教師なし継続学習!
3つの要点
✔️ 教師なし継続学習の研究
✔️ 破局的忘却を防ぐLUMPを提案
✔️ 教師なし継続学習の教師付き継続学習に対する優位性を実証
Representational Continuity for Unsupervised Continual Learning
written by Divyam Madaan, Jaehong Yoon, Yuanchun Li, Yunxin Liu, Sung Ju Hwang
(Submitted on 13 Oct 2021 (v1), last revised 15 Oct 2021 (this version, v2))
Comments: ICLR2022
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
継続学習(Continual Learning)は、以前に獲得した知識を忘れることなく、一連のタスクを学習することを目標としており、深層学習の重大な問題である破局的忘却に取り組む研究分野です。しかしながら、この分野は活発に研究されているものの、既存の手法は教師付き継続学習(Supervised Continual Learning:SCL)に偏っています。そのため、高品質なラベルを得ることが困難な実世界において、こうした手法を適用することは実用的ではないかもしれません。
この記事で紹介する論文では、ラベル付けされていない一連のデータについて、破局的忘却を回避しながら表現学習を行う、教師なし継続学習(Unsupervised Continual Learning:UCL)に焦点を当てた研究を行いました。
その結果、UCLモデルがSCLモデルと比べ、破局的忘却や分布シフトに対してよりロバストである等の優れた性質を有することが示されました。また、UCLにmixupを適用した、Lifelong Unsupervised Mixup(LUMP)と呼ばれるシンプルかつ効果的な手法を提案しました。(これらの貢献が評価され、この論文はICLR2022にAccept(Oral)されています。)
継続学習の問題設定について
まず、$T$個のタスク$\textit{T}_{1:T}=(\textit(T)_1,...,\textit_T)$からなる連続したデータで学習する継続学習の設定について考えます。
教師付き継続学習(SCL)の場合、タスク記述子$\tau \in \{1,...,T\}$について、各タスクは$n_{\tau}$個の例を持つデータセット$D_{tau}=\{(x_{i,\tau},y_{i,\tau})^{n_{\tau}}_{i=1}\}$からなります。
各入力ペアは$(x_{i,\tau},y_{i,\tau})\in X_{\tau}×Y_{\tau}$で、$X_{\tau},Y_{\tau})$は未知のデータ分布です。ここで、入力を埋め込みに変換する特徴表現ネットワークは$f_{\Theta}:X_{\tau}→R^D$として表されます(パラメータ$\Theta=\{w_l\}^{l=L}_{l=1}$、$R^D$は$D$次元の埋め込み空間、$L$は層の数)。また、分類器は$h_{\psi}:R^D→Y_{\tau}$となります。
このとき、SCLのクロスエントロピー損失は次の式で表されます。
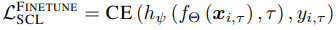
一方、論文では教師なし継続学習(UCL)に焦点を当てているため、各タスクは$U_{\tau}=\{(x_{i,\tau})^{n_{\tau}}_{i=1}\}$から構成されます。このときの目標は、一連のタスクに関する特徴表現$f_{\Theta}:X_{\tau}→R^D$を、以前のタスクの知識を保存しながら学習することになります。
学習プロトコルと評価指標
伝統的な継続学習戦略では、一連のタスクでネットワーク表現$f_{\Theta}:X_{\tau}→Y_{\tau}$を学習します。一方、教師なし継続学習設定では、$f_{\Theta}:X_{\tau}→R^D$を学習することが目的となるため、学習プロトコルは二段階になります。
- 1段階:一連のタスク$T_{1:T}=(\textit{T},...,\textit{T}_T)$について事前学習を行い、表現を獲得します。
