人によって受ける推薦の質が変わる?レコメンドシステムにおけるバイアスへの対処
3つの要点
✔️ 主流派なユーザーとニッチ派なユーザーを区別するための4つのアプローチを提案
✔️ 従来の推薦モデルにおいて主流派なユーザーの方がニッチ派なユーザーより精度が高くなるバイアスを実証
✔️ 偏りを解消するための3つの手法を提案
Fighting Mainstream Bias in Recommender Systems via Local Fine Tuning
written by ,
(Submitted on 15 February 2022)
Comments: WSDM '22
Subjects: Information Retrieval (cs.IR)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
推薦システムは情報過多の問題を緩和するために、ユーザーとより良いアイテムを結びつけるという点で重要な役割を果たしています。
古くからの線形モデルや最近のニューラルネットモデルを含むほとんどの推薦システムは、協調フィルタリング(CF)に基づいてユーザーの嗜好を予測して推薦を行っています。
CFの重要なアイデアは、対象のユーザーと同じような興味を持つユーザーを見つけることによって、そのユーザーの行動から嗜好を推定することです。そのため、推薦の質はレコメンドモデルが簡単に類似のユーザーを見つけることができるかに大きく依存します。
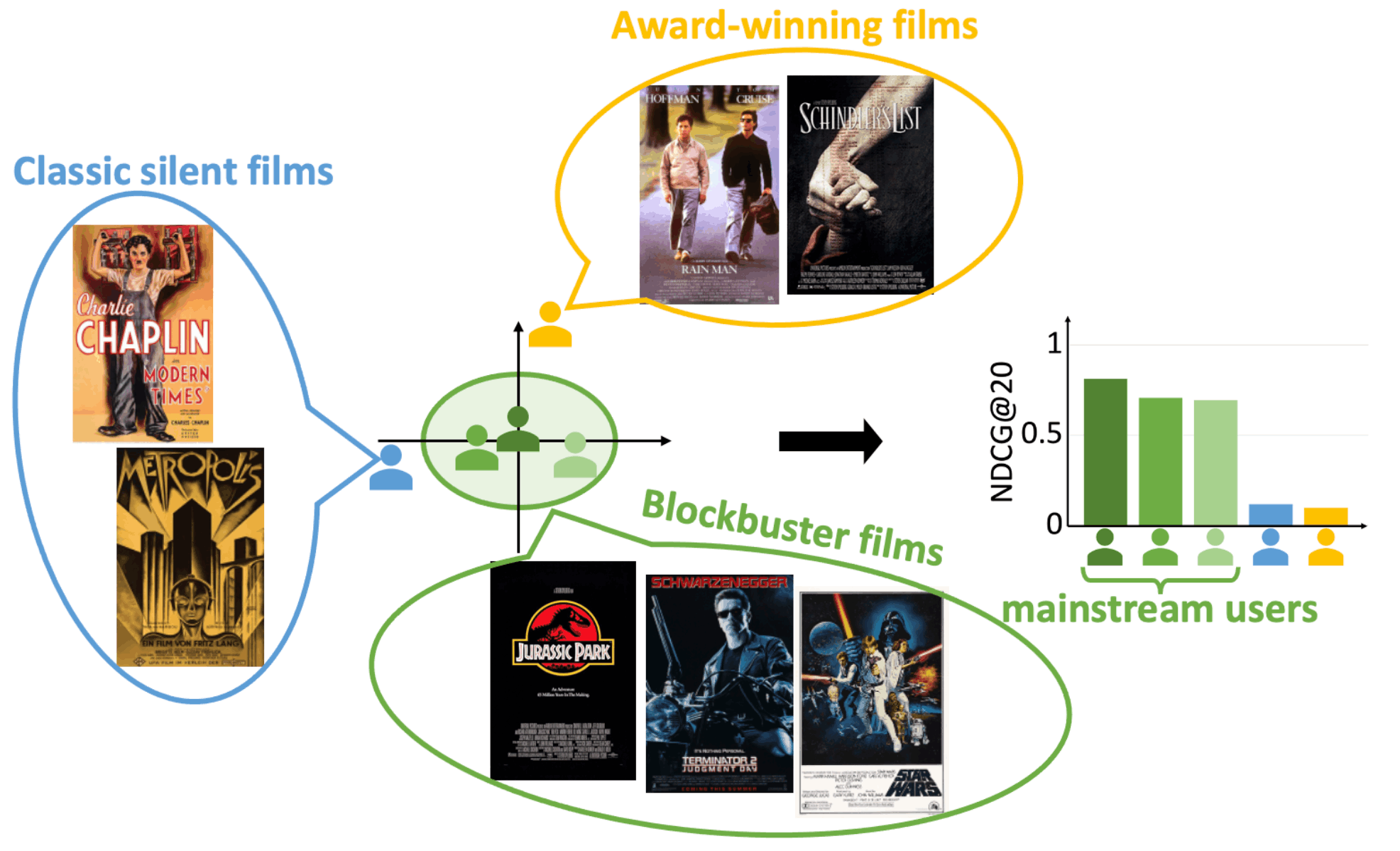
上の図は3人の主流派なユーザーと2人のニッチ派なユーザーを示したものです。3人の主流派なユーザーは人気が高い大ヒット作品を好む傾向があり、最近のvariational auto encoder(VAE)モデルでは高い推薦精度(NDCG@20)が得られています。一方、2人のニッチ派なユーザー(1人は古い無声映画を好み、1人は80年代後半の受賞作品を好む)は推薦精度が低くなっています。
主流派ではないニッチなユーザーは、類似のユーザーを見つけ出すのが難しく、推薦の質が低くなってしまう傾向があります。
このように、レコメンドモデルがニッチなユーザーよりも主流なユーザーを好む傾向のことをメインストリームバイアスと呼んでいます。
ユーザーのメインストリームスコアの計算
筆者たちはまず、メインストリームバイアスが推薦に与える影響を分析するために、各ユーザーがどれくらい主流派であるかを示すメインストリームスコアを提案しました。メインストリームスコアを計算するためには、外れ値検出技術に基づく4つの方法を検討しています。
4つの手法を一つ一つ見ていきましょう。
類似度(Similarity)ベース
類似度ベースのアプローチでは、対象のユーザーに類似のユーザーが多いほどメインストリームスコアが大きくなります。
