
顔検出モデルにおける顔の位置特定にバイアスは存在するのか?
3つの要点
✔️ 顔検出モデルにおける位置特定精度のバイアスを検証
✔️ 多角的なバイアスの検証のために10個の属性ラベルを付与した新しいデータセットを作成
✔️ すべて顔検出モデルで性別・年齢・肌色においるバイアスを確認
Are Face Detection Models Biased?
written by Surbhi Mittal, Kartik Thakral, Puspita Majumdar, Mayank Vatsa, Richa Singh
(Submitted on 7 Nov 2022)
Comments: Accepted in FG 2023
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
様々なサービスで機械学習が利用されていますが、機械学習モデルのバイアスは大きな問題になっています。バイアスがあると特定の属性の人たちに不利益を与え、不公平な結果を招いてしまうためです。特に、生体女情報を扱う顔認証、顔認識、顔属性予測、顔検出などは、性別や人種によって精度差があると「差別」につながる可能性があります。実際、2020年には、公共利用していた顔認識システムに、人種による精度の違いがあることが発覚し、顔関連技術を提供していた企業が次々とシステムの提供を停止しました。それ以降、顔関連技術のバイアスに関する研究は活発に行われています。
これまで、実用化が進む注目を集めている顔認証、顔認識などは研究が進んでいる一方で、顔検出はあまり研究が進んでいません。しかし、顔検出技術は、あらゆる顔関連技術のパイプラインに応用されているため、顔検出技術におけるバイアスを理解することは、さまざまな顔関連技術のバイアスの存在を明らかにすることにつながると考えることができます。
これまで行われている顔検出のバイアスに関する研究は「Face」クラスと「Non-Face」クラスのバイナリ分類として、バイアスを調査しているものはありますが、顔検出において最も重要な位置特定に関しては、研究されていません。そこで、この論文では、これまで検証されていない顔領域の位置特定の正確性の観点からバイアスを調査しています。
