
よりリアルで公平な顔認識向け合成データセットを提供する新しいフレームワーク「GANDiffFace」
3つの要点
✔️ GANとDiffusion Modelを組み合わせて、クラス内変動が強化されたリアルな合成データセットを構築する方法を提案。
✔️ 合成した同一人物に基づいて、2つの異なる方法(GANのみを使用した方法、GANとDiffusionを組み合わせた方法)でデータセットを構築。実世界のデータセットと比較し、有用性を検証。
✔️ GANDiffFaceで構築したデータセットを公開。
GANDiffFace: Controllable Generation of Synthetic Datasets for Face Recognition with Realistic Variations
written by Pietro Melzi, Christian Rathgeb, Ruben Tolosana, Ruben Vera-Rodriguez, Dominik Lawatsch, Florian Domin, Maxim Schaubert
(Submitted on 31 May 2023)
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
近年、顔認識システムの分野では、大規模なデータセットが次々と公開され、性能が飛躍的に向上しました。しかしながら、プライバシーの問題から公開されていたデータセットが使用できなくなることもありました。この問題に対する解決策として注目されているのが合成された顔画像によるデータセットです。実在しない人物の顔画像を生成するため、プライバシーの問題はありません。また、顔画像をコンピューターで自動生成するため、実在する人物の顔画像では入手が難しい顔画像を大規模に取得することができます。しかしながら、これらの方法にも、実在する人物ほどリアリティがない、人種の分布に偏りがあるなどの欠点があります。
今回紹介する論文では、GANとDiffusion Modelを組み合わせた「GANDiffFace」という新しい合成データセットを作るフレームワークを提案し、既存の合成データセットの問題を解決しようとしています。GANDiffFaceでは、まずGANを使って本物に近い顔画像を生成し、さらに様々な人種のデータを均等に含むようにします。その後、Diffusion Modelを使って、GANで作った画像を元に、同じ人物に対して、様々なアクセサリーやポーズ、表情、背景を加えた様々な画像を生成しています。
さらに、GANDiffFaceで構築したデータセットを、実際の顔画像で構築したデータセット(例えばVGG2やIJB-C)と比較し、その有用性を検証しています。
下図は、GANとDiffusion Modelを組み合わせたGANDiffFaceの概要です。GANDiffFaceでは、GANベースのモジュールで合成された各人物に対して、パーソナライズされたDiffusion Modelベースのモジュールが、リアルなクラス内変動を持つ多様な画像を生成し、それらがフィルタリングされた後、最終的なデータセットととして加えられています。