すべてのユーザーペアで、ユーザー間の類似度をJaccard類似度によって計算します。ここで、ユーザー間の類似度は$J_{u,v}$で表されています。
対象のユーザー$u$と他のユーザー$v$との平均の類似度がメインストリームスコアとなります。
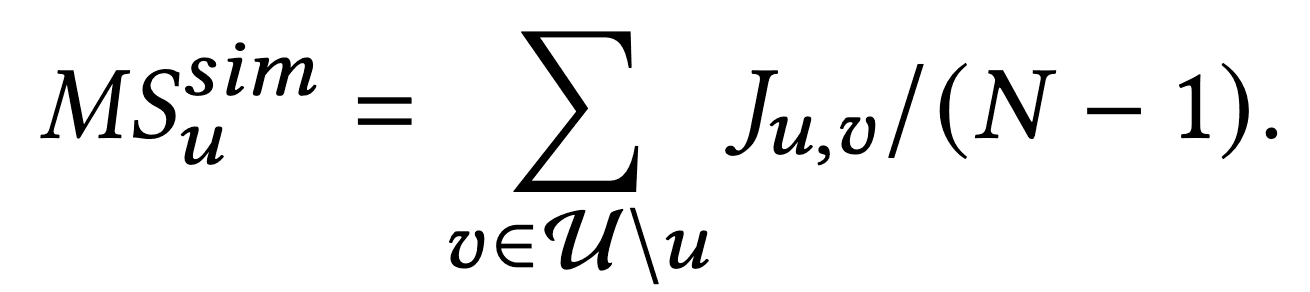
密度(Density)ベース
密度ベースのアプローチは、サンプルが外れ値であるかを、その近傍の密度から判断するものです。この研究では、外れ値(ニッチなユーザー)を特定するために、よく知られた局所外れ値因子法(LOF)を用いています。LOFは値が大きいほど外れ値であることを示すので、マイナスをつけています。
![]()
分布(Distribution)ベース
分布ベースのアプローチでは、アイテムが嗜好される確率の分布ベクトル$d$と対象のユーザーが嗜好したアイテムの履歴ベクトル$O_u$の類似度から計算します。このとき$d$は全ユーザーのアイテム嗜好履歴を平均化したものです。また、$cos()$はコサイン類似度を表しています。
![]()
DeepSVDDベース
DeepSVDDは深層学習ベースの外れ値アルゴリズムDeep Support Vector Data Descriptionです。ニューラルネットワークによってサンプルデータを超球面へとマッピングし、超球面の中心から遠いサンプルを外れ値とみなします。ここで$DeepSVDD\left(O_{u}\right)$は超球面上のユーザー$u$のベクトル、$c$は超球面の中心を表すベクトルです。
![]()
メインストリームバイアスの実証
メインストリームバイアスを観測するために、先程のメインストリームスコアに基づいてユーザーを昇順にソートし、同じ大きさの5つのサブグループに分割します。
以下の表はMovieLens 1Mに対してVAEを適用し、各サブグループのNDCG@20の平均を出した結果を示しています。ここでは、'low', 'med-low', 'medium', 'med-high', 'high'の順でメインストリームスコアの高いグループとなっています。

表から、4つアプローチの全てで、メインストリームスコアの高いグループほどよい推薦精度となることがわかります。
この結果から、筆者らが提案するすべてのアプローチで推薦精度の低くなってしまうニッチユーザーを特定でき、レコメンドモデルによって深刻なメインストリームバイアスが生じていることが明らかになりました。
また、筆者らはMF、BPR、LOCAなど他のモデルや、Yelp、Epinionsなど他のデータセットでも実験を行っており、同じような傾向となること確認しています。
解決策の提案
メインストリームバイアスを緩和するため、2つのグローバルな手法と1つのローカルな手法の提案をしています。
グローバルな手法はモデル学習時にニッチユーザーの重みを大きくして1つモデルで学習する方法で、ローカルな手法は異なるユーザーに対してカスタマイズされたローカルなモデルを学習する方法です。
