
Internal-external learningとContrastive learningを用いたアートスタイル変換
3つの要点
✔️ Internal learningとExternal learningを考慮した新しいInternal-externalスタイル変換によって、人間が生成した絵とAIが生成した絵のギャップを著しく埋めることができた。
✔️ 初めてContrastive learningをスタイル変換に導入することで、スタイル間の関係を学習したより完成度の高いスタイル変換結果を得た。
✔️ 複数の既存のSOTA手法と有効性や優位性を比較した。
Artistic Style Transfer with Internal-external Learning and Contrastive Learning
written by Haibo Chen, Lei Zhao, Zhizhong Wang, Zhang Hui Ming, Zhiwen Zuo, Ailin Li, Wei Xing, Dongming Lu
(Submitted on 22 May 2021)
Comments: NeurIPS 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
既存のアートスタイル変換はディープニューラルネットワークによって素晴らしい結果を出していますが、不調和な色や繰り返されたパターンが生じてしまいます。そこで本論文では、2つのContrastive lossを用いたInternal-external learningを提案しました。特に、色やテクスチャを決めるために単一のスタイル画像の内部統計情報を利用し、色やパターンがより調和するように大スケールのスタイルデータセットの外部情報を抜き出しました。さらに、既存のモデルはコンテンツ-スタイル化とスタイル-スタイル化の関係を考慮しているが、スタイル化-スタイル化の関係は考慮していないことに注目し、複数のスタイル化画像の組み込みに対して、コンテンツかスタイルを共有しているものは近く、共有していないものは遠くするContrastive lossを導入しました。
手法
本手法の概要図は下図のようになります。バックボーンには、スタイル変換のSOTAモデルの1つであるSANetを用いました。
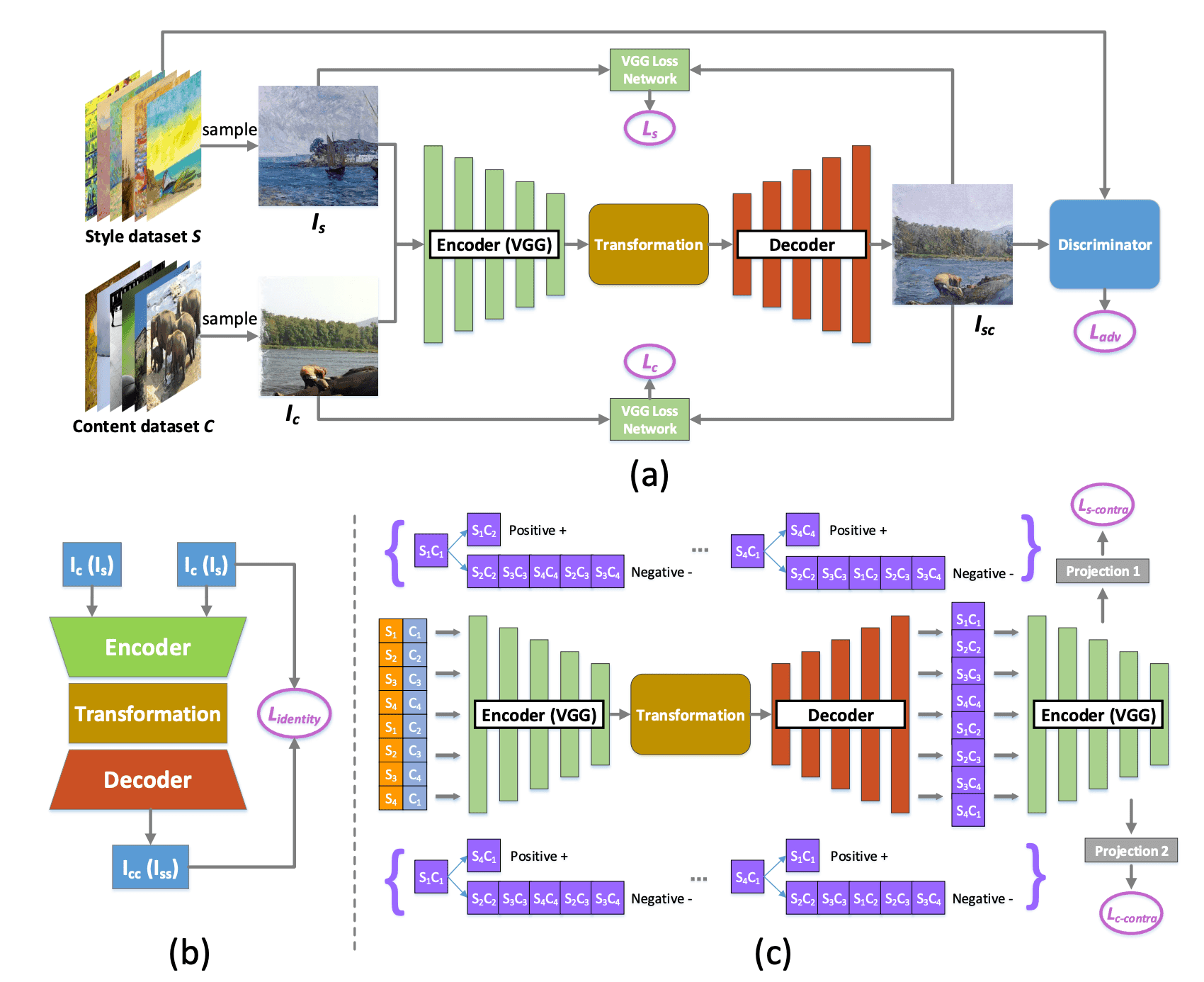
Internal-external learning
写真のデータセットを$C$,アートのデータセットを$S$とします。我々の目的は、単一のアート$I_S\in S$から得られる内部スタイル特徴量と$S$から得られる人間性を考慮した外部スタイル特徴量の両方を学習し、任意のコンテンツ$I_C\in C$をスタイル変換したアーティスティック画像$I_{SC}$を得ることです。
Internal style learning
既存手法に基づいて、単一アート画像の内部スタイル特徴量を得るために、学習済みVGG-19モデル$\phi$を用いました。スタイルlossは次のようになります。
$${\cal L}_S:=\sum_{i=1}^{L}||\mu(\phi_i(I_{SC}))-\mu(\phi_i(I_S))||_2+||\sigma(\phi_i(I_{SC}))-\sigma(\phi_i(I_S))||_2$$
