関数を適用しないので Booleanはその活性化関数を適用するかどうかを示し、それは Layer Typeによって定義)
これらエンコーディング戦略により、演算を別々に適用することができ、新しい層の種類、新しい活性化関数、ショートカット接続を追加する高い柔軟性を実現可能。具体的な表現は下記の通り。
1) Layer Representation
レイヤーは以下のように表現
- 畳み込み層
- ストライド (height, width): (1,1);
- Output Feature Maps: 1 ~ 256;
- カーネル形状 (height, width): (1,1), (3,3) or (5,5);
- バッチ正規化: True or False;
- ドロップアウト : 0.0, 0.1, 0.2, 0.3, 0.4 or 0.5.
- Pooling 層
- Pooling タイプ : Average or Maximum;
- ストライド (height, width): (1,1), (2,2) or (3,3);
- カーネル形状 (height, width): (2,2), (3,3) or (5,5);
- バッチ正規化: True or False;
- ドロップアウト: 0.0, 0.1, 0.2, 0.3, 0.4 or 0.5.
- 全結合層
- ユニット数 : 128, 256 or 512;
- バッチ正規化: True or False;
- ドロップアウト: 0.0, 0.1, 0.2, 0.3, 0.4 or 0.5.
2) Activation Representation
Activations は 以下のように表現
- Activation
- 活性化関数: ReLU, Sigmoid, Tanh
- Activeか?: True or False
C. Evolutionary Algorithm
前項のEncoding Strategyを用いたGA
母集団のサイズパラメータ : 各世代の候補アーキテクチャの数を定義する。
- 母集団はランダムに初期化。
- 各CNNの適合度はネットワークを学習したり、1エポックを使った検証精度を評価したりすることにより計算される。
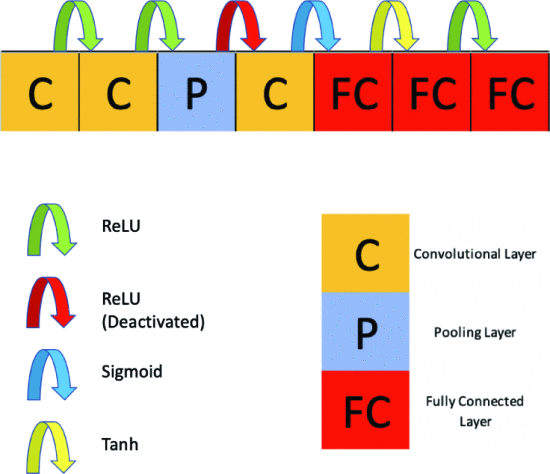
図4. 提案された遺伝子エンコーディングを用いたCNNの例
上位40%の個体がtournament poolに選択
このグループ内では
- 親は20回ランダムに選択
- Crossover により次世代の生成 (母集団のサイズの 40%)
前世代のベスト40%と生成された40%の子を用いて、プール内から母集団の20%を突然変異により生成。
40 % : 前世代の Best 40% (Tournament Poolへ)
40 % : Crossover により生成した次世代
20 % : Mutation により生成した次世代
最大世代数に達するまで行われ、最適解が選択され、少なくとも150エポック数(ne)と小さいバッチサイズ(bs)、0.01から0.001の学習率(lr)で完全学習が行われることになる。これらの流れはアルゴリズム1の通り

Algorithm 1: Genetic Algorithm CNN
D. Population Initialization
母集団の初期化
💡 最初の層 : ランダムなパラメータをもつ 畳み込み層
その後の層の指定はないが、全結合層の後は必ず全結合層である。
※全結合層の数は 3つに制限 (II-B より)
初期化のアルゴリズムの詳細は下記の通り。層の数は、minLayers, maxLayers というように層の最小・最大を定めた値の中でランダムに値をとる。

E. Crossover
この論文で提案する Crossover は以下の通り。
・親個体にトーナメント選択を適用。
