【ICLR2021】EBM学習の効率化 ~粗い画像から細かい画像へ~
3つの要点
✔️ エネルギーベースモデル(EBM)による画像生成において、低解像度から高解像度へと訓練を移行する効率的な手法を提案
✔️ Cycle consistencyが不要な画像のドメイン変換手法を新たに提案
✔️ 提案手法の有効性を画像生成やノイズ除去、画像修復、異常検知、ドメイン変換という多様な実験で確認
Learning Energy-Based Generative Models via Coarse-to-Fine Expanding and Sampling
written by Yang Zhao, Jianwen Xie, Ping Li
(Submitted on 29 Sept 2020)
Comments: ICLR2021 Poster
Keywords: Energy-based model, generative model, image translation, Langevin dynamics
code:
本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
はじめに
本稿で紹介するCoarse-To-Fine EBM(CFEBM)は深層生成モデルの一種であるエネルギーベースモデル(EBM)を用いて効率的に画像生成を行う新手法です。名前に"Coarse to Fine"にあるように、低解像度から高解像度へとモデルの学習を滑らかに移行することで効率的な画像生成を可能にしています。
本稿の流れは以下のようになっています。
- EBMとは
- 提案手法
- 実験結果
- まとめ
エネルギーベースモデル(EBM)とは
EBMは深層生成モデルの一種であり、データ分布$p(x)$をモデリングすることを目指します。ニューラルネットワークのパラメータ$\theta$によって表された分布を$p_{\theta}(x)$とし、以下の式のように定義します。ここで、$E_{\theta}(x)$はデータ$x$を入力としてスカラーを返す関数であり、エネルギー関数と呼ばれます。
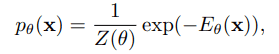
基本的にEBMはこの負の対数尤度$-log(p_{\theta}(x))$を最小化するように学習されます。しかし、分配関数$Z_{\theta}$は全ての$x$に関して積分を行う必要があるため解析的な計算が行えず、密度そのものを求めることはできません。
ニューラルネットワークを用いたEBMの学習では負の対数尤度のパラメータに関する勾配が必要であり、以下のようにデータ分布$p_{data}(x)$とモデル分布$p_{\theta}$それぞれの期待値の差として計算されます。
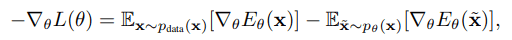
上式において、モデル分布からのサンプリングは難しく、通常MCMCが用いられます。しかし、MCMCは$x$が高次元であると収束に時間がかかるなどの問題が知られています。
ハミルトニアンモンテカルロ法の一種であるランジュバンモンテカルロ法を用いると、モデル分布からのサンプリングは以下のように行うことができます。
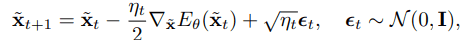
依然としてEBMには学習の安定性や生成データの多様性などさまざまな課題が存在します。次節では画像というデータ構造の特性を生かしてこれらの問題を解決する手法をご紹介します。
Coarse-To-Fine EBM(CF-EBM)
EBMを用いた画像生成において画像が高画質であればあるほどエネルギー関数のマルチモーダル性が上昇しモデル分布からのサンプリングが困難になります。一方で、先行研究においてダウンサンプルされた低次元画像は高次元画像よりも滑らかに変化することが知られています。
