
关于加速深度学习推理的研究论文--关于SoftNeuro的加速方法的技术细节,现在可以免费试用。
三个要点
✔️ 提出SoftNeuro,一个用于深度学习模型的快速推理框架
✔️ 自动优化任何平台上的推理速度,包括边缘设备
✔️ 利用C/Python API、CLI工具和模型导入功能,易于部署
SoftNeuro: Fast Deep Inference using Multi-platform Optimization
written by Masaki Hilaga, Yasuhiro Kuroda, Hitoshi Matsuo, Tatsuya Kawaguchi, Gabriel Ogawa, Hiroshi Miyake, Yusuke Kozawa
(Submitted on 12 Oct 2021)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
公司介绍
莫弗公司是一家基于研究的成像技术公司。莫弗公司将通过优化 "成像人工智能 "的实际应用,为社会各个领域做出贡献。"成像人工智能 "是数字图像处理技术与最先进的人工智能(AI)/深度学习的结合。
简介
深度学习正在图像处理和自然语言处理等领域找到实际应用。随着其应用范围的扩大,推理工作不仅像过去那样在服务器上进行,而且还在智能手机和边缘设备等各种环境中进行。此外,即使是单个设备,推理也是在异构环境中使用多个硬件组件(如CPU、GPU、DSP和TPU)进行。在本文中,我们提出了动态编程的常规选择(DPRS),这是一种在这种不同环境中有效和自动优化推理的方法,以及SoftNeuro,一个使用DPRS实现快速推理的框架。
深度学习模型推理的优化
在深度学习模型中,图结构被用来描述如何对输入数据进行操作。每一层,即图结构的一个节点,都有各种模式的实现。例如,对于卷积层的实现,有几个不同层次的选项,如
- 算法(直接算法、维诺格拉德算法、稀疏算法等)。
- 参数(瓦片大小、并行性等)。
- 设备(英特尔/ARM CPU、GPU、DSP、TPU等)。
- 数据类型(float32, float16, quantized qint8等)。
- 数据布局(通道-最后,通道-第一,等等)。
这些选择的组合给出了一个单一的实现。我们把这种单独的实现称为 "例程",并把它们与 "层 "区分开来,后者是代表操作的概念。这样一来,我们可以把深度学习模型推理的优化表述为 "通过为每一层选择合适的例程来最小化整体处理时间的问题"。另外,为每层选择的例程集可以称为 "例程路径",可以改写为 "寻找最快例程路径的问题"。(也有一些优化方法,如Halide和TVM,将模型的推理分解为调度,但众所周知,由于搜索空间大,这些方法的优化成本很高)。
剖析和调整
一个例程的处理时间取决于执行环境和输入的特点。因此,SoftNeuro测量执行环境中每层可用例程的处理时间(剖析),并利用这些信息来优化(调整)推理。乍一看,似乎为每层选择最快的例程并构建例程路径会带来最佳的整体性能,但情况并不一定如此。例如,如果一个使用cpu的例程与一个使用cuda的例程相连接,通常需要在第二次计算前将数据传输到GPU。如果不考虑这个传输时间,就有可能选择一个低效的常规路径,这将涉及多次传输。SoftNeuro在例程路径中插入了一个适应性例程,处理这些例程之间的协调问题。在剖析过程中,执行适应程序所需的时间也被测量,以确保调谐考虑到协调过程。
