深層生成モデルの学習に大きな計算機はもう必要ない!?バイナリー深層生成モデル
3つの要点
✔️ 深層生成モデルのアーキテクチャとして初めてバイナリーニューラルネットワークを採用し、画像の生成に成功
✔️ 従来のバイナリーニューラルネットワークにおいて用いられてきたバッチ正規化の効果を深層生成モデルにおいても享受するため、重み正規化を二値化した"Binary weight normalization"を提案
✔️ 深層生成モデルのアーキテクチャとして利用されてきた活性化関数や残差結合を、性能を損なうことなく二値化することに成功
Reducing the Computational Cost of Deep Generative Models with Binary Neural Networks
written by Thomas Bird, Friso H. Kingma, David Barber
(Submitted on 26 Oct 2020 (v1), last revised 3 May 2021 (this version, v2))
Comments: ICLR2021
Subjects: Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
画像などの高次元なデータを生成する深層モデルは高い表現力が求められ、そのような深層生成モデルの訓練には高い計算コストがかかります。
今回ご紹介する論文では、「バイナリーニューラルネットワーク」というネットワークの重みが二値化されたアーキテクチャを用いることで、モデルの性能を害することなく計算コストを大幅に削減しています。本稿では背景としてバイナリーニューラルネットワークについて簡単に述べた後、論文内で紹介されていた手法について詳しくご紹介します。
バイナリーニューラルネットワークとは
バイナリーニューラルネットワークとはネットワークの重みが{-1, 1}の二値で表されるようなニューラルネットワークです。重みを二値化することによって本来32 bitで保持する必要のあったパラメータをたった1 bitで保持することが可能になります。
それだけでなく、重みを二値化するだけで学習スピードを2倍高速化でき、層への入力を二値に限定すればさらに29倍もの高速化が望めるという研究報告があります。このように、バイナリーニューラルネットワークはメモリ効率化と学習効率化の二つの観点から優れたアーキテクチャとなっています。
しかし、重みを二値化することには欠点もあり、モデルの表現力の低下や最適化における困難などが欠点として挙げられます。
一般的に、バイナリーニューラルネットワークでは重みと各層の入力に対して二値化が行われます。層への入力の二値化には、一つ前の層の出力に対して符号関数を適用します。符号関数とは以下の式で表される関数のことを指します。
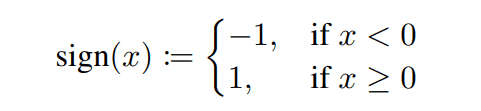
重みパラメータの二値化には、実数値で表される隠れパラメータに対して符号関数を適用します。一般的に、最適化の際には二値の重みを直接最適化することはせずに、この隠れパラメータの最適化を行います。
深層学習においては勾配ベースの最適化手法が用いられますが、符号関数はほとんどの場所で傾きがゼロであるために学習が困難です。そこで、straight-through estimator(STE)という手法を用いて以下のように近似します。
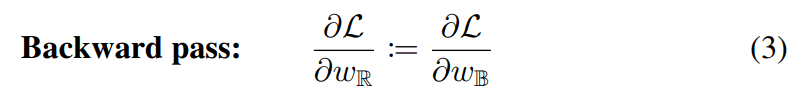
勾配が非常に大きくなってしまった場合にそれをキャンセルする手法が有効であることが知られており、これを踏まえると以下のようにクリッピングされた重みパラメータの更新式が得られます。
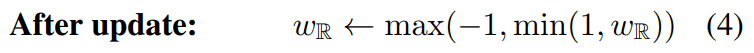
対象となった深層生成モデル
上述したバイーニューラルネットワークを用いて実装が行われた深層生成モデルはHierarchical VAEとFlow++です。モデルの詳しい説明は他の記事に譲りますが、後に紹介するバイナリーニューラルネットワークによる変更は各生成モデルの目的を変えるものではなく、あくまでもアーキテクチャにおける変更であることに注意してください。
後述する二値化手法では深層生成モデルで利用される「重み正規化」と「残差結合」に焦点が当てられています。
バイナリー深層生成モデル
深層生成モデルにバイナリーニューラルネットワークを用いるうえで、本論文が提案している二値化手法が二つあります。
それぞれ「重み正規化の二値化」と「残差ニューラルネットワークの二値化」です。一つずつ説明していきます。
重み正規化の二値化
