データ欠損に強い外挿タスク用の生成モデル【Materials Informatics】
3つの要点
✔️ 欠損データを「想像」し、補完することで予測精度を向上させる
✔️ 少量のデータベースを用いて、未知の物質探索で重要な外挿予測が可能
✔️ 唯一の実用的な外挿モデルである線形回帰に対して、30%以上の精度の改善
A Generative Model for Extrapolation Prediction in Materials Informatics
written by Kan Hatakeyama-Sato, Kenichi Oyaizu
(Submitted on 27 Feb 2021)
Comments: Published on arxiv.
Subjects: Computational Physics (physics.comp-ph)
code:
本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
導入
MIによる予測は、従来の理論ベースの予測や計算シミュレーションに比べて正確なケースがあり有望視されています。特に、複雑なシステムの理論計算ではコストが爆発的に増大するため、MIの方が適しているケースが多いです。
しかし、従来のMIの手法では、限られた種類の物質の限られた情報から、たった一つの物性を予測するケースが多いです。そのため、より柔軟で人間らしく、物質に関する広い知識を獲得して活用できるアルゴリズムが望まれていました。
MIでは使用できるデータ(情報)量が限られている場合も多いです。その対策として、転移学習は強力なアプローチですが、事前学習に使用する適したデータを収集するのが困難な場合もあります。実験室での実験で得られるデータはせいぜい~104程度です。計算科学で得られるデータは実験で得られるデータとは本質的に異なる上、計算科学では多くの近似を用いており、「正確に現象を再現した」データを得るのは容易ではありません。(細かいそれらの問題を気にしなければある程度はできますが…)
そのため現状では、少ないデータ量でもロバストな予測が行えるアプローチの需要は高いです。
本研究で提案する生成モデルでは、特定の説明変数xと目的変数yの間の関係だけを見るのではなく、幅広いデータインプットします。そして、少量で不完全なデータベースで、様々な物性を予測するために、「想像」によって学習用のデータを追加生成して使用します。
さらに、本研究ではMIでの未知物質探索において最も重要な「外挿タスク」に踏み込みます。外挿タスクは難しく、線形回帰を除いて、MIの分野で「外挿」に強い実用的な方法はほとんどありません。
記述子選択
今回扱う有機分子の記述子には、Molecular descriptors、fingerprints、Neural network outputs、構造関連物性(分子の軌道エネルギーなど)が用いられます。しかし、それぞれの記述子は独立的に開発されたため、記述子選択の明確なガイドラインは存在しません。今回はまず、有機分子のデータベース(H, C, N, O, S, P, ハロゲンを含む160タイプの小分子の小さいデータベース)で記述子のスクリーニングを行いました。
実験値としては、沸点、融点、密度、粘度が記録されています。これらの物性値を以下のような記述子アルゴリズムを用いて学習・予測しました。
- two- or three-dimensional geometric molecular descriptors (Desc 2D or 3D)
