
ディープラーニング推論高速化に関する研究論文 ~無料トライアル中『SoftNeuro』の高速化手法について技術詳細を解説~
3つの要点
✔️ 深層学習モデルのための高速推論フレームワーク SoftNeuro を提案
✔️ エッジデバイスを含むあらゆるプラットフォーム上で推論速度を自動最適化
✔️ C/Python API・CLI ツール・モデルインポート機能を備え導入が容易
SoftNeuro: Fast Deep Inference using Multi-platform Optimization
written by Masaki Hilaga, Yasuhiro Kuroda, Hitoshi Matsuo, Tatsuya Kawaguchi, Gabriel Ogawa, Hiroshi Miyake, Yusuke Kozawa
(Submitted on 12 Oct 2021)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
企業紹介
モルフォは、イメージング・テクノロジーの研究開発型企業です 。これまでに培ったデジタル画像処理技術と最先端の人工知能(AI)/ディープラーニングが融合した「イメージングAI」を最適なかたちで実用化し、社会のさまざまな分野に貢献していきます。
はじめに
深層学習は、画像処理や自然言語処理などの分野で実用化が進んでいます。その適用範囲の広がりとともに、従来のようなサーバー上での推論だけでなく、スマートフォンやエッジデバイスといった多様な環境での推論が行われるようになりました。さらに、ひとつのデバイスを取ってみても、CPU, GPU, DSP, TPU といった複数のハードウェアを用いたヘテロジーニアスな環境で推論が行われています。本研究では、このように多様化する環境での推論を効率よく自動最適化する手法 Dynamic Programming for Routine Selection (DPRS) と、それを用いて高速な推論を実現するフレームワーク SoftNeuro を提案します。
深層学習モデル推論の最適化
深層学習モデルでは、入力データに対してどのような演算を重ねていくかをグラフ構造で記述します。グラフ構造のノードである各レイヤーを、具体的にどう実装するかには、様々なパターンがあります。例えば畳み込みレイヤーの実装には、以下のような異なるレベルで複数の選択肢が存在します。
- アルゴリズム(Direct, Winograd, Sparse など)
- パラメタ(タイルサイズ、並列度など)
- デバイス(Intel/ARM CPU, GPU, DSP, TPU など)
- データ型(float32, float16, 量子化済み qint8 など)
- データレイアウト(channels-last, channels-first など)