深層生成モデルではバッチ正規化の代わりにしばしば重み正規化という手法が用いられます。上で紹介したHierarchical VAEやFlow++でも用いられています。重み正規化の式は以下のように表せます。ここで式中の$v$を二値化することを考えます。
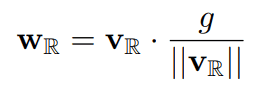
$v$を二値化すると式中のユークリッドノルムは次元数$n$の平方根で書くことができます。すなわち、重みのノルムを計算する必要がなくなり、計算時間を短縮することができます。
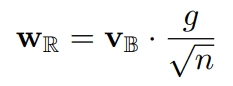
また、二値化した重み正規化では実際に行われる操作は$\alpha=gn^{-1/2}$という係数をかけるのみです。従って、二値の重み正規化を伴う畳み込み演算は、二値化された重みを用いて畳み込みを行った後に係数$\alpha$をかける操作に相当します。
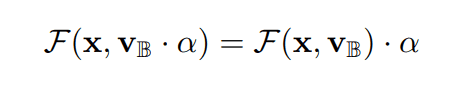
残差ニューラルネットワークの二値化
深層生成モデルのアーキテクチャに頻繁に登場する構造として残差結合が挙げられます。
残差結合とは以下の関係式で表されるようなスキップコネクションの構造を持つアーキテクチャのことです。残差結合は、層が深くなると精度が落ちてしまうという劣化問題に対して、勾配消失を起こさずにモデルの表現力を上げるという目的で研究されてきました。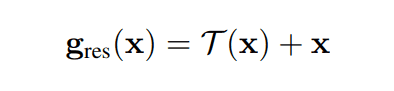
筆者らは二値化の対象として残差結合のみを選択しており、理由として以下の点を挙げています。
- 生成モデルでは特に高い表現力を必要とされるが、原則として二値化すると表現力が低下してしまう点
- 生成モデルではデータ点の尤度がモデルの出力に敏感であり、二値化するとモデルの出力が大きく変動してしまう点
- 残差結合を二値化しても恒等関数が学習可能であるという性質は維持される点
特にFlow++に代表される正規化流ベースの生成モデルにおいては学習する関数に逆変換が存在することを条件とするため、ネットワークに用いる残差結合が簡単に恒等写像を表現できることは重要なポイントになります。
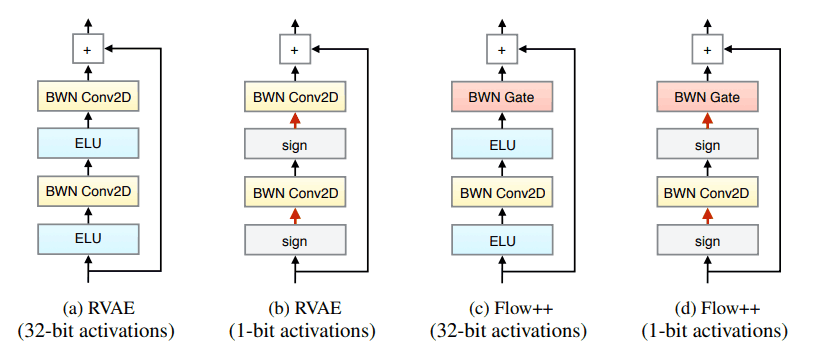
実際に実験に用いられた残差結合のアーキテクチャは以下のようになっています。入力が実数ベクトルである場合と二値ベクトルである場合で二種類存在し、それぞれ活性化関数としてELUと符号関数を用いています。従来の残差結合で用いられていた畳み込み層はBWN畳み込み層に置き換えられています。
画像生成実験
実際にバイナリーニューラルネットワークを用いても深層生成モデルの学習がうまく行えることを確認するため、CIFARとImageNetにおいて画像生成の実験を行いました。用いた生成モデルはResNet VAEとFlow++の二つです。
以下の表は各データセットでモデルの学習を行った際の損失を比較したものです。表中の32-bitは実数での実装を、1-bitは二値化による実装を示しています。また、increased widthという項目はResNetにおけるフィルター数を増やした場合(256⇒336)の結果となっています。
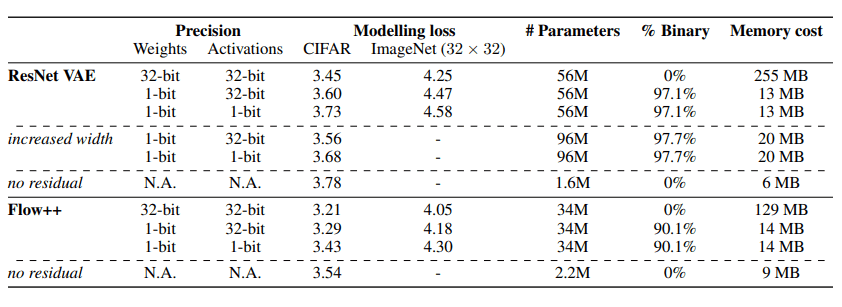
残差結合における重みを二値化した場合の結果は実数の重みを用いる場合と比較して多少悪化していることがわかります。しかし、いずれのモデルにおいても二値化によってメモリコストが1/10~1/20にまで削減されています。
この結果から、二値化によるメモリ効率化と性能のトレードオフがあることがわかります。
メモリコストが大幅に減少したことによって、より大きなネットワークサイズのモデルを学習させることができるようになりますが、increased widthの結果を見るとわかるように、二値重みの数を増加させても性能の向上は観測できませんでした。
実際に生成された画像は以下のようになっています。左が実数の重みを用いた従来のモデル、右が二値重みを用いたモデルです。二値化モデルの生成画像は従来モデルに劣らないことがわかります。


まとめ
いかがだったでしょうか。本論文の主旨は深層生成モデルの学習におけるメモリ効率の改善というシンプルなものですが、メモリコストが1/10になるというのは驚きでした!これからはPCやスマホなどで大規模な生成モデルを学習させることが可能になるかもしれません。
今後PyTorchやTensorFlowなどと同じように安定的に使えるバイナリーニューラルネットワークのフレームワークが出てくることに期待したいです。 





この記事に関するカテゴリー
