
Domain Adaptationモデルを教師なしでチューニングする
3つの要点
✔️ 教師なしDomain Adaptationは、ターゲットデータに対して高い予測性能を持つ一方で、教師データがないため、ハイパーパラメータのチューニングが難しい
✔️ 本論文では、同じクラスのターゲットデータは識別器によって互いに近傍に埋め込まれるという仮定の下、新規評価指標のSoft Neighborhood Density(SND)を考案した
✔️ SNDは、従来の手法に比べてシンプルであるにも関わらず、画像認識とセグメンテーションの両方でより効果的であることが分かった
Tune it the Right Way: Unsupervised Validation of Domain Adaptation via Soft Neighborhood Density
written by Kuniaki Saito, Donghyun Kim, Piotr Teterwak, Stan Sclaroff, Trevor Darrell, Kate Saenko
(Submitted on 24 Aug 2021)
Comments: ICCV2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
ディープニューラルネットワークは、画像認識において非常に高精度な特徴量を学習することができる一方で、ドメインが異なると性能を保つことができません。これを改善するために、教師なしDomain Adaptation(UDA)が研究されてきました。UDAは、十分な教師データを持つソースデータから、教師データを持たないターゲットデータの特徴量学習を行います。近年ではさまざまなUDA手法が開発され、画像認識・semantic segmentation・物体認識で高い性能を示してきました。しかしながら、UDAはハイパーパラメータやトレーニングのイテレーション数によって大きく性能が変わり、評価が重要となります。UDAではターゲットの教師データがないので、どのようにハイパーパラメータチューニング(HPO)すれば良いでしょうか?
従来の効果的な手法として、分類エントロピー(C-Ent)があります。もし分類器が出力に自信を持っていて低エントロピーならば、ターゲットデータの特徴量は識別しやすく、信頼の高いクラス分類になるはずです。しかしC-Entは、下図のように分類器が、ターゲットデータの一部を自信を持って別のクラスに分類してしまうケースでも低い値となります。
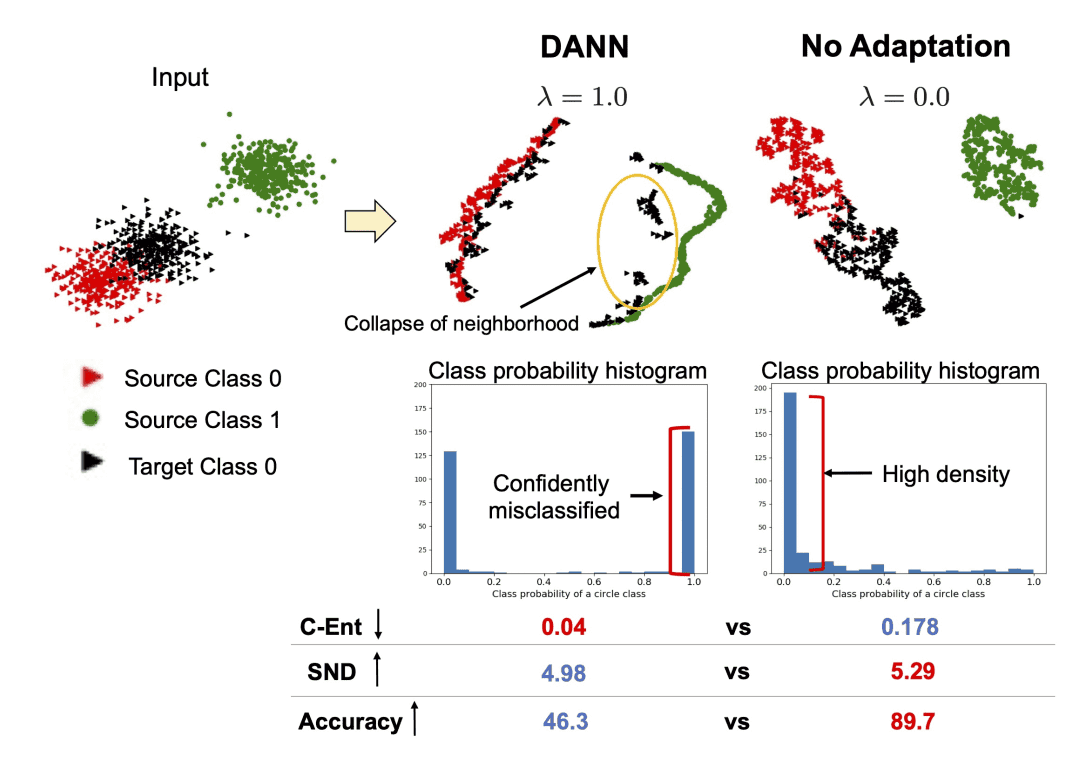
