表形式データのための深層学習モデルを再考する
3つの要点
✔️ 表形式データにおける深層学習手法の現状について検証
✔️ ResNet・Transformerを元にしたベースラインの提案
✔️ 既存の深層学習手法・GBDT・ベースラインとの比較実験
Revisiting Deep Learning Models for Tabular Data
written by Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, Artem Babenko
(Submitted on 22 Jun 2021 (v1), last revised 10 Nov 2021 (this version, v2))
Comments: NeurIPS 2021
Subjects: Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
表形式データに対し有効な手法として、勾配ブースティング決定木(Gradient Boosting Decision Tree: GBDT)などが有名ですが、深層学習を表形式データに利用する研究も多く存在しています。
しかし、表形式データの領域では、(画像認識におけるImageNetや自然言語処理におけるGLUEのような)確立されたベンチマークが存在しないこともあり、既存の深層学習手法は十分に比較されていません。それゆえ、表形式データにおける深層学習手法の有効性や、GBDTと深層学習手法とでどちらが優れているのか、などの疑問は不明なままとなっていました。
本記事で紹介する論文では、表形式データのためのシンプルなベースライン手法と多様なタスクセットを導入し、表形式データにおける深層学習手法について詳細な検証を行いました。以下に見ていきましょう。
表形式データ問題のためのモデル