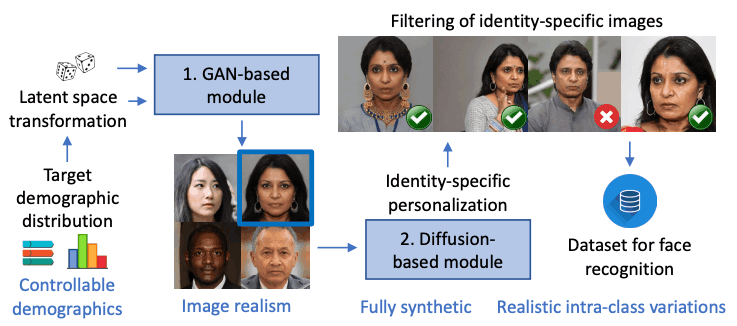
GANDiffFaceとは
GANDiffFaceフレームワークは下図のようになります。GANDiffFaceは2つのモジュールで構成されています。1つ目は、GANベースのモデルです。ここではStyleGAN3を用いて顔画像を生成しています。2つ目は、Diffusion Modelベースのモデルです。ここでは、DreamBoothを使って、実際にありそうなクラス内の変動(同一人物の異なる表情やポーズなど)を生成しています。
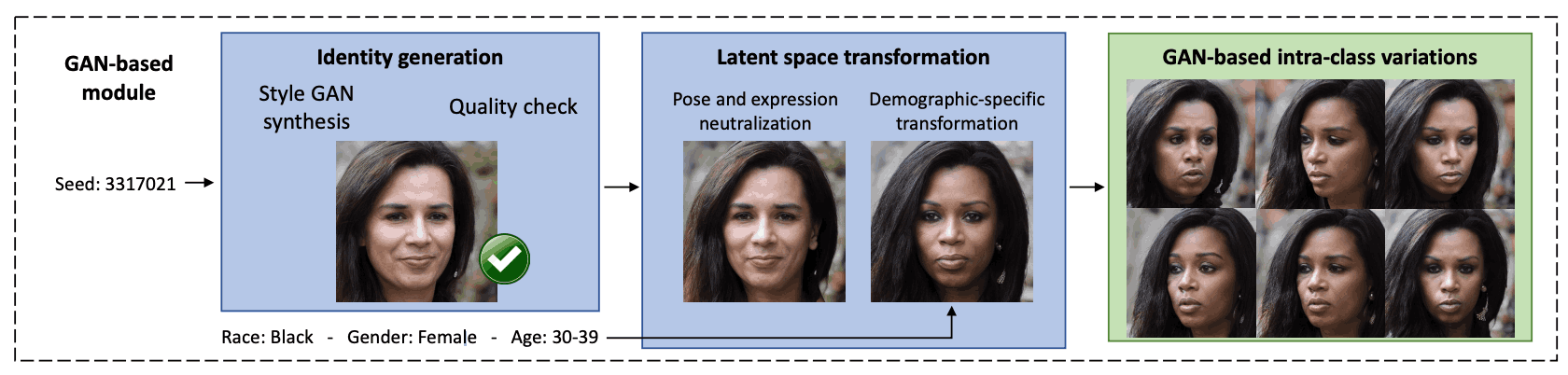
まずGANベースのモジュールでは、まず人物の顔画像の生成を行なっています。ここではStyleGAN3を用いて、256,000枚の合成画像を生成します。これらの画像は、人種、性別、年齢といった人口統計属性に関して、FairFaceという分類器でラベル付けされます。しかし、下図に示すように、StyleGAN3で生成されたランダムな画像セットには偏りがあるため、品質の悪い画像や若い被写体の画像は除外しています。品質評価にはMagFaceというシステムを使用し、最低品質の10%の画像を取り除いています。
次に、StyleGANによって学習された顔の潜在的な表現を解釈するために、異なる属性を編集するための法線ベクトルを見つけるため、サポートベクターマシン(SVM)が学習されます。これにより、笑顔や驚きなどの表情や、人種や性別などの属性を変更することができるようになります。これらの属性に基づいて合成データセットにラベルを付け、その後、SVMを使用して属性を変更するための潜在ベクトルの方向を定義しています。
最後に、潜在ベクトルを変換して顔画像の属性を変更しています。これは、画像を表す潜在ベクトルに変更を加えることで、例えば特定の表情や照明条件を追加したり、性別や年齢などの属性を変えることができます。変更を加えるには、単純に潜在ベクトルに変換を適用しています。
これらの操作を組み合わせることで、最終的にターゲットとなる人口統計グループを代表するような多くの異なる人物画像が生成され、同時に顔画像のクラス内変動(同一人物の異なる画像のバリエーション)も得られるようになります。
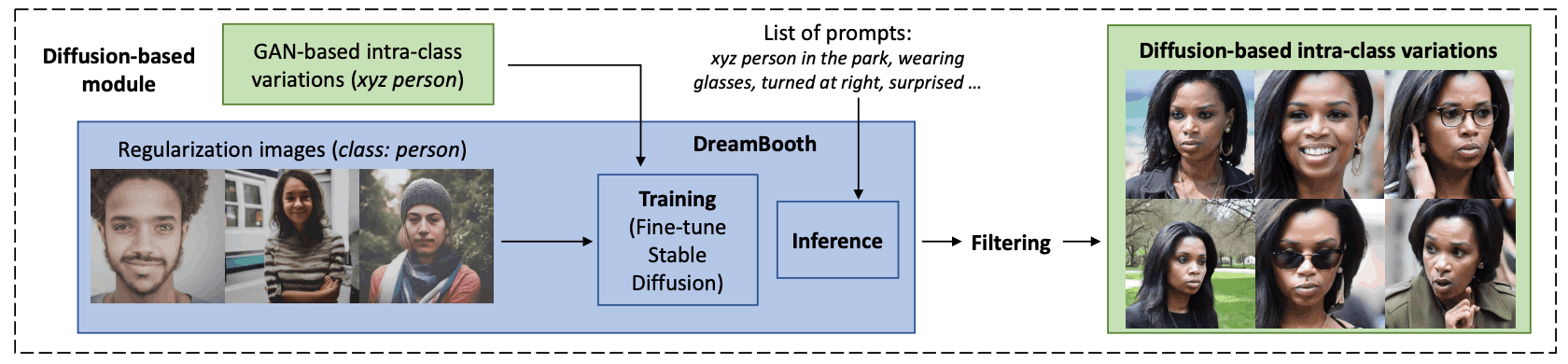
次に、テキストをもとに画像を生成するDiffusion Modelベースのモジュールで処理されます。このモジュールは3つのステップに分かれています。
1つ目は学習です。ここでは、GANベースのモジュールで生成された画像を使い、テキストから画像を生成する「Stable Diffusion」をファインチューニングします。次に、DreamBoothという技術を適用し、一意の識別子(Token xyz)を特定の合成した人物に紐付けます。このモデルを使用する際は、「xyz person」のようなテキストプロンプトを使い、合成された人物を特定します。モデルが過去に学んだ情報を活用しながら、その特定の人物に関連する特徴を保持するようにします。