この論文では、多角的にバイアスの研究をするために、既存のデータベースに不足している属性データを付与して新しいデータセットを公開しています。顔の位置情報に加えて、顔ごとに10個の属性データをラベル付けしたデータセット「F2LA」を用意しています。そして、このデータセットを用いて、既存の顔検出モデルによる性別や肌色、年齢に対する検出精度のバイアスや、これら人口統計的な要因以外にバイアスに影響を与える可能性がある交絡因子を調べています。
F2LAデータセット
Fair Face Localization with Attributes(F2LA)というデータセットを作成しています。このデータセットには、1,774人分の顔が写っている1,200枚の画像が含まれ、それぞれの顔に対して位置情報と属性情報(10個)が付与されています。画像はCC-BYライセンスのものをインターネット上で収集しています。下図は収集した画像のサンプルです。

顔の位置情報、属性情報の付与は、下図のようにツールを利用しており、顔の位置を特定したのち、属性情報を付与しています。顔関連技術の研究に携わったことがある人によってアノテーションされています。下図の(a)で顔の位置を特定し、(b)で属性情報の付与をしています。

付与する属性情報は、下表のAttributeの通りです。上から順に、性別(Gender)、肌色(Skin-tone)、見かけの年齢(Apparent Age)、ぼやけ具合(Blur)、照明状況(Illumination)、顔の向き(Facial Orientation)、ひげ(Facial Hair)、隠れている部位(Occlusion)、背景(Background)、画像の色特性(Color Properties)が属性情報として付与されています。
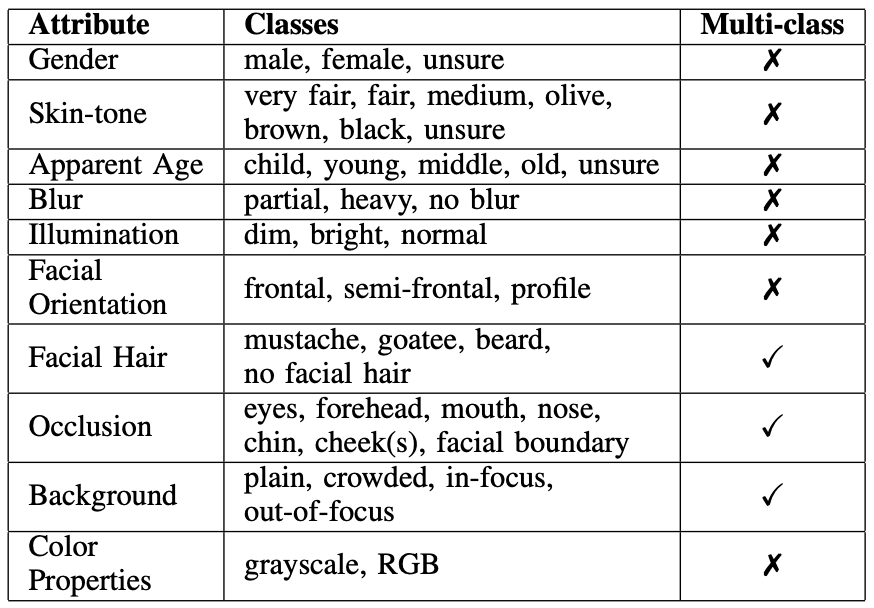