はじめに、表形式データ問題への性能比較実験を行うモデルについて紹介します。
MLP
MLP(Multi Layer Perceptron)は、以下の式で表されます。
$MLP(x) = Linear (MLPBlock (...(MLPBlock(x))))$
$MLPBlock(x) = Dropout(ReLU(Linear(x)))$
ResNet
次に、コンピュータビジョンタスク等で主に用いられているResNetを元にしたシンプルなベースラインを導入します。これは以下の式で表されます。
$ResNet(x) = Prediction (ResNetBlock (...(ResNetBlock (Linear(x)))))$
$ResNetBlock(x) = x + Dropout(Linear(Dropout(ReLU(Linear(BatchNorm(x))))))$
$Prediction(x) = Linear (ReLU (BatchNorm (x)))$
ResNetBlockには既存のResNetと同様のスキップ接続が導入されています。
FT-Transformer
次に、自然言語処理をはじめとした様々なタスクで成功を収めているTransformerアーキテクチャを表形式データのために修正した、FT-Transformer(Feature Tokenizer Transformer)を導入します。大まかな構造は以下の図の通りです。
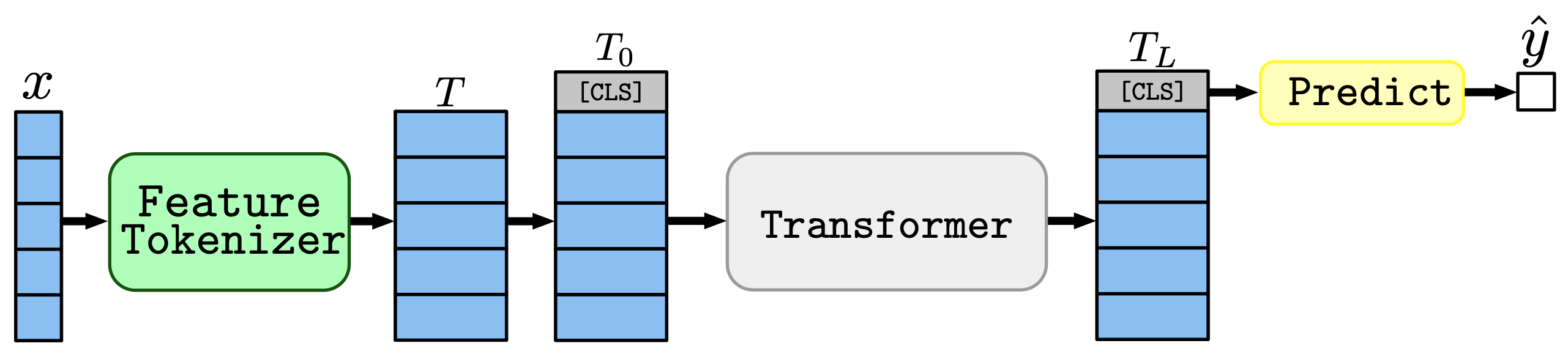
全体の流れとして、まず入力$x$をFeature Tokenizerによって埋め込み$T$に変換し、これに[CLS]トークンを追加した$T0$をTransformerに通します。そして、最後の[CLS]トークンに対応する表現を元に予測を行います。
・Feature Tokenizerについて