ここで$\phi_i$は$\phi$の$i$番目の層を表します。$\mu, \sigma$はそれぞれ平均と分散です。
external style learning
$S$から人間性を考慮したスタイルを学ぶために、GANを用います。Generatorを${\cal G}$, Discriminatorを${\cal D}$とし、偽の画像はスタイル化した画像、真の画像はアート画像です。敵対的lossは次のようになります。
$${\cal L}_{adv}:={\mathbb E}_{I_S\sim S}[log({\cal D}(I_S))+{\cal E}_{I_C\sim C, I_S\sim S}log(1-{\cal D}(D(T(E(I_C), E(I_S)))))]$$
Content structure preservation
コンテンツ画像の構造を保つために、次のlossを導入します。
$${\cal L}_C:=||\phi_{conv4\_2}(I_{SC})-\phi_{conv4\_2}(I_C)||_2$$
Identity loss
コンテンツ画像とスタイル画像が同一の場合、Generator ${\cal G}$は同一マッピングをするべきです。これによりコンテンツ構造とスタイル構造が保存されます。identity lossは次のように計算されます。
$${\cal L}_{identity}:=\lambda_{identity1}(||I_{CC}-I_C||_2+||I_{SS}-I_S||2)+\lambda_{identity2}\sum_{i=1}^L(||\phi_i(I_{CC})-\phi_i(I_C)||_2+||\phi_i(I_{SS})-\phi_i(I_S)||_2)$$
ここで$I_{CC}$はコンテンツ画像とスタイル画像が$I_C$の時の生成画像、$I_{SS}$も同様です。$\lambda_{identity}$はバランスパラメータです。
Contrastive learning
直感的には、同じスタイル画像でスタイル変換された画像は近い関係を持ち、同じコンテンツのスタイル変換された画像も近い関係を持つはずです。これらの関係をスタイル化-スタイル化関係と呼びます。従来の手法はこれらの関係を考慮せず、${\cal L}_S$や${\cal L}_C$のようなコンテンツ-スタイル化とスタイル-スタイル化のみを考慮してきました。そこで本論文ではContrastive learningを導入し、これらの関係を考慮します。特に、スタイルとコンテンツに対して2種類のContrastive lossを定義します。$s_i, c_i$をそれぞれ$i$番目のスタイル画像とコンテンツ画像、$s_ic_i$を、$c_i$を$s_i$のスタイルで変換した画像とします。バッチサイズを$b$(偶数)とし、スタイルバッチを$\{s_1,s_2,\cdots,s_{b/2},s_1,s_2,\cdots,s_{b/2-1},s_{b/2}\}$, コンテンツバッチを$\{c_1,c_2,\cdots,c_{b/2},c_2,c_3,\cdots,c_{b/2},c_1\}$とします。このようにすることによって、任意の$s_ic_j$に対して、スタイルを共有する$s_ic_x(x\neq j)$とコンテンツを共有する$s_yc_j(y\neq i)$を見つけることができます。