また、各属性情報の種類は、表のClassesの通りです。ちなみに、肌色(Skin-tone)では、Fitzpatrick scaleを利用しており、unsureは主にgrayscaleのために利用されています。なお、Muti-classは、特定の顔が同じ属性の複数のClassに属することができるかどうかを表しています。「✔︎」は複数のClassに属することができることを表しています。
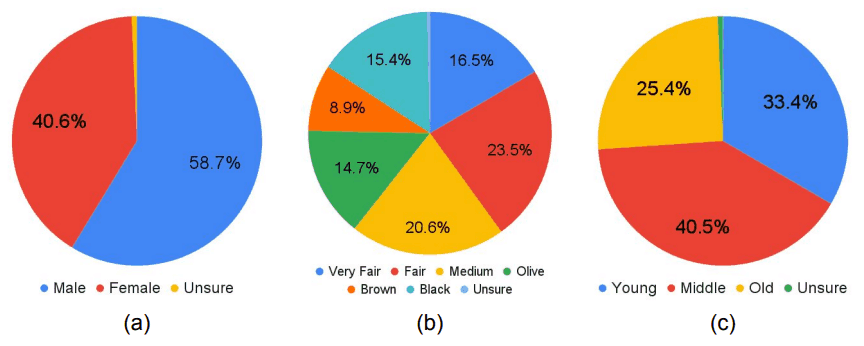
性能評価にあたっては、1,774人分の顔が写っている1,200 枚の画像を、1,486人分の顔が写る1,000枚の画像(学習データ)と、288人分の顔が写る200枚の画像(テストデータ)に分割しています。テストデータは、特に性別、肌色、見かけの年齢ができる限り均等になるように調整されています。テストデータのこれらの属性の分布は、下図のようになっています。
実験
まず事前学習済みの代表的な顔検出モデルの性能評価しています。次にF2LAによる顔検出モデルの性能向上を確認するため、F2LAの学習データでFine-tuneした結果、さらにF2LAの学習データにおいて、性別、肌色、年齢のバランスを調整したサブセットでFine-tuneした結果も評価しています。
事前学習済みの顔検出モデルには、MTCNN、BlazeFace、DSFD、RetinaFaceを利用しています。MTCNN、DSFD、RetinaFaceはWIDER FACE で学習したモデルを事前学習済みモデル(Pre-trained)として利用し、BlazeFaceはGoogleのMediaPipeで提供されているモデルを事前学習済みモデル(Pre-trained)として利用しています。
性能評価には、顔を囲う枠(Bounding Box)のIoU(Intersection over Union)を利用しています。つまり、顔検出モデルによって予測された顔の枠と、正解の顔の枠の重なり度合いを利用しています。完全に重なるとIoU=1.0になります。精度を算出する際、IoUには閾値が設定されます。例えば、閾値をIoU=0.5とすると「IoU=0.5以上の場合に、正しく顔を検出できたものとみなす」ということになります。そして、この閾値条件において、何%の顔を検出できたかを評価することになります。