Feature Tokenizerモジュールでは、入力$x$を埋め込み$T \in R^{k×d}$に変換します。
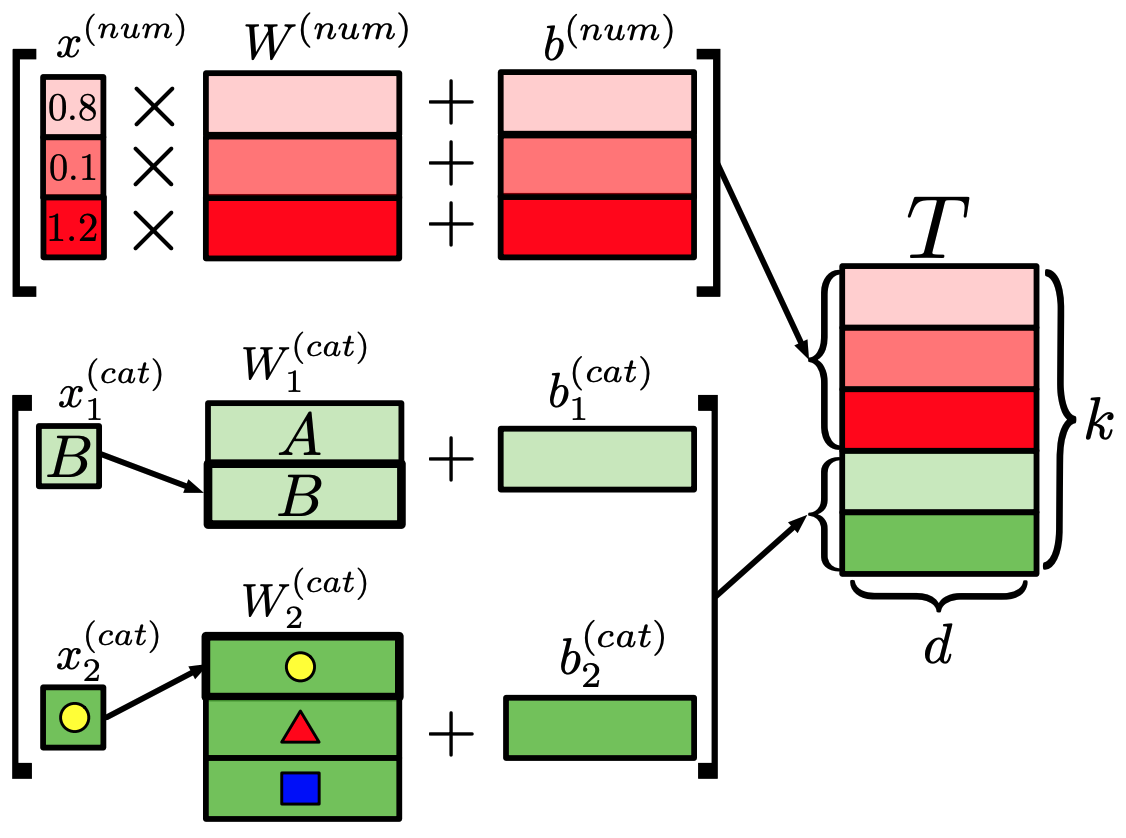
このとき、入力$x$が数値データ($x^{(num)}$)か、カテゴリデータ($x^{(cat)}$)かによって、以下の式のように異なる処理が行われます。
$T^{(num)}_j = b^{(num)}_j + x^{(num)}_j \cdot W^{(num)}_j \in R^d$
$T^{(cat)}_j = b^{(cat)}_j + e^T_j W^{(cat)}_j \in R^d$
$T = stack [T^{(num)}_1, ... , T^{(num)}_{k^{(num)}} , T^{(cat)}_1 , ... , T^{(cat)}_{k^{(cat)}} ] \in R^{k×d}$
ここで、$k$は特徴量の数、$e^T_j$はカテゴリ特徴に対応するone-hotベクトルです。
・Transformerについて
Transformer処理は、以下の図で示される$L$個のTransformer層$(F_1,...,F_L)$からなります。
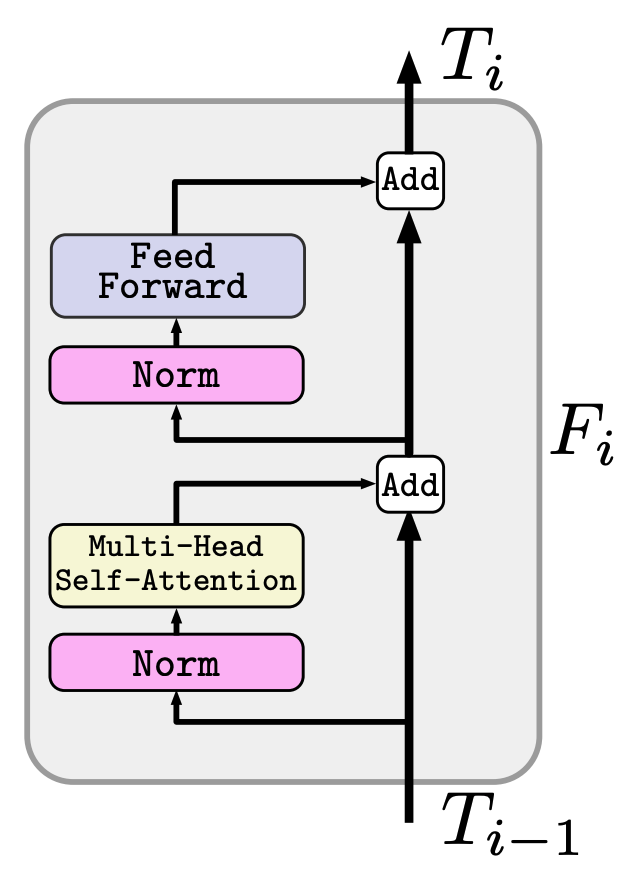
・Predictionについて
Transformerを通して得られた[CLS]トークン表現を利用し、以下の式で表される処理によって予測を行います。
$\hat{y} = Linear(ReLU(LayerNorm(T^{[CLS]}_L)))$
注意点として、FT-TransformerはMLPやResNetと比べて、学習に必要なリソースが大きく、特徴量の数が多い場合に適用することが難しいなどの課題を抱えています。
(これは、より効率的なTransformerの変種を用いることで改善できる可能性があります。)