これらの選択肢の組み合わせが、ひとつの実装を与えます。我々は、このような個々の実装のことを「ルーチン」と呼び、演算を表す概念「レイヤー」と区別しました。そうすることで、深層学習モデル推論の最適化は「レイヤーごとに適切なルーチンを選択して、全体の処理時間を最小化する問題」として定式化することができます。あるいはレイヤーごとに選択されたルーチンの集合のことを「ルーチンパス」と呼ぶと、「最速のルーチンパスを探索する問題」と言い換えることもできます。(Halide や TVM など、モデルの推論をスケジューリングにまで分解して最適化する手法もありますが、これらは探索空間が膨大であるため最適化が非常に高コストであることが知られています。)
プロファイリングとチューニング
ルーチンの処理時間は、実行環境や入力の特性によって変わります。そこで SoftNeuro では、各レイヤーに対して使用可能なルーチンの処理時間を実行環境であらかじめ計測(プロファイリング)し、その情報をもとに推論を最適化(チューニング)します。一見すると、各レイヤーについて最速なルーチンを選択してルーチンパスを構成すれば、全体として最適になるように思えますが、実は必ずしもそうではありません。例えば cpu を使用するルーチンと cuda を使用するルーチンが接続された場合、通常はふたつ目の計算の前にデータを GPU に転送する必要があります。この転送時間を考慮しないと、転送処理が何度も入るような非効率なルーチンパスが選択される危険性があることが分かります。この例のようにデバイスが変わるとき以外に、データの型が変わるときや、データレイアウトが変わるときに、それぞれ変換が必要です。SoftNeuro では、このようなルーチン間の整合化処理を行う adapt ルーチンを、ルーチンパスに挿入します。整合化処理を考慮したチューニングを行うため、必要になりうる adapt ルーチンの処理時間も、すべてプロファイリングの工程で計測されます。
チューニングアルゴリズム:DPRS
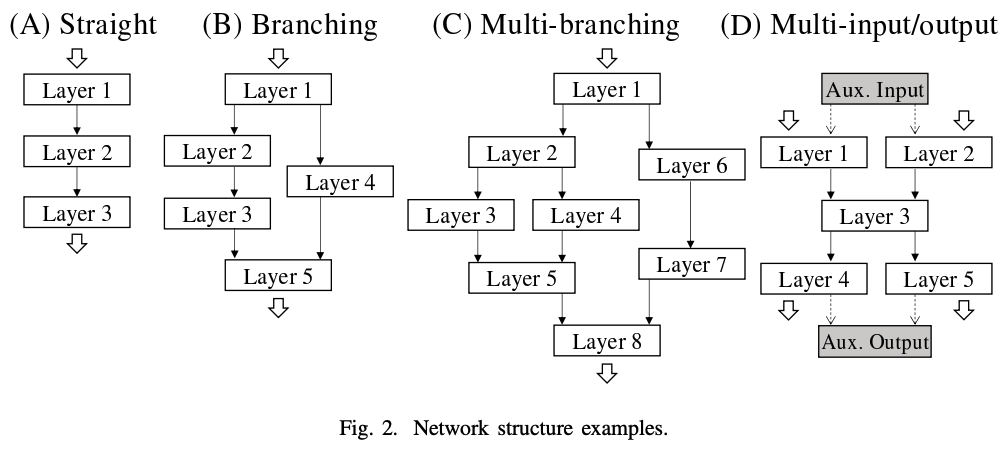
プロファイリングで得られた計測情報をもとに、最速なルーチンパスを探索する工程をチューニングと呼びます。可能なすべてのルーチンパスを全探索する方法は、組み合わせ爆発を起こしており実行不可能です。そこで我々は、動的計画法を用いて効率的に探索する手法 DPRS を提案しました。 論文ではアルゴリズムの挙動を、(A) 直列ネットワーク、(B) 分岐ネットワーク、(C) ネストされた分岐ネットワーク、(D) 複数入力・複数出力ネットワークに分けて段階的に説明しています。
直列ネットワークの場合は、レイヤー i までの最速ルーチンパスが次の三つから求まります:(1) レイヤー i-1 までの最速ルーチンパス、(2) レイヤー i のルーチン処理時間、(3) adapt ルーチンの処理時間。このような漸化式を利用することで、全体として最適なルーチンパスを求めます。ネットワークが分岐する場合では、分岐点でのルーチンごとに動的計画法を分けて進めることで、全体として最適なルーチンパスを求めることができます。ただし分岐がネストした場合、すべての分岐点のルーチンごとに動的計画法を分ける必要はなく、合流点で変数を統合することで無駄な計算を省く工夫が行われています。最後に、複数入力・出力のネットワークでは、補助入力・出力レイヤーを加えることで単一入力・出力ネットワークに変換することができます。論文では、これらを一般化した疑似コードが与えられています。 DPRS の計算量は、直列ネットワークの場合 O(レイヤー数×ルーチン数)となり、実行可能であることがわかります。