- fingerprints (FPs)
- 実験値を考慮した記述子 (HSPiP)
- neural descriptors
- PM7などの半経験的分子軌道法で計算された単分子の性質
neural descriptorsは、グラフ構造で表現された分子構造から上記の4つのパラメータを予測することで、事前学習を行っています。モデルとしては「XGB : Extreme Gradient boosting」を用いて、それぞれの記述子を用いてターゲット分子の物性値を学習させました。XGBは、小さいデータベースで非線形の関係性を扱うのに強力と言われています。ちなみに、この学習においては、説明変数として目的変数以外の他の3つの実験値も使用しています((例)沸点の予測に、説明変数として融点、密度、粘度を加えて使用)。
有機分子の沸点を予測した結果得られた各記述子での予測誤差が以下(a)になります。
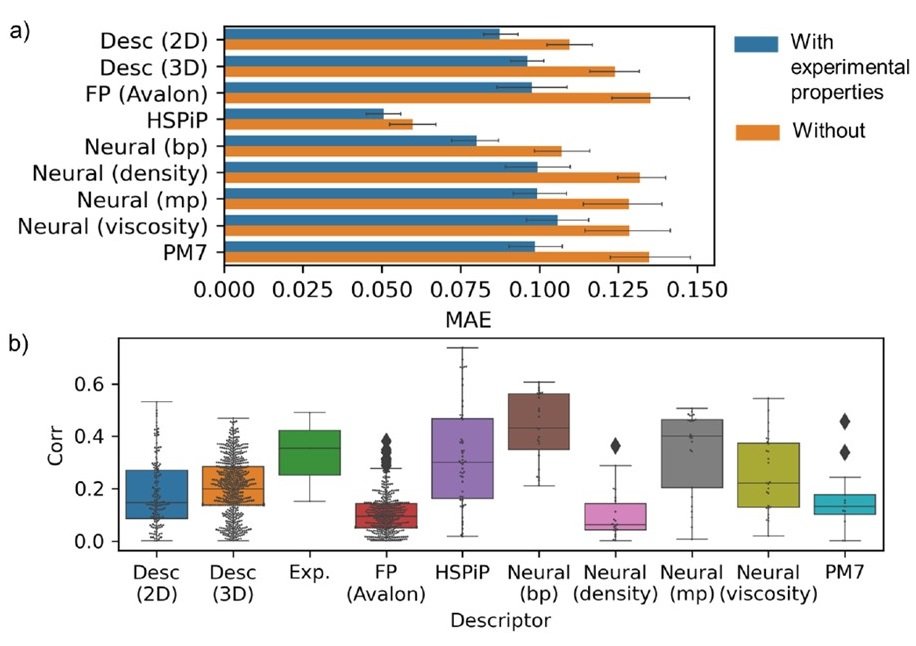
(b)は説明変数(記述子によって分子が記述された結果)と目的変数(沸点)との間の相関性の比較を示します。
HSPiP記述子がベストパフォーマンスであり、事前学習したNeural descriptorも良好な結果となりました。また、説明変数xに記述子だけでなく、実験値として沸点以外の融点などのパラメータを入れたものは(青色のバー)、記述子だけよりも顕著に性能が向上しました。さらに、neural descriptorsで融点のために学習したのものは、沸点の予測でも良好な結果となりました。これは2つのパラメータが強く相関するためと考えられます。しかし、neural descriptorsでの転移学習は必ずしも良い結果にはなりませんでした。これは、物性パラメータが多岐にわたることと、今回のデータベースが小さいことが原因であると考えられます。
また、目的物性を沸点から融点や粘度、密度などに変えると、効果的な記述子も変わってしまうことが分かりました。よって、すべてにおいて有効な記述子はないと言えます。
しかし、別の実験値をxに加えると性能が向上したことから、実験値は良い記述子となるといえます。さらに別の試験から、説明変数と目的変数の間で直線的な相関性が強いと、性能が向上することが分かりました(上図(b))。よって、今回のような小さいデータベースで機械学習をするには、説明変数と目的変数に強い相関が必要だといえます。
モデル構築・評価
実験値は有効な説明変数ですが、一般的な記述子使用やシミュレーションなどに比べて測定コストがかかります。そのため、実験値のデータベースは穴あきであることが非常に多いです。
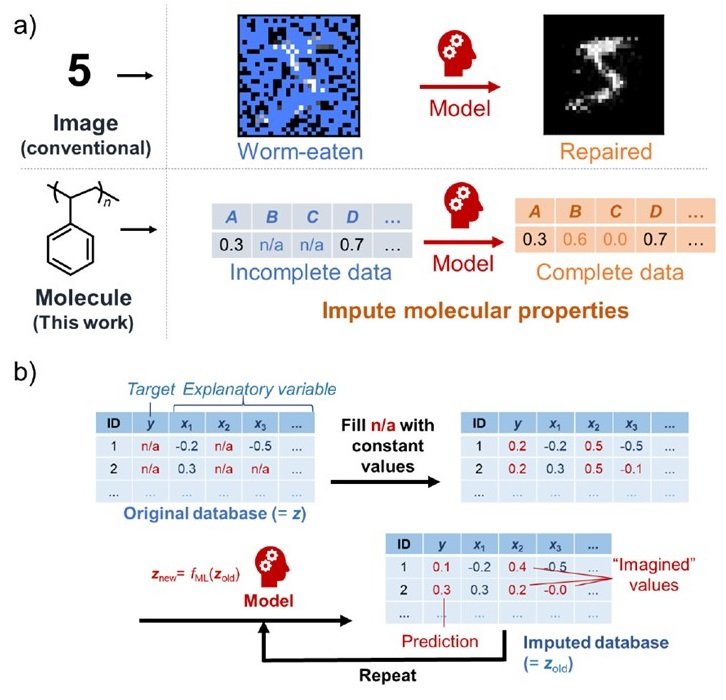
本研究では、穴あきデータベースに強いという特徴を持つ生成モデルを提案します。画像修復を例に挙げると、この生成モデルでは、虫食い画像のデータ欠損部分を「想像」することで、オリジナル画像を予測することができます。これは人間がするように、観測変数の間の関係性を考慮することで可能となります。今回は、この手法をマテリアルデータベースに活用していきます。欠損値の「想像」による代入プロセスは以下のような流れになります。
- 最初に、データベース中のxとyの穴あき部分を定数(zold)に置き換えます。
- 次に、データ分散の模倣記録とともに、提案モデル(znew = fML(zold))を学習させます。
- 得られたモデルによる予測値(znew)で最初の定数(zold)を置き換えます。