- 2段階:K-nearest neighbor(KNN)分類器により、事前学習した表現の品質を評価します。
また、タスク$T_{\tau}$を学習した後の、タスク$i$に対するテスト精度を$a_{\tau,i}$とすると、継続学習により得られた表現の評価指標として、以下の二つを定義することができます。
- Average accuracy(平均精度):タスク$\tau$を学習するまでに完了した全てのタスクの平均テスト精度$A_{\tau}=\frac{1}{\tau}\sum^{\tau}_{i=1}a_{\tau,i}$
- Average Forgetting(平均忘却度):各タスクの最高精度と、学習完了時の精度間の平均性能低下$F=\frac{1}{T-1}\sum^{T-1}_{i=1}max_{\tau \in\{1,...,T\}}(a_{\tau,i}-a_{T,i})$
教師なし継続学習について
一連のタスクによる連続表現学習
論文では、教師なし継続学習のために、標準的な表現学習ベンチマークで最先端の性能を達成したSimSiamとBarlowTwinsを利用しています。
SimSiamについて
SimSiamは、バックボーンとProjection MLPからなるエンコーダネットワーク$f_{\Theta}$とPrediction MLP $h(\cdot)$により構成されています。
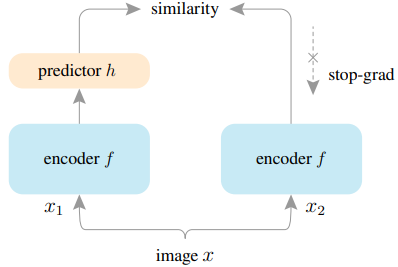
SimSiamは、二つの異なるAugmentation処理を行った画像$x^1_{i,\tau},x^2_{i,\tau}$について、ProjectorとPredictorの出力ベクトル間のコサイン類似度を最小化するように学習されます。
このとき、Predictor出力$z^1_{i,\tau}=f_{\Theta}(x^1_{i,\tau})$、Predictor出力$p^2_{i,\tau}=h(f_{\Theta}(x^2_{i,\tau}))$について、教師なし継続学習の目的損失は以下のように表されます。
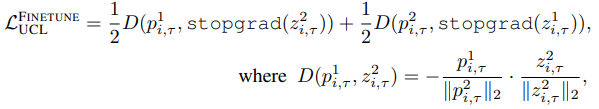
BarlowTwinsについて
BarlowTwinsは、二つの同一ネットワーク(Encoder+Projectro)の出力間で計算された相互相関行列を恒等行列に近づけるよう学習します。
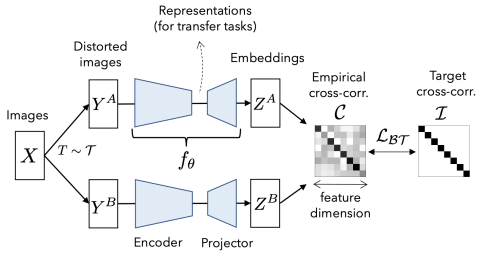
ここで、$C$を二つのネットワーク出力間の相互相関行列とすると、教師なし継続学習の目的損失は以下のように表されます。
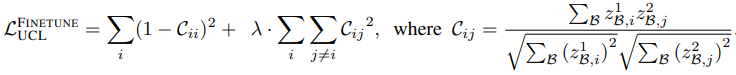
$\lambda$はトレードオフのための正の定数、$i,j$はネットワーク出力ベクトル次元を表します。
SimSiam、BarlowTwinsのどちらについても、既存の継続学習戦略にほぼ、あるいは全く変更することなく適用することができます。
既存の教師付き継続学習手法について
SimSiam、BarlowTwinsをベースとした表現学習に加え、既存の教師付き継続学習のための手法を教師なし設定に拡張した例についての実験も行います。具体的には、正則化ベース手法としてSynaptic Intelligence(SI)を、アーキテクチャベース手法(学習の進行に応じてモデルのアーキテクチャを変更する手法)としてProgressive Neural Networks(PNN)をUCLに拡張したものを導入します。
また、リハーサルベース手法(過去のデータを何らかの形で再利用する手法)として、Dark Experience Replay(DER)をUCLに拡張した場合として、以下の損失を導入します。
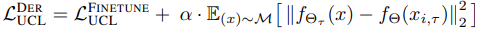
ここで、$M$はリプレイバッファにあたります。
また、リハーサルベース手法は$\alpha$の選択によって性能が大きく変化するため、論文ではこの問題の対処のためにLifelong Unsupervised Mixupを導入しています。
LUMP(Lifelong Unsupervised Mixup)