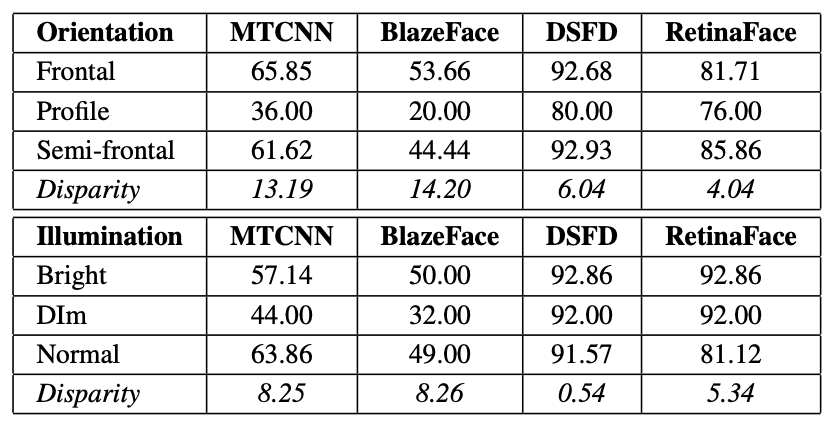
下表は、事前学習済みの顔検出モデル(MTCNN、BlazeFace、DSFD、RetinaFace)に対して、F2LAのテストデータで性能を評価した結果です。tはIoUの閾値を表しています。顔を囲う枠の重なり(IoU)が0.5以上を検出成功と見做した場合と、0.6以上を検出成功と見做した場合の精度が示されています。
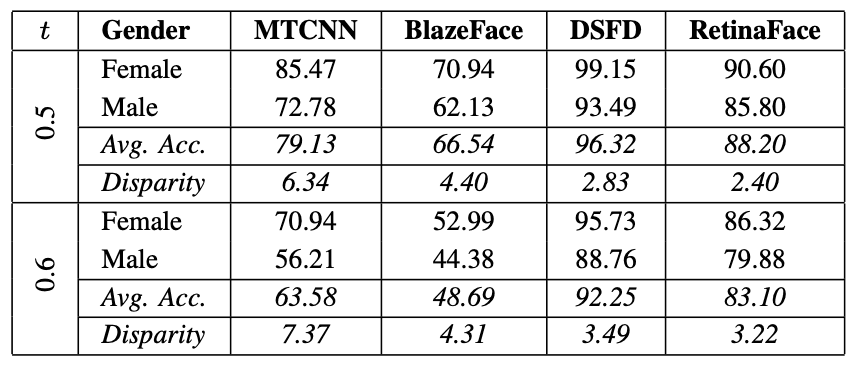
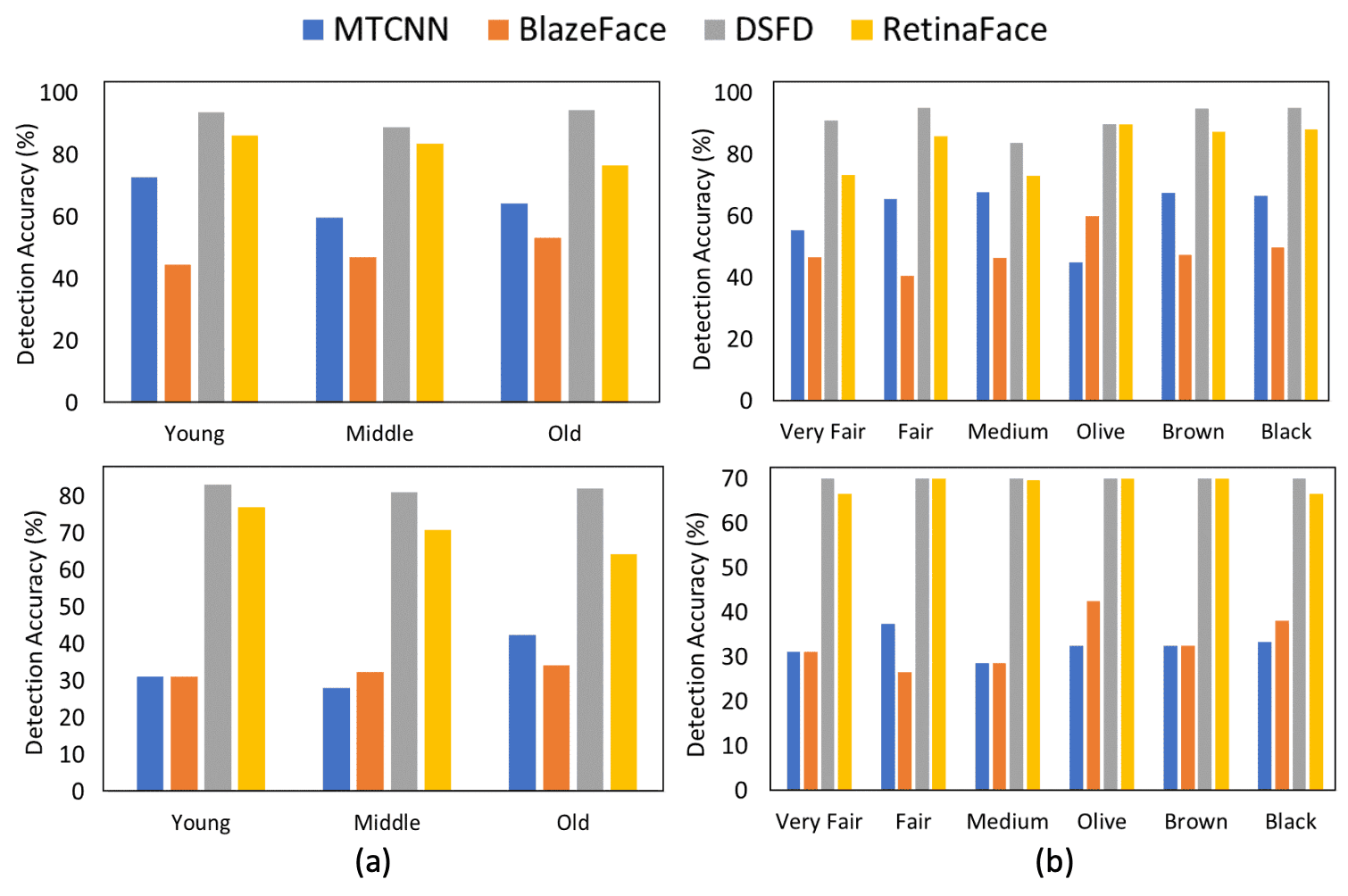
t=0.5、0.6のいずれにおいても、男性(Male)と女性(Female)の検出精度に大きな差が生じています。t=0.5の場合、MTCNNとRetinaFaceでは、Disparityが各々6.34%と2.40%になっています。すべてのモデルにおいて、一貫して男性(Male)の検出精度が低くなっています。また、年齢と肌色に関する結果は下図のようになっています。上の行はt=0.6の場合、下の行はt=0.7の場合を表しています。ここでもClassごとに性能の差が表れていることがわかります。
さらに、下図は顔の向き(Orientation)と照明条件(Illumination)に対する性能を示しています。高照度(Bright)で正面向きの顔(Frontal)は、薄暗い照明(Dim)で横顔の顔(Profile)に比べて性能が高いことがわかります。ここでもClassごとにおおよそ一貫して性能の差が表れていることがわかります。
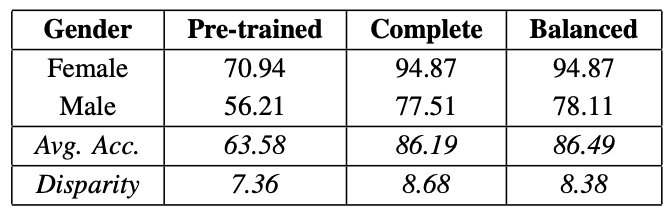
次に、F2LAの学習データを使って、各学習済みモデルをFine-tuneし、Genderごとの検出精度を調べたものが下表のCompleteです。さらにF2LAの学習データから男性(Male)と女性(Female)のバランスを調整したサブセットを用意し、Fine-TuneしたものがBalancedです。