・前世代の40%のベストアーキテクチャ候補の中からランダムに2組を選ぶ。
図5,6 Crossover Operation
2つの親個体間で 同じレイヤーの種類 を交換することにより、2つの新しいアーキテクチャの子を生成 (生成した子個体は 図6)
- C (畳み込み層)は Cと交換
- P (Pooling層)は Pと交換
- FC(全結合層) は FC と交換
もし親のレイヤーが一致しなければ、変更はなし (活性度は同じまま)。
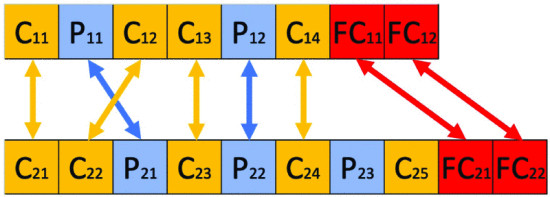
図5 Crossover operation
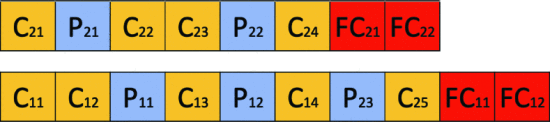
図6. 子を 図5の例を用いて生成した場合
F. Mutation
Mutation には 下記の 4種類を定義
- Add : ランダムな層を ランダムな位置に 「追加」
- Remove : ランダムな位置にある層を 「削除」
- Change : ある層のパラメータ を ランダムに変更 (「パラメータ変更」)
- Add Block : ネットワークアーキテクチャに “畳み込み層, Pooling層, ReLU “の「ブロックを追加」
Mutate させる アーキテクチャは、 40%のベストアーキテクチャと40%の子孫からランダムに抽出され、合計20%の変異率で次世代が生成
G. Fitness
Fitness 関数はCNNの学習を必要とするため、 計算量が多くなってしまう。そのため、fitness を計算するためには1つのエポックのみを使用(GAが1日以内にこれらのネットワークを評価できるように)。GAの最後に最適なアーキテクチャが見つかると、最適化されたアーキテクチャの最終的な Fitness を求めるするためにFully trained される。
IV. データセット
広く使われているベンチマークとして、MNIST と Fasion-MNIST の 2つを選択
いずれも
- 28×28 のグレースケール画像
- トレーニング画像 6万枚 + テスト画像 1万枚
- 10クラス
V. 実験設計
提案アルゴリズムを評価するために、他アプローチとの比較を行う。
Fitness関数は下記の通り。
$$ fitness=\frac{f}{n}∗100,where \cdots(1) $$
-
f : 正しく分類されたサンプル数
-
n : サンプル数
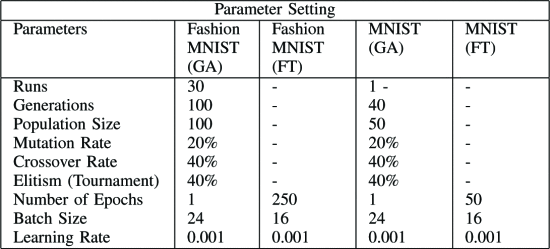
パラメータの設定
パラメータの設定は、以下の表の通り。
-
Fashion MNIST : GAを30回実行
-
MNIST : GAを1回実
GAを実行した結果、最も優れたアーキテクチャはFT(Fully Trained)である (Section VI で議論)
ハイブリッド分類アーキテクチャは、Python v3.6, PyTorch v1.4 framework とNVIDIA Tesla K80 GPUによるCUDA 10 acceleratedで実装。実験の実行には、p3.2xlarge Amazon P3インスタンスを使用
モデルの評価指標
「10クラスすべての精度」 と 「各クラスの精度」を個別に評価
VI. 結果 + ディスカッション
A) Fashion MNIST
提案手法の 計算コスト
- 各実行 : 約18時間
- 実験全体 : 合計540時間 (GPU)
世代を重ねるごとにFitness関数の値が増加している。理由としては、利用したgenetic operatorsが、GAのプール内の集団の探索と利用のバランスが上手くとれているためです。
図7 から考察できること
- 最初の10世代 で 精度が 急上昇している。
- それ以降は微増。
探索空間を制限する最大層数の制約によるもの
世代数や母数を増やすよりも、アーキテクチャの初期化において最大層数を増やす方がより価値があるのではないか?