標準的なMixupでは、二つのランダムなサンプル$(x_i,y_i),(x_j,y_j)$を重み$\lambda$で足し合わせることで新たなサンプルを作成します。このとき、損失関数は以下の式で表されます。
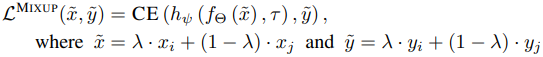
Lifelong Unsupervised Mixup(LUMP)では、以前のタスクでリプレイバッファに保存された例をMixupに利用して学習を行います。
つまり、現在のタスクの例$(x_{i,\tau} \in U_{\tau})$と、リプレイバッファからサンプリングされた例について、以下の式で表される補間インスタンス$\tilde{x}{i,\tau}$を作成します。
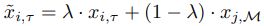
ここで、$x_{j,M}~M$はリプレイバッファ$M$からサンプリングされた例を示します。このようにして得られた$\tilde{x}{i,\tau}$をサンプルとして利用し、$L^{FINETUNE}_{UCL}$を最小化するよう学習を行います。
実験設定
ベースライン
実験では、様々な教師付き/教師なし継続学習手法の比較を行います。
SCL(教師付き継続学習)
- FINETUNE:正則化・エピソード記憶なしで一連のタスクを学習します。
- MULTITASK:完全なデータでモデルの学習を行います。
- 正則化ベースの手法:SI、AGEM
- アーキテクチャベースの手法:PNN
- リハーサルベースの手法:GSS、DER
UCL(教師なし継続学習)
教師なし継続学習では、SimSiam、BarlowTwinsを利用して表現学習を行います。このとき、以下のように複数の変種について実験を行います。
- FINETUNE:教師付きの場合と同様
- MULTITASK:教師付きの場合と同様
- 正則化ベースの手法:SI
- アーキテクチャベースの手法:PNN
- リハーサルベースの手法:DERの教師なしのための拡張
データセット
実験に用いるデータセットは以下の通りです。
- Split CIFAR-10
- Split CIFAR-100
- Split Tiny-ImageNet
学習と評価の設定
SCLの学習時については、先行研究のハイパーパラメータ設定に従っています。UCLはこれを調整したものを利用し、3回の独立した実行についてKNN分類器によって評価を行います。
UCL手法は200エポックにわたり訓練されます。また、各データセットごとのハイパーパラメータ設定は以下の通りです。

実験結果
実験の結果は以下の表の通りです。
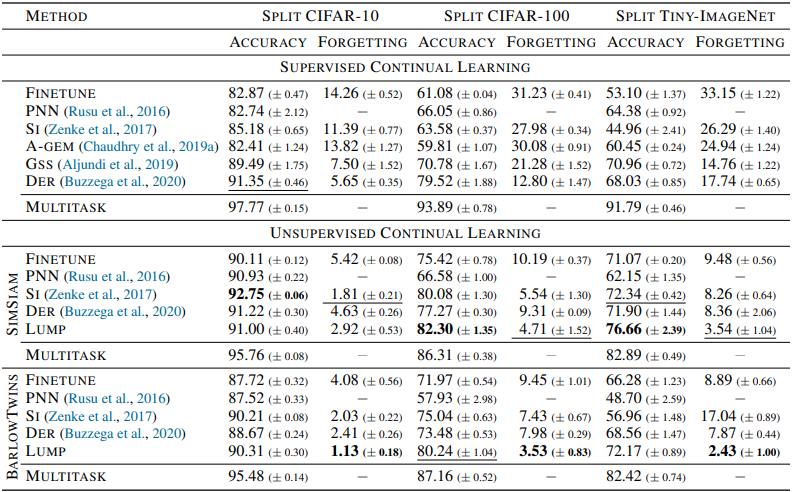
総じて、教師なし継続学習(UCL)は、教師付き継続学習(SCL)の結果と比べ、高い精度・低い忘却率を示しました。
興味深いことに、正則化などの追加手法を用いていないUCL-FINETUNE設定であっても、教師付き継続学習と比べて有意に良好な結果を示しました。また、論文にて提案されたLUMPは、その他のベースラインと比べて有意に優れた性能を示しました。さらに、各タスクのデータセットサイズが少ない場合(few-shot)の結果は以下の通りです。
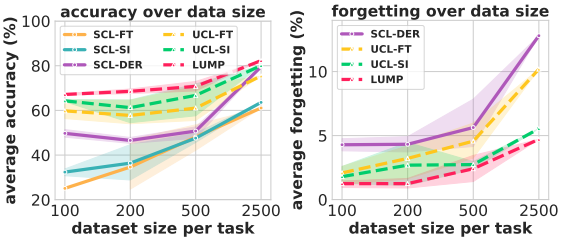
総じて、教師なし手法は教師付きと比べ、特にデータサイズが小さい場合の精度・データサイズが大きい場合の忘却度について、有意に優れた結果を示しました。また、提案手法のLUMPは、精度・忘却度ともに優れた性能を発揮しています。また、OOD(Out of Distribution)データに対する各手法の結果は以下の通りです。
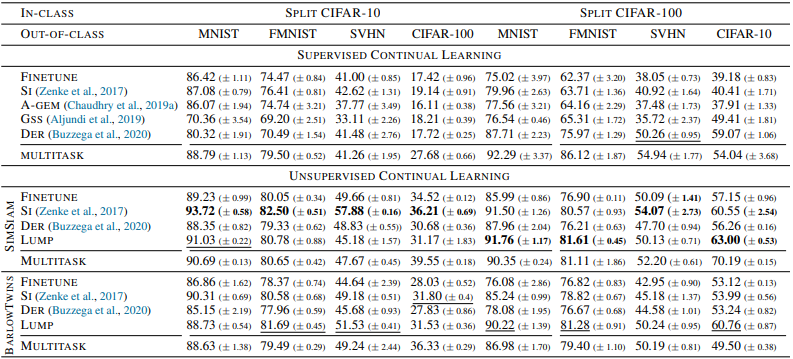
総じて、教師なし継続学習の表現は教師付き設定を上回っていることが示されました。
まとめ
この記事では、教師なし継続学習に取り組んだ研究について紹介しました。この論文では、教師なし継続学習により得られた表現が教師付き継続学習と比べてロバストであることを実験により実証し、破局的忘却を抑えるための手法であるLUMPを提案しました。実験に用いられた画像タスクの解像度が限られている点などの課題はあるものの、教師なし継続学習に関する有益な結果が示されました。






この記事に関するカテゴリー