・その他のモデル
表形式データのために特化した既存のモデルのうち、比較実験に用いるものは以下の通りです。
実験結果
このセクションでは、様々なアーキテクチャの性能比較を行います。事前学習やデータ増強など、モデルに依存しない手法は採用しません。
データセット
実験には、以下に示す11種類のデータセットを利用します。

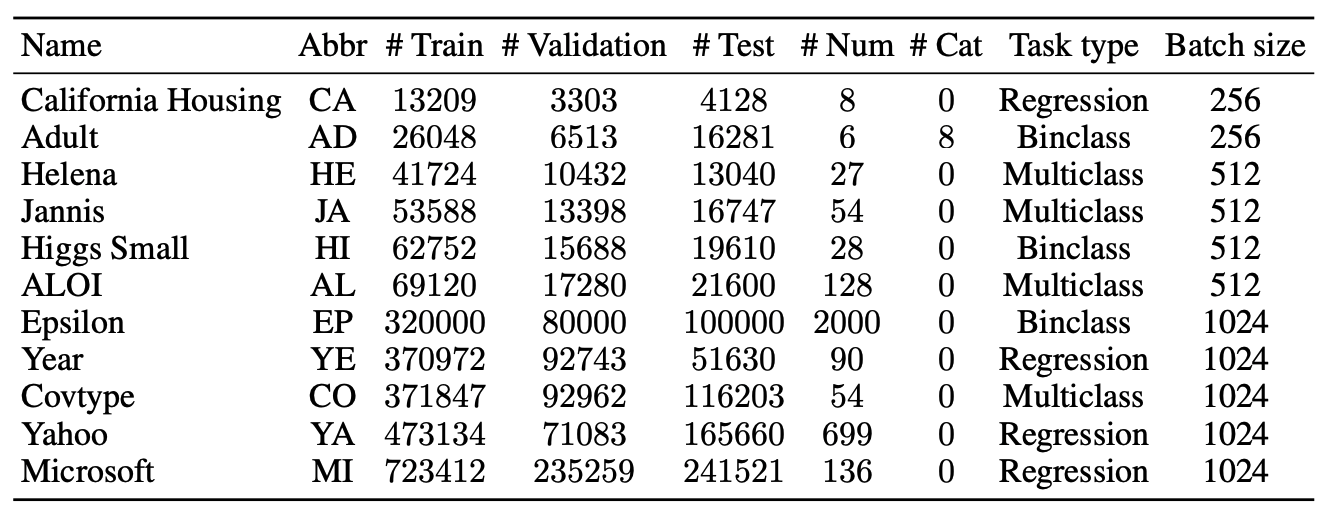
(RMSEはRoot-Mean-Square Errorを、AccはAccuracyを示しています。)
性能の評価には、異なるランダムシードを用いて15回の実験を行います。またアンサンブル設定では、15個のモデルを5つずつに分割し、各グループ内の予測値の平均を利用します(その他の設定は元論文参照)。
深層学習モデルの比較
深層学習モデルの実験結果は以下の通りです。
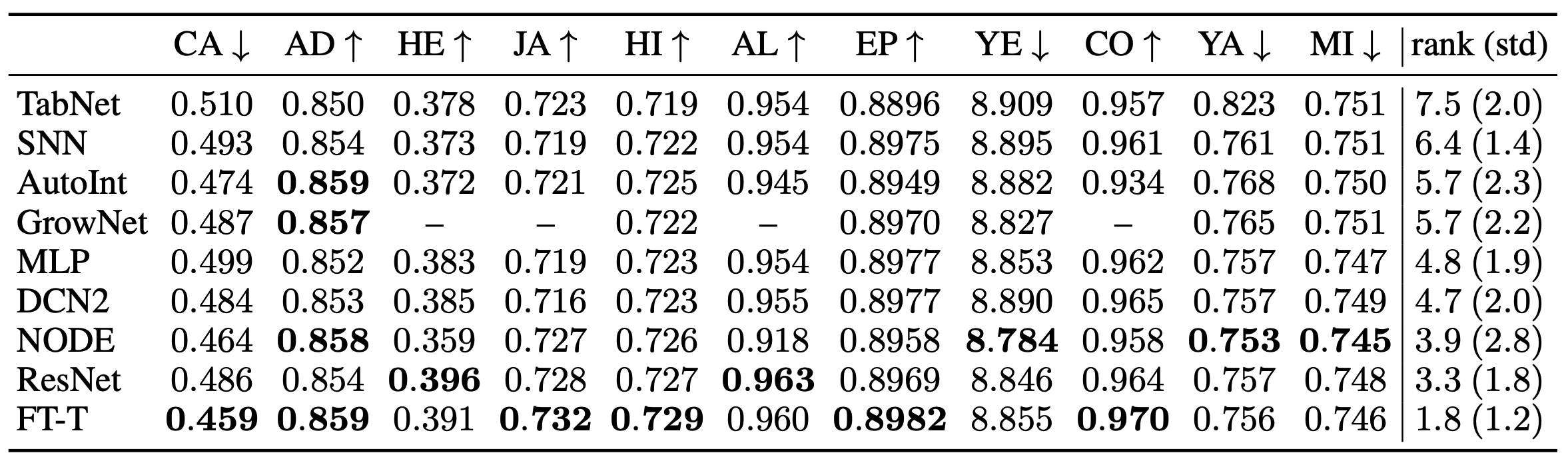
表の右端のrankは、各モデルの平均順位を示しています。
論文にて導入されたベースラインのうち、FT-Transformer(FT-T)はほとんどのタスクで最高の性能を示しており、非常に強力なモデルであると言えます。
また、ResNetはシンプルながらFT-Transformerに次ぐ結果を示しており、効果的なベースラインであることがわかりました。その他の手法の中では、NODEが最も良好な結果を示しています。また、アンサンブル設定における結果は以下のようになります。

アンサンブル設定では、ResNetとFT-Transformerが更に良い結果を示しました。
深層学習モデルとGBDTの比較
次に、深層学習モデルとGBDTとの比較を行います。ただし、速度やハードウェア要件などを無視し、各手法が達成可能な最高の性能とで比較します。
また、GBDTはアンサンブル技術を含むため、深層学習モデルもアンサンブル設定の結果を比較に利用します。結果は以下の通りです。