2つ目は推論(画像生成)です。DreamBoothでファインチューニングされた後、Stable Diffusionモデルは、指示されたプロンプトに基づいて、さまざまな状況における特定の合成人物の画像を生成します。「スカーフを着たxyz人物」や「ビーチでのxyz人物のクローズアップ写真」のようなプロンプトを使用して、現実的なクラス内変動をもつ合成画像を生成します。不要な画像を生成しないように、否定的なプロンプトも指定できます。
3つ目はフィルタリング(画像選別)です。ここでは、顔検出を行い、顔が検出されない画像を除外しています。特定の人物の情報を保持するために、合成された画像から特徴を抽出し、それらが以前にファインチューニングに使った画像と類似しているかどうかを確認します。十分に似ていない画像は除外しています。また、性別を維持するために、残った画像を性別に基づいてラベル付けし、GANで生成された画像と性別が異なるものは除外しています。
これらのプロセスを通じて、特定の人物情報を保ちつつ、さまざまな文脈でその人物を再現する合成画像を作成できるようにしています。
GANDiffFaceによる合成データセットの分析
ここでは、顔認識で使われる既存のデータセットとどのように比較できるかを見るために、GANDiffFaceで構築した合成データセットの4種類のバージョンから得られた顔の類似度のスコア分布を分析しています。このデータセットが実際に顔認識に利用できるか、実際のデータセットや他の合成画像のデータセットと、どの程度類似しているかを調べています。
実際のデータセットとしては、顔認識によく使われる「VGGFace2」と「IJB-C」を使用しています。VGGFace2はウェブから集めた約9,000人の人物の画像を含み、ポーズや年齢、照明、民族、職業など様々なラベルがあります。IJB-Cには約3,000人の人物が含まれており、顔の一部が隠れている画像や、民族や職業の多様性に焦点を当てています。実際の画像と合成データセットを公平に比較するために、一定の品質以下の実際の画像は除外しています。この品質の基準は、GANDiffFaceで特定人物を生成する際に最も品質が低い画像を排除するために使われたものと同じです。なお、高品質の画像からなるデータセットを作ることに注力しており、低品質の画像からなるデータセットの評価はこの研究の対象外としています。また、他の合成画像のデータセットとして「SFace」や「DigiFace-1M」を使用しています。
まず、実際のデータセットと合成データセットについて、ランダムに10枚の画像を選び、同一人物の画像ペア(マッチング)と異なる人物の画像ペア(非マッチング)に対して、ArcFaceを使って類似度を計算しています。次に、実際のデータセットのスコア分布を参照として、実際のデータセットと合成データセットのスコア分布間の違いをクルバック・ライブラー(KL)発散で測定しています。