表からわかるように、Fine-tuneによって性能が大幅に向上していることがわかります。しかし、性別(Gender)による性能の差は依然として発生しています。これは、肌色や年齢についても同じ傾向のようです。
バイアスに影響する可能性がある要因
顔検出モデルの性能に影響する要因に関して、この他にいくつかのケースを確認しています。下図はMTCNN、BlazeFace、RetinaFace において正確に顔を検出できなかった画像のサンプルです。(a)がBlazeFaceによるもの(b)がMTCNNによるもの(c)がRetinaFaceによるものです。

BlazeFaceとMTCNNのいずれも特に高齢者(old)かつ男性(male)に属する場合にうまく検出できていないことがわかります。 また、グレースケール画像に対しても検出できていないことがわかります。さらに、BlazeFaceでは顔のサイズが小さい場合が苦手なようです。一方で、RetinaFaceは顔のサイズが大きい場合が苦手なようです。
さらに、モデル性能のバイアスについて、事前学習に利用したWIDER FACEの影響についても言及しています。上述したように、MTCNN、DSFD、RetinaFaceは、WIDER FACEで事前学習しています。WIDER FACEには、顔の向き(typical、atypical)、隠れている部位(none、partial、heavy)、照明(normal、extreme)、ぼやけ具合(clear、normal blur、heavy blur)の属性が付与されおり、学習データは下図のような分布になっています。(a)は顔の向き、(b)は隠れている部位、(c)は照明、(d)はぼやけ具合を表しています。
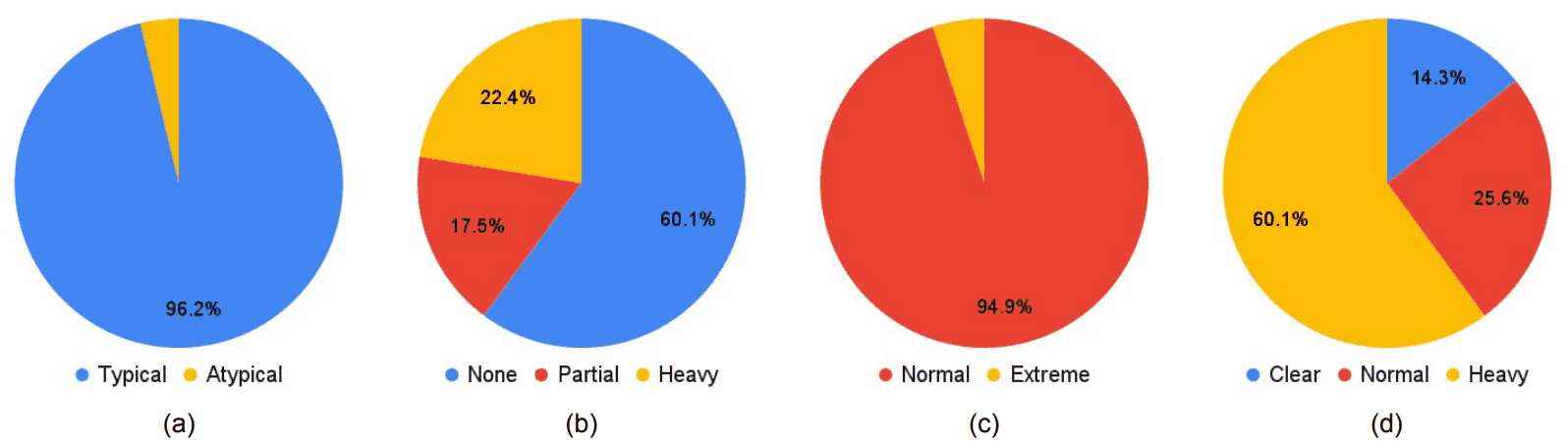
円グラフからわかるように、WIDER FACEは顔の向きがTypical、照明がNoemalに偏っていることがわかります。そして、先程示した下表からわかるように、F2LAのテストデータに対してもWIDER FACEに多く含まれていた属性(下表で、Frontal、Normal)に対して比較的高い性能を示すことがわかります。つまり、予想されるように、学習データの偏りが性能に影響を与えていると推測できます。