これらのことから低次元画像からEBMを学習する方がより安定で早く収束することが期待できます。
Coase-To-Fine EBMではエネルギー関数を表すニューラルネットワークに徐々に層を追加していくことによって低画質から高画質へと訓練を移行していきます。
複数の解像度画像を用いた多段階の訓練
低画質から高画質へと訓練を移行する際に、訓練画像から生成した複数解像度の画像を用いて多段階の学習を行います。訓練のステップ数を$S$、各ステップ$s$の画像を$x^{(s)}$とします。$x^{(s-1)}$は$x^{(s)}$に平均プーリングを行って生成され、$x^{(0)}$は最も解像度の低い画像、$x^{(S)}$は訓練画像を表しています。
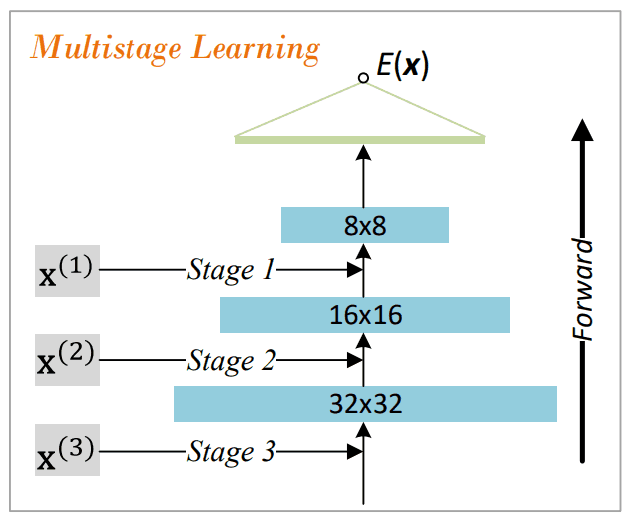
ステップsにおいて学習されたエネルギー関数$E^{(s)}$は次のステップに移行する際に、ランダムに初期化された層を最下層に追加することで新たなエネルギー関数$E^{(s+1)}$に変化します。
学習安定化のための工夫
上記のような多段階の学習における安定性を向上するため、論文ではアーキテクチャとサンプリングに関して二つのアプローチが提案されています。
スムーズなアーキテクチャの変更
ランダムに初期化した層を最下層に追加する際に一段階前で学習されたエネルギー関数を乱さないために、滑らかに変化するアーキテクチャの変更を提案しています。具体的には、PrimalブロックとFadeブロックという二つのニューラルネットワークに関して出力の重み付き和を計算する層(Expandブロック)を定義し、これを最下層に追加することで実現しています。
$Expand(x)=\beta Primal(x) + (1 - \beta) Fade(x)$
上式からわかるように、$\beta$を徐々に0から1へと近づけていくことで細かい特徴へだんだんと注目していく学習が実現できます。
スムーズなMCMCサンプリング
ステップが$s-1$から$s$へと移行した場合、学習初期では主に$E^{(s-1)}$とFadeブロックが学習に寄与します。そして、学習が進み係数$\beta$が1へと近づくとPrimalブロックが重点的に訓練されることになります。従って、MCMCによるサンプリングは学習が進むにつれてPrimalブロックの勾配を反映するようになり、より高解像度な画像がサンプリングされることになります。
さらに、前段階のエネルギー関数$E^{(s-1)}$において得られたサンプルに対してノイズを加えたデータで初期化することで訓練の移行をスムーズにしています。
実験結果
CF-EBMの評価として画像生成、画像復元、異常検知、ドメイン変換の実験が行われました。各実験に関して詳しく説明していきます。
画像生成
CF-EBMをCIFAR-10を用いて訓練した場合の性能評価は下の表のようになりました。VAEやGANなどの深層生成モデルを用いて生成を行い、評価指標としてFrechet Inception Distance (FID)を設定しています。FIDは小さいほど良い指標です。
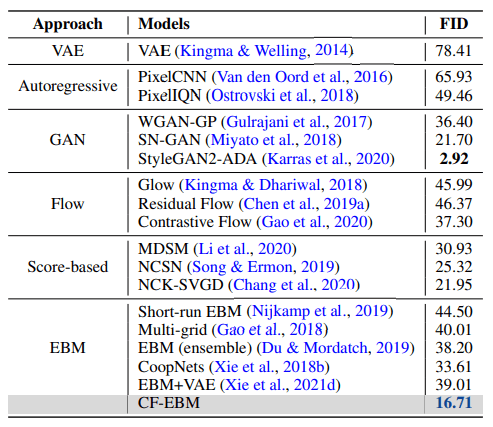
表からわかるように、CF-EBMはほとんどの他手法を上回る性能を記録し、EBMの中では大きな差をつけて最良の性能を記録しています。
また、CelebAをデータセットとして用いた場合の結果は下の表のようになりました。CIFAR-10の場合と同様にFIDを用いて評価を行っています。

こちらでもCF-EBMは他手法を上回る性能を記録しています。ただし、♰が付いているものは中央を正方形にくり抜き、リサイズされた画像を用いて実験されています。