グローバル手法
Distribution Calibration Method (DC)
DCはデータ拡張に基づくアプローチで、既存のニッチなユーザーに似た合成データを生成して、ニッチなユーザーが学習データセットにおいて主流となるようにするものです。
具体的には、まず上で説明したいずれかのアプローチでニッチなユーザーを特定します。例えば、DeepSVDDの場合、メインストリームスコアの低い50%のユーザーをニッチユーザーとします。その後、あるニッチユーザー$u$に対して類似するユーザーを取得することによって、校正済みの分布ベクトル$p_u$を求めます。
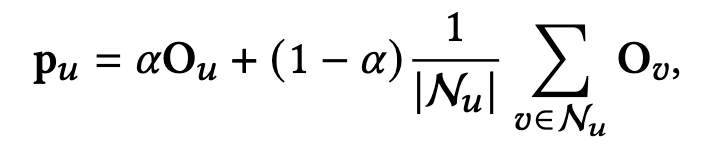 このとき、$\mathcal{N}_u$はJaccard類似度によって求められた類似のユーザー集合で、$0 \leq \alpha \leq 1$はユーザー$u$の嗜好履歴の重みを制御するハイパーパラメーターです。
このとき、$\mathcal{N}_u$はJaccard類似度によって求められた類似のユーザー集合で、$0 \leq \alpha \leq 1$はユーザー$u$の嗜好履歴の重みを制御するハイパーパラメーターです。
最後にこの分布ベクトル$p_u$に基づいてユーザーをサンプリングします。このように拡張されたデータセットを用いて学習されたモデルによって、ニッチなユーザーの重要性を高め、メインストリームを緩和することができます。
Weighted Loss Method (WL)
WLは損失関数におけるニッチなユーザーの重みを直接増加させる方法です。VAEモデルを例とすると、以下のような損失関数となります。
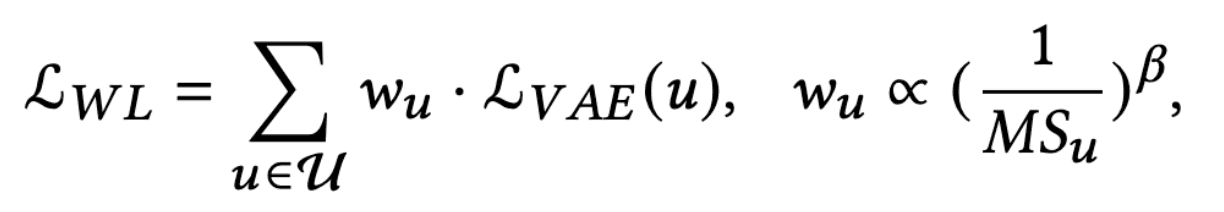
ここで、$\mathcal{L}_{V A E}(u)$はユーザー$u$に対するもとのVAEの損失で、$w_u$はユーザー$u$の重みです。$u$に対する重みは$\left(\frac{1}{M S_{u}}\right)^{\beta}$で、$\beta$はバイアス除去の強さを制御するハイパーパラメーターです。$\beta$が大きいほど、バイアス除去が強く働き、0だと除去を行わないことを意味します。
この重み付き損失関数によってニッチユーザーの重要性を増加させることができます。
ローカル手法
グローバルな手法ではニッチなユーザーの推薦精度が高くなるが、主流なユーザーの精度が下がってしまうといったトレードオフが生じる可能性があります。そこで、筆者はローカルなアプローチを提案しています。
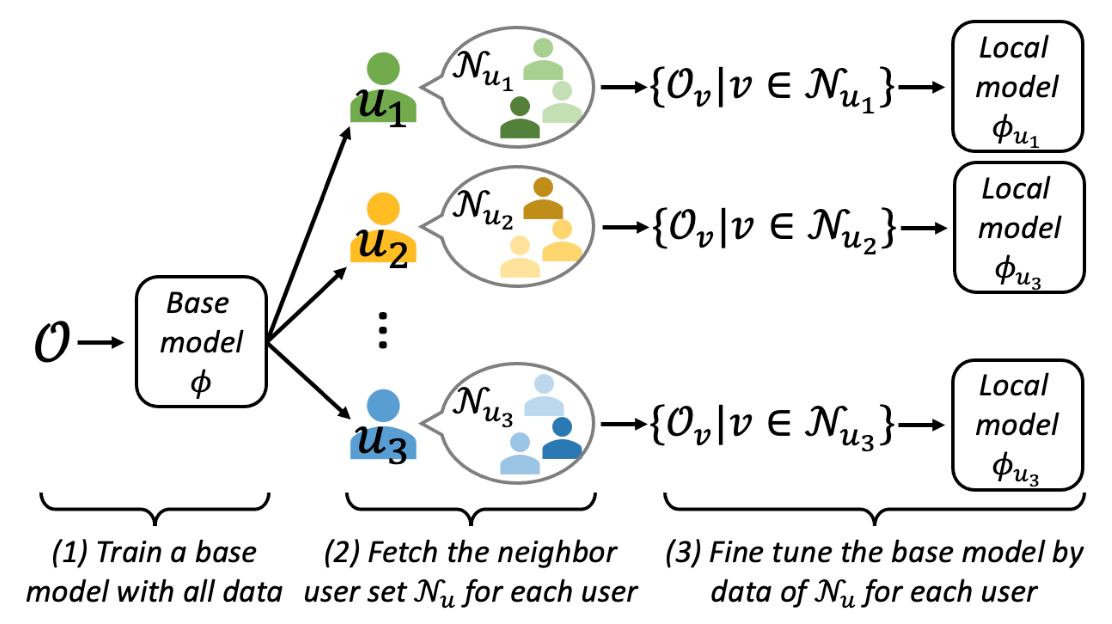
Local Fine Tuning(LFT)
メインストリームバイアスに対処するために局所推薦法を利用することを提案しています。局所推薦法のアイデアはアンカーユーザーを選択し、アンカーユーザーごとに特化したアンカーモデルを学習するというものです。