- これを収束するまで繰り返します。
この一連のプロセスで穴あきデータベースを完全なものにします。
記述子選択のときと同様に、構造情報から4つの物性値を予測しました。ここでは記述子として、Desc 2D(2次元幾何分子構造の記述子)を使用しました。そして穴あきを再現するため、0、30、60%でデータをランダムに消去したデータベースを作成しました。データは、外挿タスクを試すために、目的変数の値が高いトップ20%をテストデータとして使用し、残りをトレーニングデータとしました。
生成モデルとしては、「モンテカルロフロー(MCFlow)」と呼ばれるフローベースモデルを代入器として使用しました。このフレームワークは、画像修復を含む代入タスクの連続で最新の性能を達成しています。適切なランダム性と可逆的なマッピング関数が予測において重要な役割を果たすとされています。オートエンコーダやGANなどの他の深層生成モデルと比較しても、このフレームワークは小さいデータベースにおいてより正確な代入が可能であることから、今回はこのモデルを使用しました。
この生成モデルでデータ損失比が0.6のデータセットで沸点の外挿予測をしたところ、MAEは0.2より小さかったのに対し、XGBではMAEが約0.3でした。これはXGBが外挿に向かないためと考えられます。ランダムフォレストやアンサンブルモデルを含むほとんどの決定木タイプの回帰モデルは、独特なクラス分類に特化したアルゴリズムを持ちます。そのため、外挿タスクには適しておらず、概ねXGBの結果と似たような感じになります。 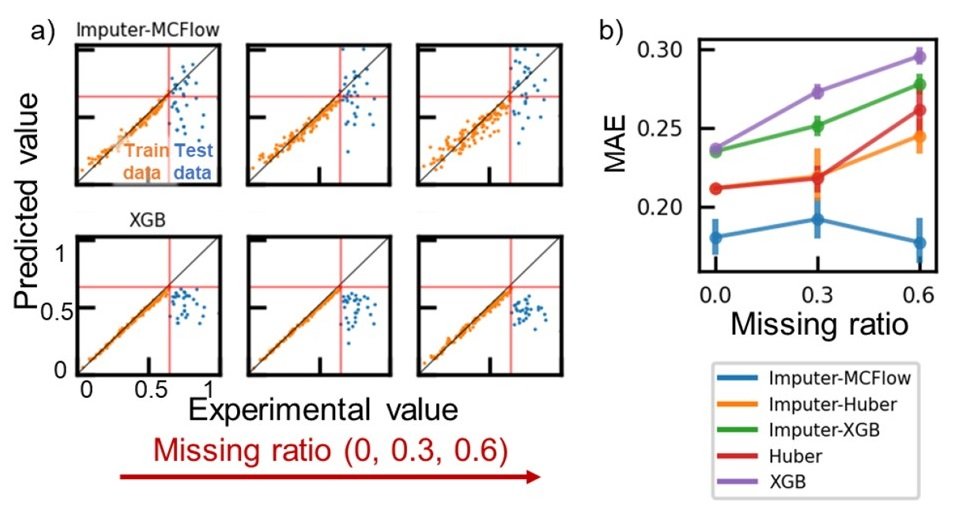
Imputer-XGB : 平均値など何らかの形で欠損値を埋めてXGBモデルで予測した結果
外挿の分野で唯一実用的なのが線形回帰です。損失データは平均値に置き換え、Huber損失関数を用いて線形回帰モデルを構築し、同様の予測を行いました。その結果、MAEは0.20から0.25であり, XGBよりましですがMCFlowには及ばない予測性能が得られました。よって、MCFlowモデルは線形回帰を代替する優れた外挿用モデルとなる可能性があります。
生成モデルはまず、元のインプットデータzを同じ次元のベクトルzmapに変換するために、マッピング関数fmapを使用します。その後、最大密度推定のために、多層パーセプトロンでzmapを^zmapに変換します。そして、逆の関数fmap-1でzを再構成します。
(※fmapは可逆的な関数になるようにデザインされています。)
興味深いことに、説明(潜在)変数は上記の変換後、より強く目的変数と相関する傾向があります。この「説明変数と目的変数の間の基礎となる線形性」を抽出する能力が、高精度な外挿の達成に強く寄与していると考えられます。
GANやオートエンコーダ(AE)、変分オートエンコーダでも同様の予測タスクを行いました。その結果、GANでは学習に失敗しました。これは、深層学習にも関わらず学習データが150くらいしかなかったためと思われます。AEやVAEは悪くない精度でしたが、外挿域では予測不可でした。
このようなフローベースモデルとオートエンコーダでの性能の違いは、逆変換可能かそうではないかの違いに起因すると考えられます。
ランダムフォレスト代入器のMissForestは、小さいデータベースでも他の一般的なモデルより良い外挿予測性能を与えました。このフレームワークはインプットデータからzの分布を見積もるため、生成モデルの派生形と言えます。