そこで本論文では、十分に学習したモデルは同じクラスのターゲットデータを近くに組み込み、高密度の近傍点を形成するという仮定の下、Soft Neighborhood Density(SND)を定義しました。SNDは近傍の密度を計算することによってターゲットデータの特徴量の識別しやすさをシンプルに測っています。
問題設定
ソースデータを$D_s=\{({\bf x}_i^s, y_i^s)\}_{i=1}^{N_s}$, ターゲットデータを$D_t=\{({\bf x}_i^t)\}_{i=1}^{N_t}$とすると、UDAのlossは一般に
$$L = L_s(x_s, y_s)+\lambda L_{adapt}(x_s, x_t, \eta)$$
と書けます。ここで$L_s$はソースデータのクラス分類loss, $L_{adapt}$はターゲットデータの適応loss, $\lambda$はトレードオフパラメータ, $\eta$は$L_{adapt}$を計算するためのハイパーパラメータです。我々の目的は$\lambda$, $\eta$, トレーニングイテレーション数を最適化する評価指標を見つけることです。
Soft Neighborhood Density(SND)
SNDの導出は、下図のように1)Similarityの計算、2)Soft Neighborhoodsの計算、3)SNDの計算の3ステップからなります。

Similarity
まず、ターゲットサンプル$S\in \mathbb{R}^{N_t\times N_t}$からsimilarityを計算します。ただし$N_t$はターゲットサンプル数です。${\bf f}_i^t$を$L_2$ノルム化したターゲットデータ$\bf{x}_i^t$の特徴量として、$S_{ij}=<{\bf f}_i^t, {\bf f}_j^t>$を要素とするSimilarity行列Sを定義します。ただし対角成分は不要のため無視します。行列$S$は距離を定義しますが、サンプル間が相対的にどれくらい離れているかを知るのは不明瞭です。
Soft Neighborhoods
次に、サンプル間の距離を強調するために、Softmax関数を用いて確率分布に変換します。
$$P_{ij}=\frac{\exp{(S_{ij}/\tau})}{\sum_{j'}\exp{(S_{ij'}/\tau})}$$
ここで$\tau$は温度パラメータで、サンプル間の距離を調整します。したがって、サンプル$j$がサンプル$i$と相対的に似ていない場合、$P_{ij}$は小さくなり、サンプル$j$を無視できます。本実験では$\tau=0.05$としました。
SND
最後に、$P$が与えられた時にneighborhood densityを考慮するメトリクスとして、$P$のエントロピーを計算します。もし$P_i$のエントロピーが大きいと、確率分布はsoft neighborhoods内で一様なはずです。つまり、サンプル$i$の近傍は非常に近い点に密集しています。