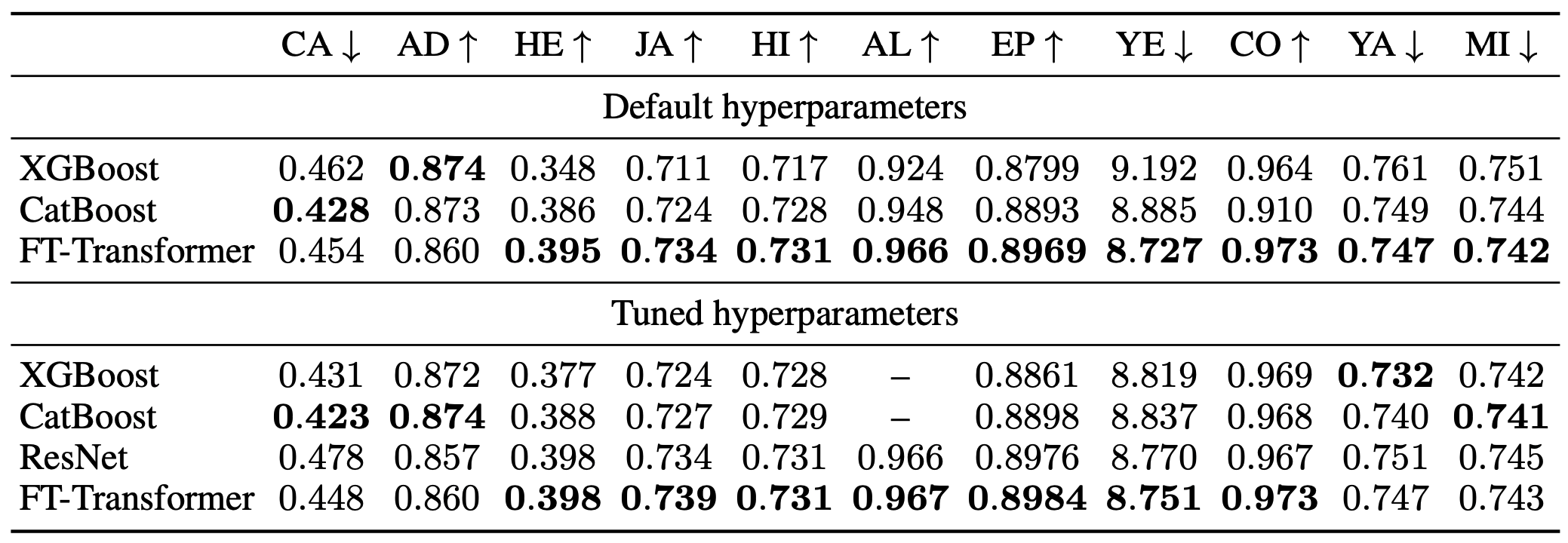
Default hyperparametersはデフォルトのハイパーパラメータ設定、Tuned hyperparametersはハイパーパラメータチューニング済みのモデルの結果を示しています。
FT-Transformerはデフォルト・チューニング済みどちらでも同様の性能を発揮しており、チューニングなしでも優れたアンサンブルモデルを構築できることがわかります。
また、チューニング済み設定ではGBDTがいくつかのタスクでより優れた結果を示しており、深層学習モデルが常にGBDTを凌駕するとは断定できないことがわかりました。
(タスク数のみの比較では深層学習モデルが優位であるようにも思えますが、これは単にベンチマークが深層学習モデルに適した問題に偏っていただけかもしれません。)
ただし、FT-Transformerは全てのタスクで良好な結果を示しており、表形式データに対して他の手法と比べてより普遍的なモデルであるといえます。
総じて、DLモデルとGBDTとで、常に最高の解決策となる手法が存在しているとは言えません。また、今後の深層学習手法の研究では、GBDTが深層学習手法を凌駕しているデータセットを重視するべきであると言えます。
FT-TransformerとResNetの比較
FT-TransformerとResNetの普遍性を比較するため、合成タスクを利用した実験を行います。
具体的には、ランダムに構築された30個の決定木の平均予測値を示す$f_{GBDT}$、ランダムに初期化された3つの隠れ層を持つMLPである$f_{DL}$について、以下のような合成データを作成します。
$x ~ N(0, I_k), y = \alpha \cdot f_{GBDT}(x) + (1 − \alpha) \cdot f_{DL}(x)$