LFTは3つのステップに分けられます。
- すべてのデータセットを使ってベースモデル$\phi$を学習する
- 対象のユーザー$u$と嗜好が似ている近傍のユーザー$\mathcal{N}_{u}$から、嗜好履歴データのみのサブデータセット$O_{\mathcal{N}_{u}}=\left\{O_{v} \mid v \in \mathcal{N}_{u}\right\}$を作成する
- ユーザー$u$に対して、サブデータセット$O_{\mathcal{N}_{u}}=\left\{O_{v} \mid v \in \mathcal{N}_{u}\right\}$を用いてベースモデルをファインチューニングする
このように、ファインチューニングされた$u$に対するローカルモデル$\phi_{u}$を利用することで、ニッチなユーザーは主流なユーザーや他のニッチなユーザーからの影響を受けにくくすることができます。
実験
実験にはML1M, Yelp, Epinionsデータセットを用いています。
また、ベースモデルとしてVAEを採用し、提案手法をVAEに適用させたモデルで実験を行っています。グローバルな手法としてDistribution Calibration (DC)とWeighted Loss (WL)があります。ローカルな手法としては、最新のLocal Collaborative Autoencoders (LOCA)をベースラインとし、提案手法であるLocal Fine Tuning(LFT)とそのアンサンブル版であるEnsemble version of the LFT model (EnLFT)を用いています。

結果から、筆者が提案したLFTは優れた精度NDCG@20を達成していることがわかります。VAEと比較すると'low'、'med-low'、'medium'にグループにおいて大幅に精度が向上しています。また、'med-high'、'high'など主流なユーザーグループに対しても精度向上が見て取れます。
LFTはニッチなユーザーだけでなく、主流なユーザーに対しても有効であることがわかります。
グローバルな手法であるDCやWLはニッチなユーザーに対する精度は高くなる一方で、主流なユーザーに対しては精度が低くなっています。
まとめ
いかがでしたでしょうか。メインストリームスコアを算出する手法、メインストリームバイアスの実証、バイアスを緩和するための3つの提案手法について紹介しました。主流なユーザーがレコメンドシステムの恩恵を受けて、ニッチなユーザーは恩恵を十分に受けられないといったメインストリームバイアスに着目することは、公平なレコメンドシステムの実現のための重要な視点だと感じました。
今後は、公平なレコメンドシステムのためにバイアスの研究が進んでいくことを期待しています。






この記事に関するカテゴリー