$$H(P)=-\frac{1}{N_t}\sum_{i=1}^{N_t}\sum_{j=1}^{N_t}P_{ij}\log{P_{ij}}$$
冒頭で示した図のような分布の場合、$H(P)$は小さくなるので、$H(P)$が最も大きいモデルを選択しました。また、SNDはターゲットデータの同一クラスを近傍に置くことが目的なので、${\bf f}$には、クラス情報を含んでいる分類器のsoftmax出力を用いました。
実験結果
画像分類
トレーニングイテレーション数に対するAccuracy、評価指標の推移は下図のようになりました。
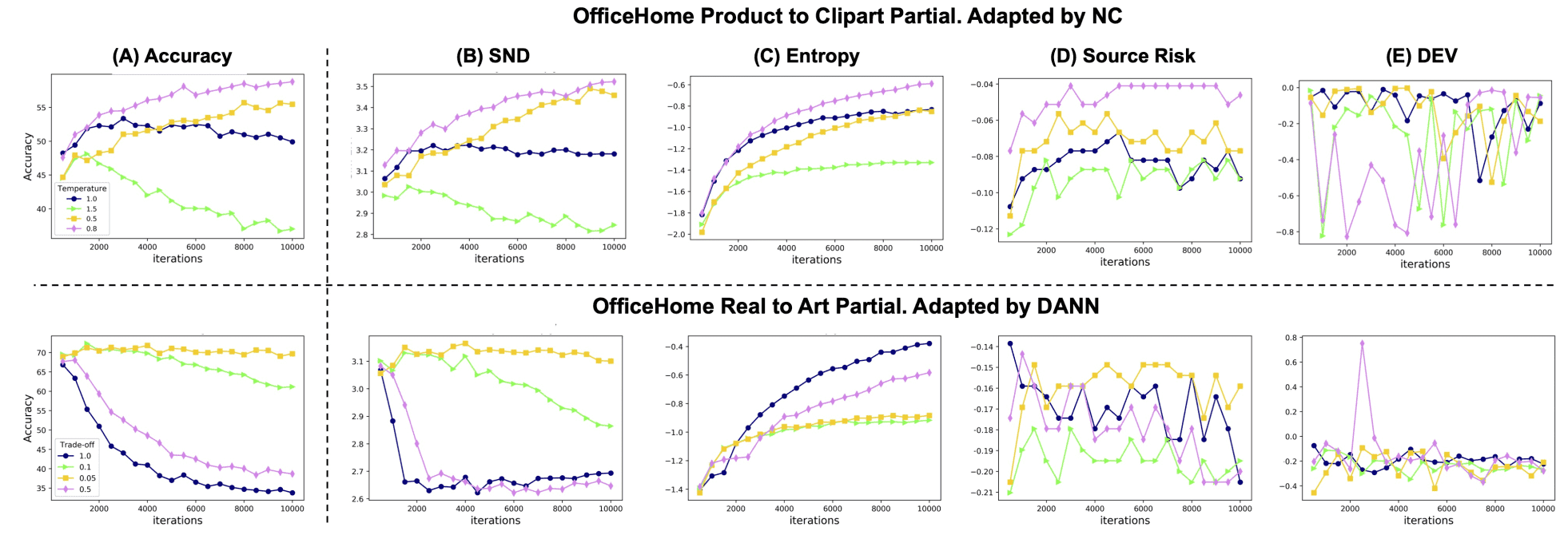 Domain Adaptation(DA)手法は、ハイパーパラメータによって大きく変動することが分かります。しかし、SNDとAccuracyのカーブは似ています。また、複数のデータセットに対して、異なるDA手法を適用した時のAccuracy結果は下表のようになりました。
Domain Adaptation(DA)手法は、ハイパーパラメータによって大きく変動することが分かります。しかし、SNDとAccuracyのカーブは似ています。また、複数のデータセットに対して、異なるDA手法を適用した時のAccuracy結果は下表のようになりました。

CDAN、MCC、NC、PLはDA手法、A2D、W2A、R2A、A2Pは異なるデータセット、Source Risk、DEV、Entropy(C-Ent)は従来の評価指標を表しています。全体的に、SNDが最も高い値を取っており、他の評価指標が著しく性能が低くなるケースがあるのに対し、SNDはほとんど劣化しません。これらのことから、SNDは様々な手法のHPOで効果的だと分かりました。
semantic segmentation
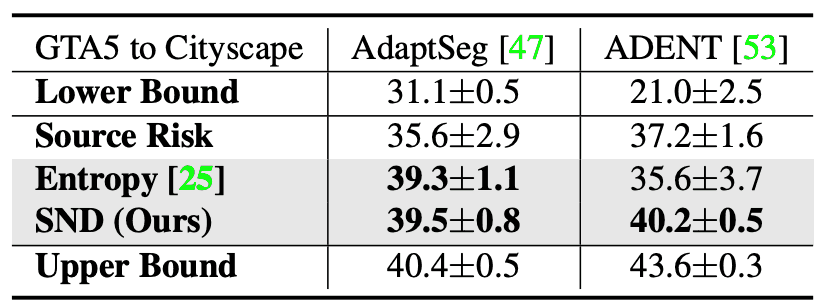
セグメンテーションの実験結果は下表のようになりました。DA手法はAdaptSegとADVENT、データセットはGTA5とCityScapeです。表の値はmean IoU(mIoU)を用いました。両手法で、SNDが高い値を取っています。
まとめ
本論文では、UDAのより良い評価指標として、ターゲットサンプルがどれくらい良くクラスタリングされるかを考慮したSNDを提案し、様々なデータセットで従来手法と比較しました。UDA手法はハイパーパラメータによって大きく性能が変わるため、HPOが極めて重要です。SNDは従来の評価指標と比べて高い性能を示しましたが、教師なしでのHPOはDA手法によっても異なり、HPOがどのように作用するかを考慮したDA手法を確立することが今後の課題です。






この記事に関するカテゴリー