理由) Crossover や Mutation の特性を活かし、初期アーキテクチャの多様性を高め、探索空間をよりよく探索することができるから
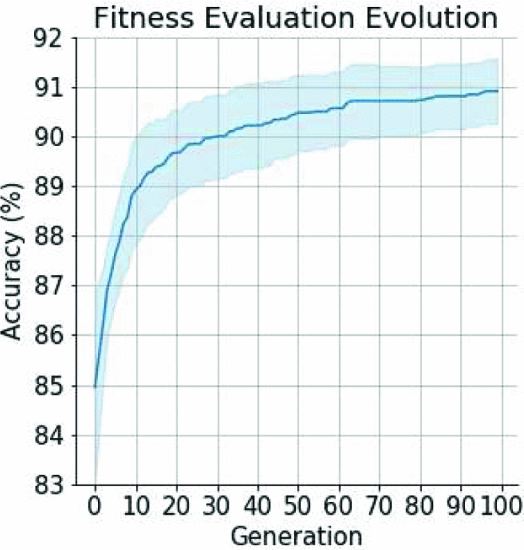
図7 Fashion MNISTデータセットにおける提案アルゴリズムの信頼区間
図8 から考察できること
実験で見つかったBest 30のアーキテクチャを Fully Trained させた結果は図8の通り。
最も良いネットワーク : 93.76% 最も悪いネットワーク : 92.27%
信頼区間95%で平均精度93.13%(92.97%から93.30%の間) → GA を用いた手法では安定した精度が出せることがわかる
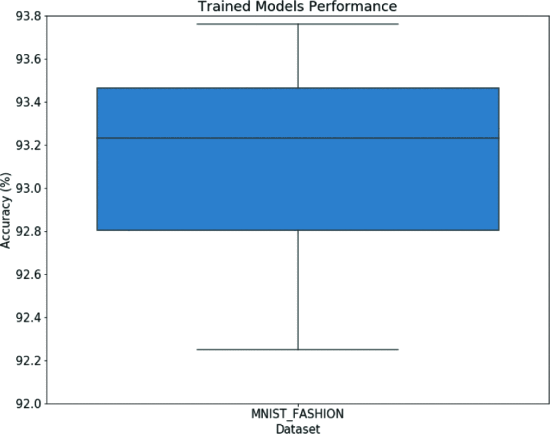
図8. 十分に学習させた後の最適なネットワークアーキテクチャの結果 (外れ値なし)
表II. 各クラスに対して最適なアーキテクチャ
- Trouser, Sandal, Sneaker, Bag, and Ankle Boot に対して 96%以上の高い精度 を示している
- Pullover, T-Shirt/top, Coat and Shirt に対しては 低い精度 → 画像としても似ている ものであるため判別精度が落ちるのは予想通り
- 極端に 判別精度が 低いものがなく いずれも 79%以上
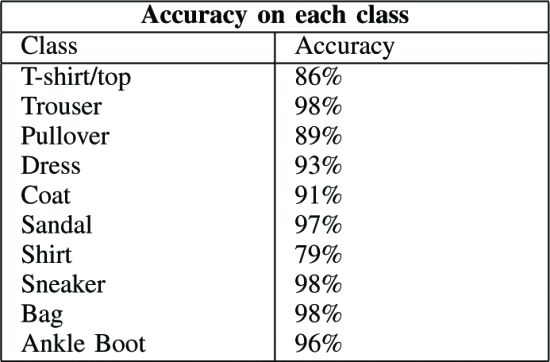
表II クラス別の精度
他手法との比較
提案手法の方が分類精度の高いものを (+), 低いものを (-) と表す。
13手法の内、9手法の精度を上回ることができた
evoCNN と比較
- best の精度は evoCNNの方が高い gaCNNよりも高い最大層数を用いていることも要因の一つ?
- meanの精度は gaCNNの方が高い
→ gaCNNの方が安定的に高いスコアをより短い時間で出しやすい
gaCNN の 実行時間は GPU を用いて 約18h (1日以内)
他のアーキテクチャ最適化手法が 数日から数千時間を要することを考えると時間的にも有用であるといえる。
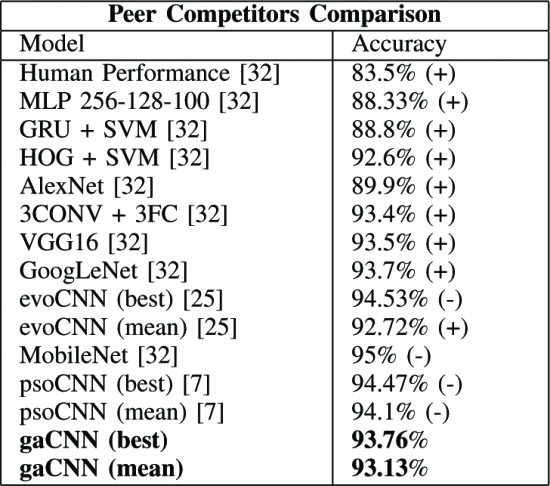