Style contrastive loss
スタイル化された画像$s_ic_j$に対して、$s_ic_x(x\neq j)$を正のサンプル、$s_mc_n(m\neq i, n\neq j)$を負のサンプルとしてスタイルcontrastive lossは次のようになります。
$${\cal L}_{S-contra}:=-log(\frac{exp(l_S(s_ic_j)^Tl_S(s_ic_x)/\tau)}{exp(l_S(s_ic_j)^Tl_S(s_ic_x)/\tau)+\sum exp(l_S(s_ic_j)^Tl_S(s_mc_n)/\tau)})$$
ただし$l_S=h_S(\phi_{relu3\_1}(\cdot)), h_S$はスタイル写像ネットワーク、$\tau$は温度パラメータです。
Content contrastive loss
同様に、$s_ic_j$に対して$s_yc_j(y\neq i)$を正のサンプル、$s_mc_n(m\neq i, n\neq j)$を負のサンプルとするとコンテンツcontrastive lossは次のようになります。
$${\cal L}_{C-contra}:=-log(\frac{exp(l_C(s_ic_j)^Tl_C(s_yc_j)/\tau)}{exp(l_C(s_ic_j)^Tl_C(s_yc_j)/\tau)+\sum exp(l_C(s_ic_j)^Tl_C(s_mc_n)/\tau)})$$
ただし$l_C=h_C(\phi_{relu4\_1}(\cdot)), h_C$はコンテンツ写像ネットワークです。
最終loss
最終的なloss関数は上記をまとめて
$${\cal L}_{final}:=\lambda_1{\cal L}_S+\lambda_2{\cal L}_{adv}+\lambda_3{\cal L}_C+\lambda_4{\cal L}_{identity}+\lambda_5{\cal L}_{S-contra}+\lambda_6{\cal L_{C-contra}}$$
となります。ただし$\lambda$はハイパーパラメータです。
結果
定性評価
結果は下図のようになりました。1行目はコンテンツ画像とスタイル画像、2行目以降はそれぞれの手法でスタイル変換した結果です。
図から、既存手法では歪みや形状の崩壊が見られるのに対して、本手法ではスタイルが調和し、最もらしい結果となっています。

定量評価
定量評価として、広く使われているLPIPSを用いました。安定度と一致度を測るために、ビデオの隣接するフレーム間の平均距離を計算しました。結果は下表のようになりました。値が低いほど性能が高く、本手法が最も良い結果となりました。 
まとめ
本論文では、2つのContrastive lossを用いたinternal-externalスタイル変換手法を提案しました。さまざまな実験を行った結果、定性的にも定量的にも既存手法を上回る結果となりました。本手法はシンプルかつ効率的なので、アートスタイル変換の研究に新たな理解を与え、今後他の手法にも適用することを目指しています。






この記事に関するカテゴリー