類似度のスコア分布は、下図のようになっています。
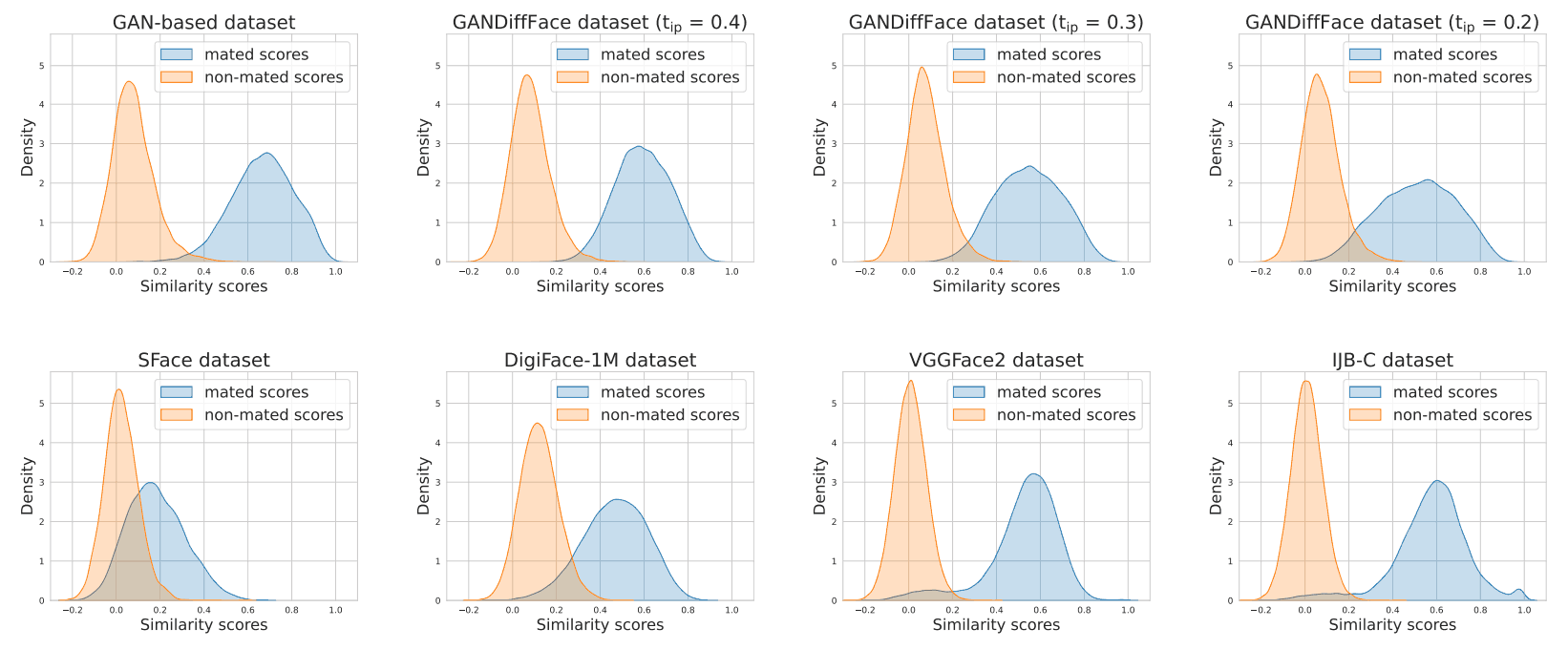
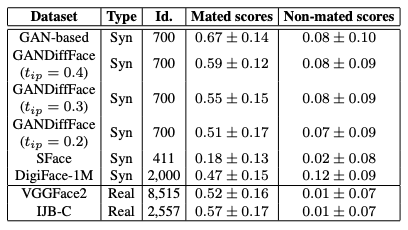
また、実際のデータセットと合成のデータセットの人物数(Id)と、マッチング/非マッチングのスコア分布の平均値(scores)は、下表のようになっています。この表から、データセット内のマッチングのスコア分布の平均値は、Diffusionモデルを使うと下がり、実際のデータセットの平均値に近づいていることがわかります。また、合成データセットは実際のデータセットよりも正の値に分布が偏っていることがわかります。これは、クラス間の現実的な変動を再現することが難しいことを表しているといえます。
また、各データセットの分布と、VGGFace2およびIJB-Cによって提供される実際のデータセットとの間のKL発散値は、下表のようになっています。
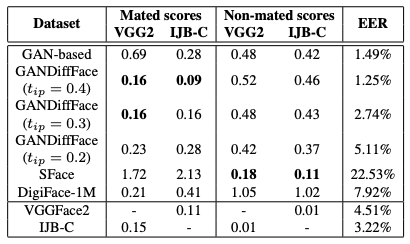
この表から合成のデータセットであるSFaceとDigiFace-1Mは、GANDiffFaceと比べて類似度の分布が悪く、実際のデータセットと比べると、EERが約2倍になっていることわかります。これは、現実的なクラス内およびクラス間の変動を再現することに失敗していることを示しているといえます。
まとめ
この論文では、顔認識のための合成データセットを構築する新しいフレームワーク「GANDiffFace」を提案しています。生成的敵対ネットワーク(GAN)と拡散モデル(Diffusion Model)を繋ぎ合わせることで、よりリアルで多様な人物の画像を合成できるようにしています。1つ目のモジュールであるGANでは、StyleGAN3を使って、リアルな顔の画像を生成し、70種類の人口統計グループを均等に表現することができます。また、2つ目のモジュールであるDiffusion Modelでは、DreamBoothを使って個別の人物に特化したStable Diffusionというモデルを調整することで、現実に近いクラス内変動を持つデータセットを作成することができます。
しかし、一方で、いくつかの課題もあります。特に、個別の人物に合わせてモデルを調整するには多くの計算処理が必要になります。そのため、理論的に大規模なデータセットを構築することも可能ですが、この論文では700人のデータに制限されています。また、生成された画像には、特に手などの人体の部分で、人間が見てもわかるアーティファクト(画像の不自然な部分やエラー)が現れることがあります。
今後も、生成AIのブレークスルーに伴い、このような合成画像によるデータセットの研究が盛り上がっていくと考えられます。






この記事に関するカテゴリー