表III. The proposed algorithm performs better than most competitors on the test set
B) MNIST
Fasion MNIST の結果より gaCNNは 外れ値のない安定した結果を出せるといえる。そこで、gaCNNを1回だけ実行しその精度を検証する
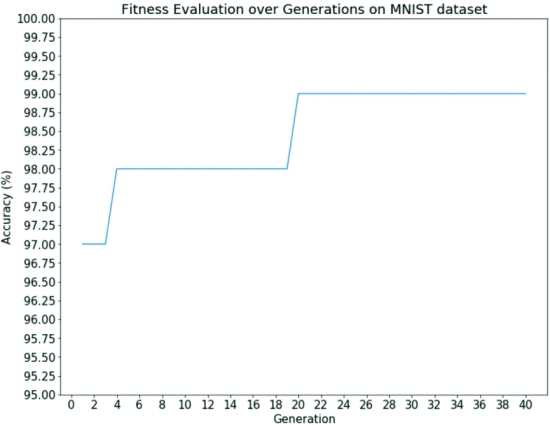
Fig. 9. 十分に学習させた後の最適なネットワークアーキテクチャの結果
表IV
クラス別の 制度を示しているが、大きな偏りはない。
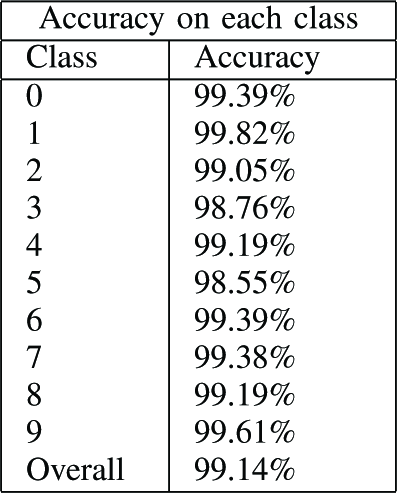
TABLE IV Network Performance by class (全学習後の最適化アーキテクチャの性能)
表V : 他の手法と比較
gaCNN の精度は 16手法のうち12手法を上回っている。
しかし、このデータセットに対する提案アルゴリズムの信頼区間を提供するためには、より多くの実行が必要。
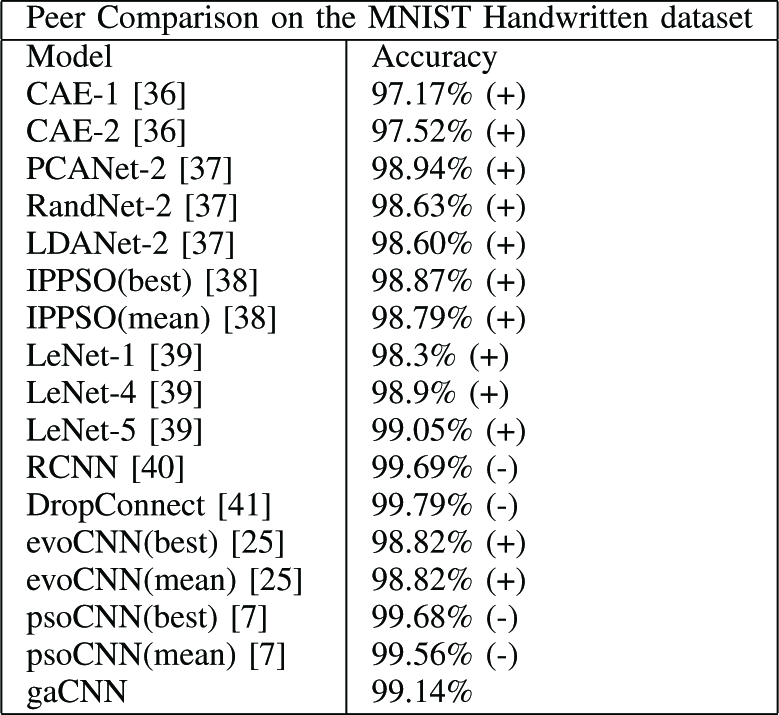
TABLE V MNIST HandwrittenデータセットでgaCNNがより良い結果を示し、1回の実行で競合16手法中12手法を上回る性能を達成した (提案手法の方が分類精度の高いものを (+), 低いものを (-) と表す)
VII. 結論 & Future works
GAを用いて最適化したCNNで構成されるハイブリッドな分類アーキテクチャを提案した。新しいMutation操作とネットワーク全体の異種(heterogeneous)活性化関数を利用している。
アルゴリズム : 接続と層のタイプが複雑でないパラダイムを使用して競争力のあるアーキテクチャを特定できた。最適なNNを特定するのに要した日数は、わずか1日。
Future Works
- 計算能力をより高めた場合
CIFAR-10 やCIFAR-100 のようなより複雑なデータセットでさらに実験できる - フィットネス関数を近似するサロゲートモデルを開発
Deep Learningアーキテクチャの探索において、より高い効率を実現可能になるのでは? - 他のNN手法への応用
異なるタイプのネットワークをはじめ、他のデータセットに対するRNN や RCNN などの他のネットワークアーキテクチャに拡張可能






この記事に関するカテゴリー