画像復元
一度エネルギー関数を学習させてしまえば、画像復元のタスクに利用することができます。論文では画像復元タスクとしてノイズ除去と空白補完の二つを行いました。
ノイズ除去ではCIFAR-10からランダムに選択したテスト画像にホワイトノイズを付加し、ランジュバン動力学によるサンプリングを行うことで画像の復元が行われました。
また、空白補完では各画像の25%をマスクし、ランジュバン動力学によるサンプリングを行うことでマスクされた部分を画像の復元が行われました。
下の二枚の図はこれらの結果を示したものです。上がノイズ除去、下が空白補完の結果となっています。


どちらの実験においても、復元された画像は大まかな特徴において元の画像と共通しているものの、背景の色合いやメガネの有無など細かい特徴においては異なっていることがわかります。このことから、訓練されたEBMは訓練サンプルを暗記しているのではなく、新しいサンプルの生成も行えることが伺えます。
異常検知
異常検知とは与えられたデータが正常か異常かを解く二値分類問題であり、EBMの尤度が異常検知に有用であることが先行研究によって知られていました。
正常なデータに対するエネルギー関数の出力は大きい値をとり、異常なデータに対するエネルギー関数の出力は小さな値を取ります。
CF-EBMを含む4種類の深層生成モデルをCIFAR-10を用いて訓練し、異常データとしてSVHN、一様分布、定数、画像間の線形補間、CIFAR-100のサンプルを用いました。この結果は下の表のようになりました。評価指標としてはAUROCを用いています。
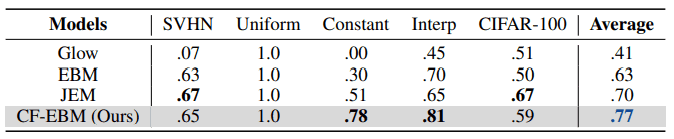
上の表を見るとわかるように、異常検知におけるデータセットに関する平均的な性能が最も高くなっています。また、画像同士の線形補間のように正常と間違えやすいような異常データに対しても高い性能を出していることがわかります。さらに、JEMは訓練時に画像のラベルを用いるのに対し、CF-EBMはラベルを用いないことを考慮すると、CIFAR-100に対しても悪くない性能であると考えられます。
ドメイン変換
画像のドメイン変換とは画像内に含まれる物体などのコンテンツを保ったまま、色やテクスチャなどのスタイルを変換するタスクのことです。
変換前のスタイルを持つ画像の集合をソースドメイン、変換先のスタイルを持つ画像の集合をターゲットドメインとします。EBMを用いたドメイン変換は、ランジュバン動力学法によるサンプリングをソースドメイン画像によって初期化してターゲットドメイン画像を生成することで行います。
従来のCycleGANに代表される手法では、双方向のドメイン変換を学習させ、ソースからターゲット、ターゲットからソースへと変換させた際に元の画像に戻るよう制約をかける損失(Cycle consistency)が考慮されていました。しかし、EBMを用いたドメイン変換ではこのCycle consistencyが不要となっています。
下の図はorange-apple、cat-dog、photo-Vangoghの三種類のデータセットにおいてドメイン変換を行った結果です。他手法に比べてより細かい画像生成が行えていることがわかります。

まとめ
いかがだったでしょうか。今回の論文はEBMを訓練する際の課題である「MCMCでの高次元データのサンプリング」を「低解像度から高解像度への段階的なサンプリング」によって効率化したという内容でした。画像のドメイン変換をEBMを用いて行う際にCycle consistencyが不要である点もおもしろかったです。
今後EBMの適用範囲が広がっていくことに期待したいです。興味を持った方は是非元論文を読んでみてください!



この記事に関するカテゴリー