結果とビジネス応用
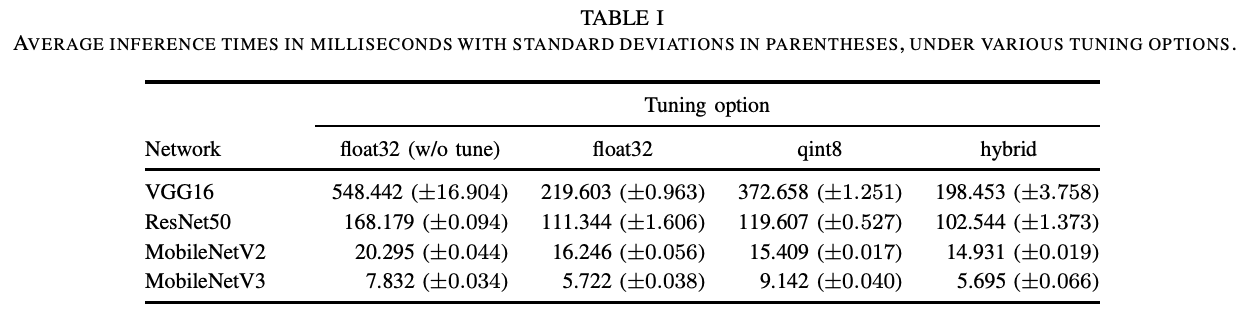
我々は、DPRS による自動最適化を搭載したマルチプラットフォーム推論フレームワーク SoftNeuro を開発しました。以下では SoftNeuro の推論速度についての実験結果を示します。まず自動最適化による効果を調べるために、Snapdragon 835 上で VGG16, ResNet50, MobileNetV2/V3 を各オプションで推論させた処理時間をまとめました。この実験では CPU で計算することとし、float32 での推論と、8 ビット量子化での推論、および両方とも用いて自動最適化した場合の推論を比較しました。この場合、型変換処理を行う adapt ルーチンを考慮した DPRS が行われます。期待した通り、両方とも用いて自動最適化した場合が最も速いことがわかりました。
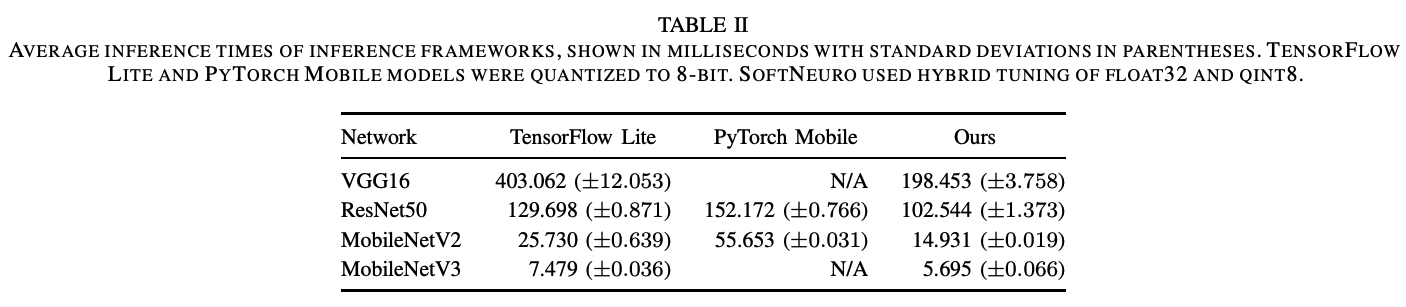
同じ4つのモデルを、モバイル向け推論エンジンである TensorFlow Lite と PyTorch Mobile で推論させた処理時間との比較をまとめました。既存手法に比べて、VGG16 でおよそ 2.0 倍の高速化を実現し、そのほかのモデルについても SoftNeuro が最も速い推論速度を示しました。
SoftNeuro は、主要なレイヤーについて Intel/ARM CPU, GPU, DSP に最適化されたルーチンを持っており、サーバーだけでなく、エッジデバイスを含む様々なプラットフォームで使用できます。C/Python API, CLI ツールを備えているため、幅広い開発環境で利用しやすく、また、学習フレームワーク PyTorch, TensorFlow, Keras からのモデルインポート機能を備えているため、導入もしやすくなっています。ビジネス応用の実績としては、深層学習モデルを使用したスマートフォン向け自社製品の内部エンジンとして採用されているほか、最近では単体での採用も進んでいます。
考察
本研究では、
- レイヤーとルーチンの概念の分離
- プロファイリングとチューニングという二段階の最適化
- グラフ構造上でルーチンパスを最適化するアルゴリズム DPRS
- DPRS を搭載したマルチプラットフォーム推論フレームワーク SoftNeuro の開発
というアプローチによって、一般的な画像処理モデルをエッジデバイス上で高速化することができました。今後は DPRS を発展させ、精度保証付き、メモリ使用量制限付きの最適化問題を解くことなどを考えています。
お知らせ
ただいま企業様・アカデミア・一般向けに SoftNeuro 非商用版ライセンスの無料トライアルキャンペーンを行っています。詳しくは、専用ホームページをご覧ください。これからも進化を続ける SoftNeuro にご期待ください!
本稿の著者情報
株式会社モルフォ CTO室リサーチャー 三宅 博史



この記事に関するカテゴリー