以上のように、優れた外挿性能を示したMCFlowですが、ハイパーパラメータやネット構造の最適化を行えばさらに優れた外挿・内挿予測性能が得られると考えられます。
様々な物性値の予測性能
生成モデルの性能を調査するため、いくつかのデータベースを用いて物性値の予測を行いました。 使用したデータベースは12000個の化合物と、ガラス転移点や比熱、粘度、蒸気圧などの25種類以上の物性値をカバーしており、多くの欠損値も含みます。このデータベースを用いて、今回の生成モデルによって、欠損値を代入して予測を行いました。記述子には2D molecular discripitorを使用し、目的変数以外の物性値を加えて、回帰タスクを繰り返すことで様々な物性値の予測を行っています。目的変数の上位20%を外挿タスクの評価に、ランダムに抽出した20%を内挿タスクの評価に用いました。
例として、約100個のデータから有機分子の粘度を予測した結果、外挿においては、MCFlowはHuber(Huber損失関数を用いて構築した線形回帰モデル)よりも30%近い損失関数値の改善が見られ、内挿においても同様の結果が得られました。
さらに、評価指標として以下のように定義した再現率と適合率を用いて評価を行いました。
再現率(Recall) = 外挿域において正確に予測できた割合
適合率(Precision) = 内挿域に優れた性能の候補値を間違えて見つけてしまわない割合
その結果、Huberではどちらも0%でしたが、MCFlowではそれぞれ、19%と75%という値が得られました(上図 b))。外挿タスクの難しさを考慮すると、MCFlowの19%という値はファーストステップとして十分な値といえます。
また、使用データ数が100個以下の場合はMCFlowの方が優れていましたが、100個を超えるとMCFlowとHuberの予測精度は同程度になりました。これは、100個を超えるとそれぞれの予測器に十分な情報が与えられるためと考えられます。しかし、実験によってデータベースを作る際にはコストと手間がかかるため、より少量のデータで精度よく予測が可能なMCFlowは優れたモデルであるといえます。
その他のモデルとの比較
Huberなどの線形回帰は単純でロバストなモデルですが、利用に制限があります。なぜなら、様々な要素からなる複雑な化学的・物理的な現象が線形回帰に当てはまるとは限らないからです。
転移学習は事前学習に必要なデータ量が十分でないと適用できません。グラフ構造を記述子に用いたモデルは強力な方法ですが、やはりデータ量が少ないと適用できません。さらに、転移学習やグラフ構造を用いたモデルは、予測がブラックボックス化されることで、物質の構造と物性の相関性などが研究者に理解しにくくなる欠点があります。一方、今回提案している生成モデルは、両者よりも有利な点があります。それは、構造と物性の相関性が「生成されたデータベース」として両者よりも明示的に表される点です。
さらに、フローベースの生成モデルは外挿タスクに優れます。一方、その他のMIで使用されるアルゴリズムは内挿タスクに特化している場合が多いです。
まとめ
本論文では、様々な物質に関する様々な情報を代入し、予測することができる生成モデルを提案しました。また、欠損データを「想像」することで、内挿および外挿タスクで予測精度を向上させることができました。これは我々人間がしていることに近づいているといえます。特に外挿タスクは未知の物質探索で最も重要であることから、本研究の成果がMIにおけるブレークスルーにつながることが期待できます。



この記事に関するカテゴリー
.jpg)