调谐算法:DPRS
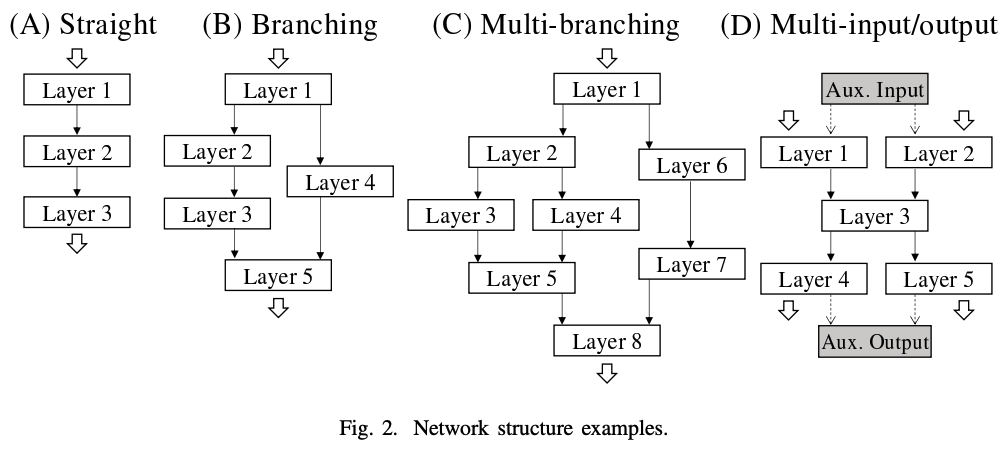
根据从剖析中获得的测量信息寻找最快的常规路径的过程称为调谐。由于组合爆炸,搜索所有可能的常规路径是不可行的。因此,我们提出了DPRS,一种基于动态编程的高效搜索方法。 本文逐步描述了该算法的行为,将其分为(a)串行网络,(b)分支网络,(c)嵌套分支网络,以及(d)多输入和多输出网络。
在串行网络的情况下,到第i层的最快例程路径可以从三个方面获得:(1)到第i-1层的最快例程路径,(2)第i层的例程处理时间,以及(3)适应例程的处理时间。通过使用这样的渐进公式,可以得到最佳的整体常规路径。在分支网络的情况下,可以通过在分支点划分每个例程的动态编程来获得最佳整体例程路径。然而,在嵌套分支的情况下,没有必要在每个分支点为每个例程划分动态编程,变量可以在汇合点整合,避免不必要的计算。最后,多输入/输出网络可以通过增加一个辅助输入/输出层而转变为单输入/输出网络。在本文中,给出了一个概括这些的伪代码。 对于一个串行网络,DPRS的计算复杂度为O(层数x例程数),这表明它是可行的。
结果和商业应用
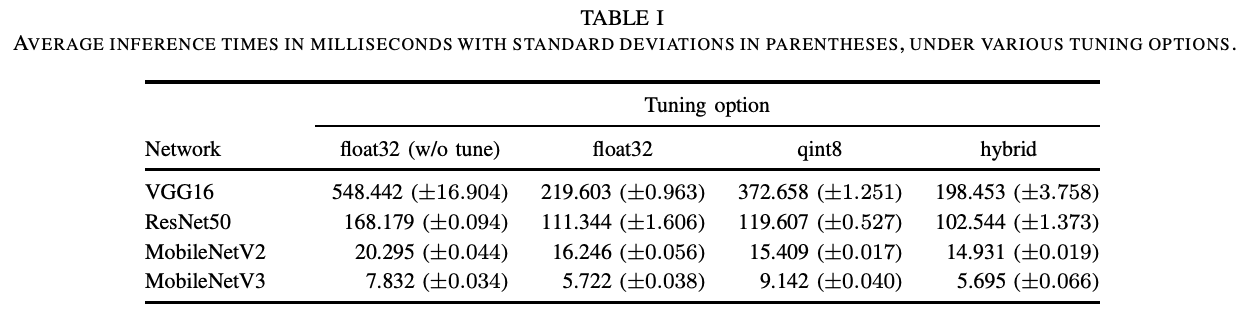
我们已经开发了SoftNeuro,一个具有DPRS自动优化功能的多平台推理框架。在下文中,我们将介绍关于SoftNeuro推理速度的实验结果。首先,为了研究自动优化的效果,我们总结了VGG16、ResNet50和MobileNetV2/V3在Snapdragon 835上使用各选项的处理时间。在这个实验中,我们使用了CPU,并比较了使用float32的推理,使用8位量化的推理,以及使用两者的自动优化。在这种情况下,DPRS考虑到了进行类型转换的适应例程。正如预期的那样,用这两种方法进行的自动优化被发现是最快的。
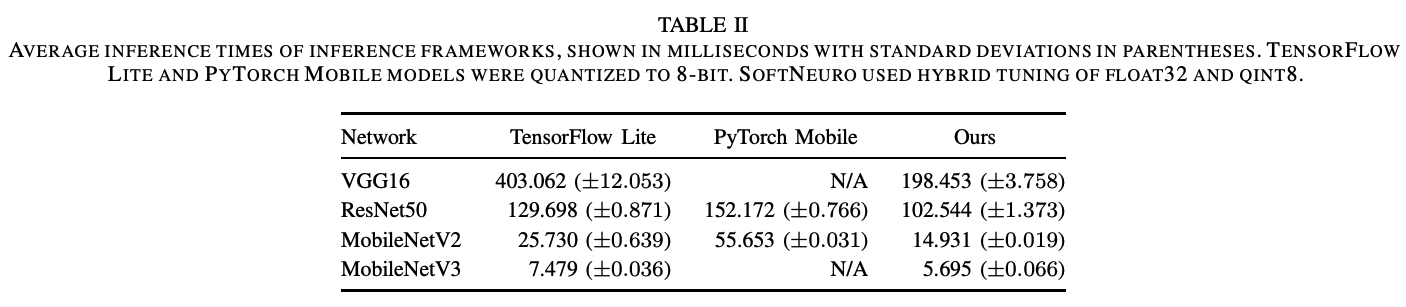
下面是使用移动推理引擎TensorFlow Lite和PyTorch Mobile推理相同的四个模型所需时间的比较。与现有的方法相比,VGG16的速度大约是2.0倍,SoftNeuro是其他模型的最快推理引擎。
SoftNeuro的程序在关键层为英特尔/ARM CPU、GPU和DSP进行了优化,并可用于各种平台,包括边缘设备以及服务器。C/Python API和CLI工具使其易于在广泛的开发环境中使用,而从学习框架PyTorch、TensorFlow和Keras导入模型的能力使其易于部署。在商业应用方面,它已被用作使用深度学习模型的智能手机产品的内部引擎,最近还被作为一个独立的产品采用。
考虑因素
在这项研究中,
- 层和例程概念的分离
- 两阶段的优化:剖析和调整
- DPRS,一种优化图结构上常规路径的算法
- 开发SoftNeuro,一个带有DPRS的多平台推理框架
这种方法使我们能够在边缘设备上加速常见的图像处理模型。在未来,我们计划扩展DPRS来解决优化问题,并保证其准确性和有限的内存使用。
通知
我们现在为公司、学术界和公众提供SoftNeuro非商业许可的免费试用。欲了解更多信息,请访问我们的专门网站。我们期待着您继续支持SoftNeuro!
关于本文作者的信息
Hiroshi Miyake,莫弗公司CTO办公室研究员。



与本文相关的类别