この合成タスクは、$\alpha$が大きいほどGBDT向きに、小さいほど深層学習手法向きのタスクになると考えられます。
この合成タスクにおける各手法の比較は以下の通りです。
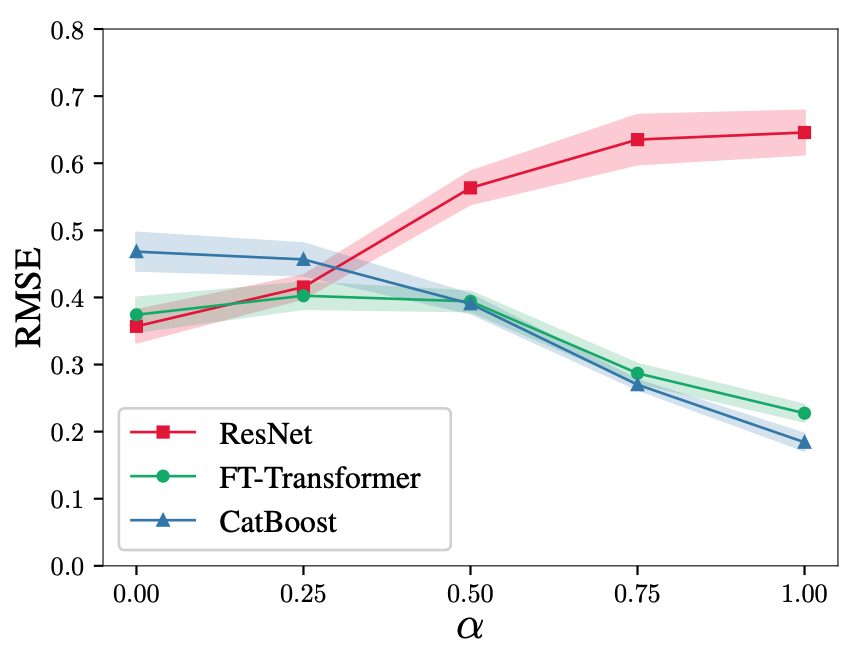
図の通り、ResNetはGBDT向きの設定では大きく性能が悪化しますが、FT-Transformerは総じて良好な結果を示しており、FT-Transformerの普遍性が明らかになりました。
最後に、ResNetとFT-Transformerとの学習時間の比較は以下の通りです。

総じて、FT-Transformerは学習により多くの時間を要し、これは特に特徴量の数が多いデータセット(YA)で顕著になっています。FT-Transformerの計算コストの大きさは、今後改善されるべき重要な課題であると言えるでしょう。
まとめ
本記事で紹介した論文では、表形式データにおける深層学習モデルについて、シンプルなベースラインを導入して既存手法との比較実験を行いました。
表形式データにおける深層学習手法の有用なベースラインとなるResNetベースモデルの提案、Transformerの表形式データへの適用例としてのFT-Transformerの提案、現在の深層学習手法やGBDTとの比較など、表形式データにおける深層学習手法に関する様々な情報が含まれており、公式コードも公開されています。興味がある方は元論文と合わせてご覧ください。
宣伝
cvpaper.challenge主催でComputer Visionの分野動向調査,国際発展に関して議論を行うシンポジウム(CCCW2021)を開催します.世界で活躍している研究者の講演や天才に勝つためのチームづくりについて議論を行う貴重な機会が無料なので,是非ご参加ください!!




この記事に関するカテゴリー