また、DSFDとRetinaFaceで検出された顔を目視で確認したところ、いずれの性別においても問題なく検出されているように見えました。しかし、実際は下表のように性別によって性能に大きな差が生じていました。
この点については、アノテーションは顔を囲う枠が大きめになっていた一方で、モデルが予測する枠が小さくなっていたため、IoUが小さくなってしまったことが原因の一つとしています。これは、検出する対象物が小さいほど、この影響が大きくなってしまいます。今回、男性を含む画像には、下図のように小さい顔を多数存在する画像が含まれていていました。おそらくこれも性別によって性能差が生じた原因と考えられるとしています。下図(a)が正解の枠、(b)が予測された枠です。
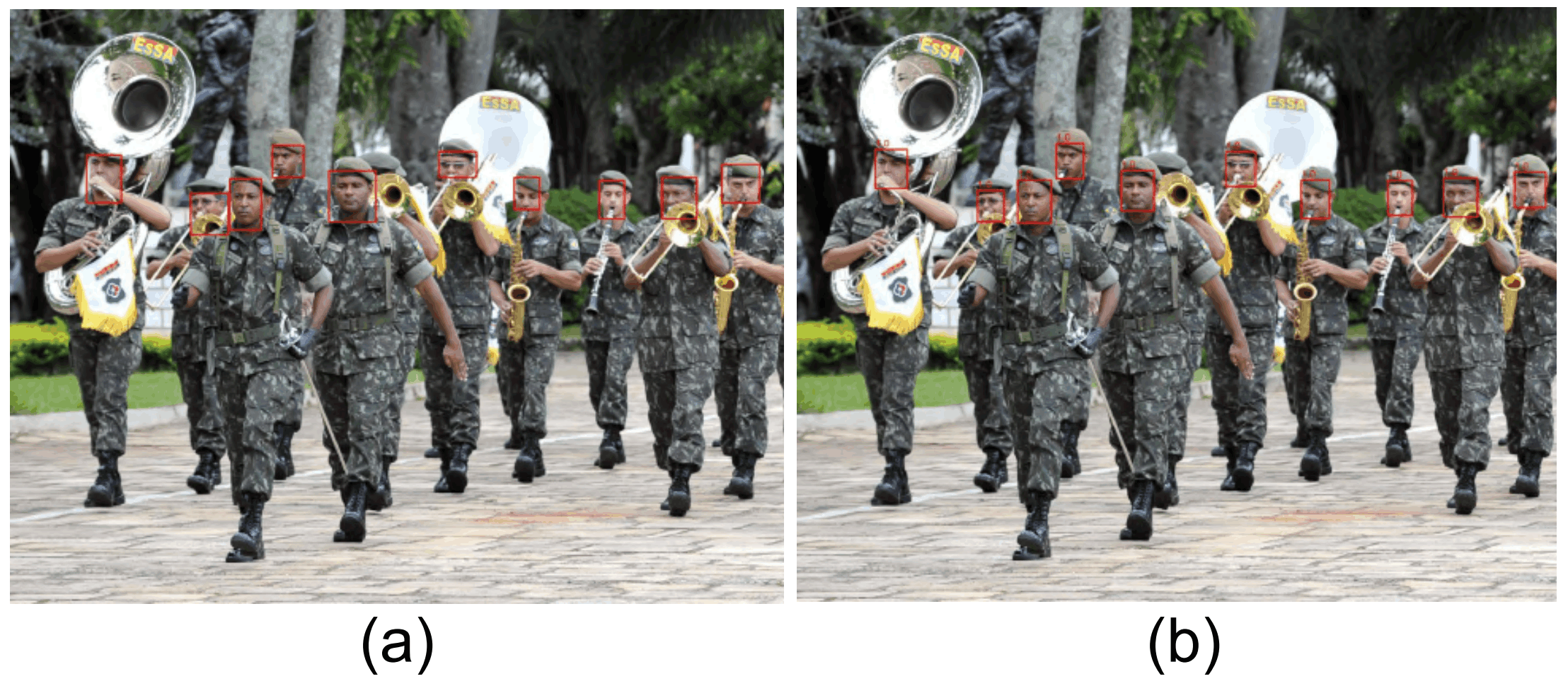
まとめ
この論文では、深層学習を用いた顔検出モデルにバイアスは存在するのか、それはどのような場合なのかを調べています。
一般的に、深層学習を用いたモデルにおけるバイアスは、人種、性別、肌色などの人口統計学的な要因だけでなく、非人口学的要因(顔の向き、顔の大きさ、照明、画質など)にも起因するとされているため、バイアスを包括的に分析するためには、既存のデータセットに不足しているさまざまな属性データの付与が必要になります。
そこで、この論文では、まずFair Face Localization with Attributes(F2LA)という新しいデータセットを公開しています。このデータセットでは、顔の位置情報だけでなく、各顔に対して10種類の属性データも付与しています。これによって、ただ単に人口統計学的な要因のバイアスを調べるだけでなく、非人口学的な要因による交絡因子についても調べることが可能になっています。
今回の論文では、正直、バイアスの要因分析は十分とは言えませんが、多様な属性データを持つF2LAが公開されたことで、今後、顔検出におけるバイアスの研究が加速することが期待されます。



この記事に関するカテゴリー






