従来比20倍!?顔認識向け超大規模な公開データセット「Webface260M」
3つの要点
✔️ MS1MやMegaFace2に対して、人物数が最大で20倍、画像数が最大で10倍の超大規模な公開データセットを構築
✔️ 顔認識の実用で重要な推論時間を考慮した新しい評価プロトコルを提案
✔️ IJB-CでSOTA、NIST-FRVTで3位と高い性能を達成
WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition
written by Zheng Zhu, Guan Huang, Jiankang Deng, Yun Ye, Junjie Huang, Xinze Chen, Jiagang Zhu, Tian Yang, Jiwen Lu, Dalong Du, Jie Zhou
(Submitted on 6 Mar 2021)
Comments: Accepted by CVPR2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
概要
これまで顔認識の分野では、他の分野と同様に、精度向上に向けたネットワークやLossの研究が主流でした。しかし、一方で、大規模データセットが不足しています。特にPublicデータセットで不足しています。
Privateな大規模データを保有している一部の企業は、大規模データを使った研究ができる一方で、データを保有していないアカデミックは限られたPublicデータで研究開発を進めているのが現状です。
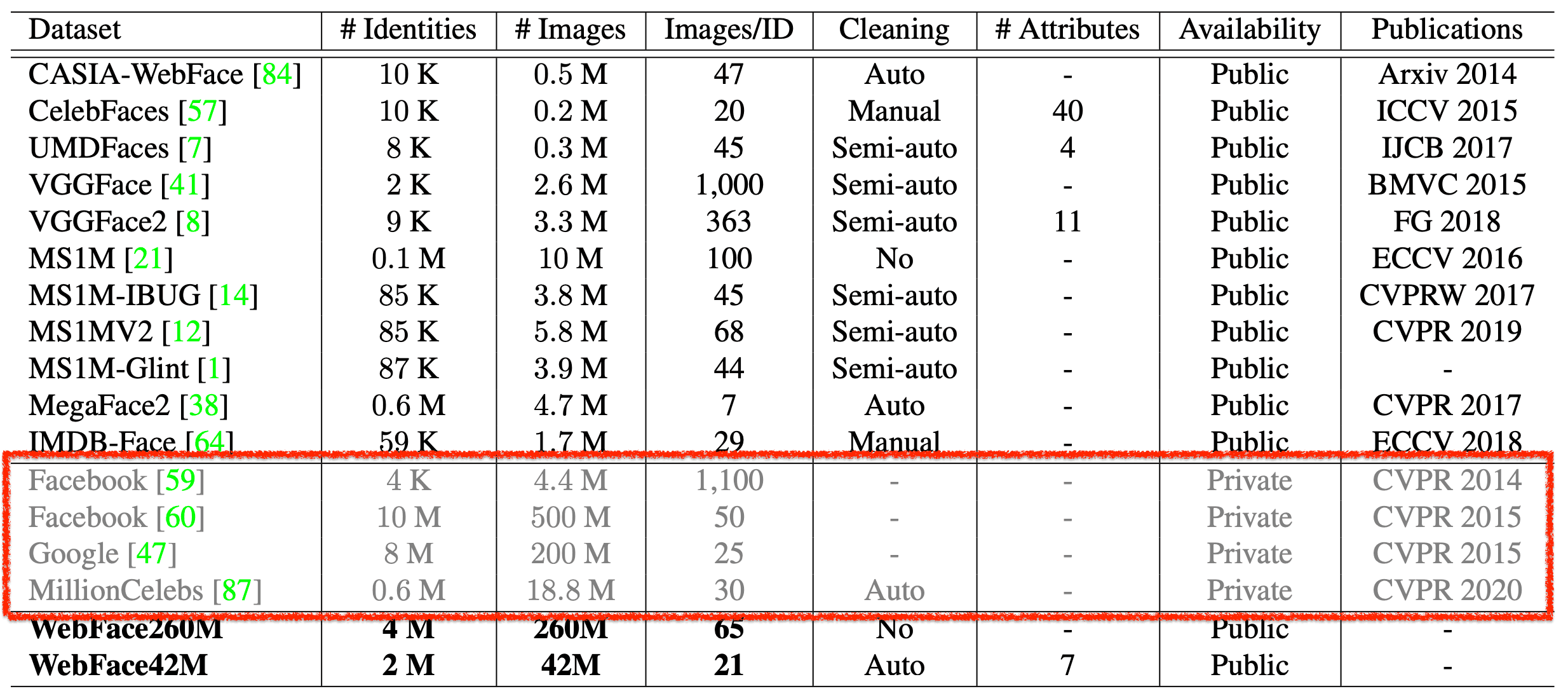
顔認識モデルは、当然、学習データが多いほど高い性能が得られますが、Publicデータは小規模であるため、モデルの精度も飽和状態にあります。そこで、この論文では、新たに大規模なPublicデータセットである「WebFace260M」と「WebFace42M」を提供しています。
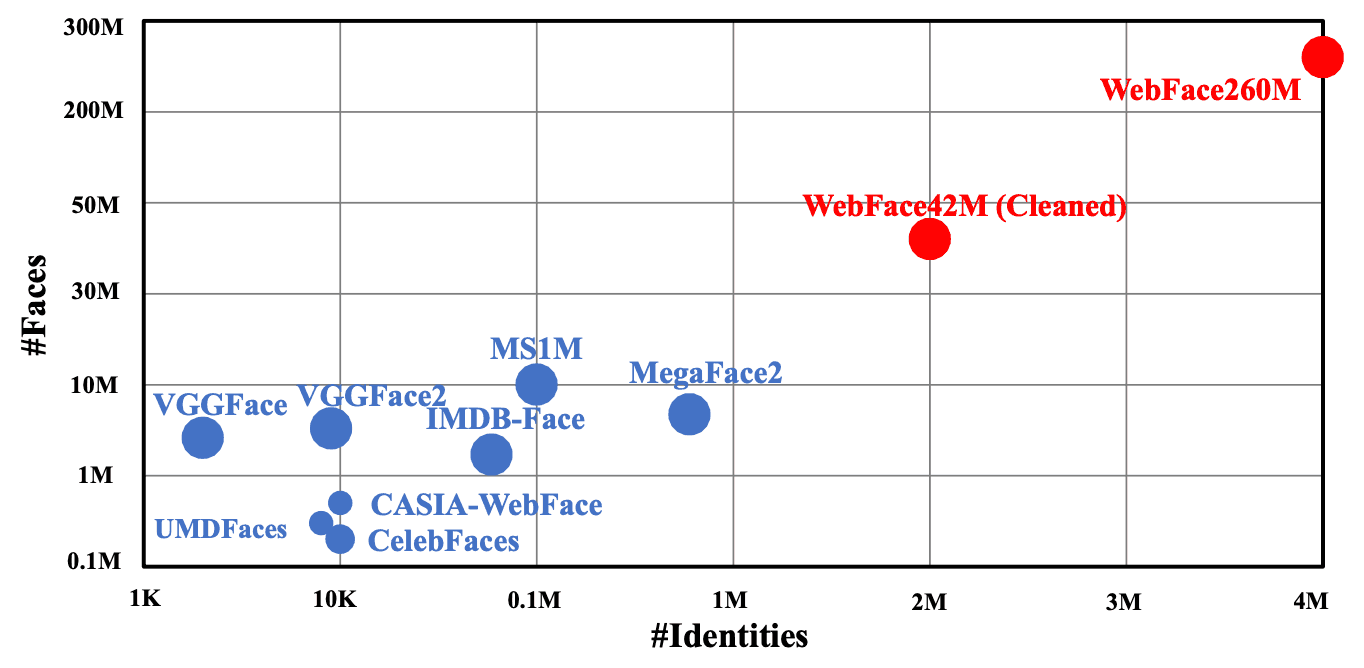
このデータセットは、従来主流であった大規模データであるMS1MやMegaFace2と比べると、人物数が最大で20倍、画像数が最大で10倍の規模になっています。
また、大規模データセットを用意するにあたっては、対象人物の収集も大変ですが、その後のデータのクリーニングも、データの規模が大きくなるに連れて大変になります。そこで、この論文では、CASTというパイプラインを利用して、自動でデータのクリーニングを実現する方法も提案しています。
さらに、これまでのデータセットの多くは、精度向上に焦点を当てたものがほとんどでしたが、顔認識は実用上、認識速度も非常に重要になります。そこで、このデータセットでは、速度も考慮するFRUITSというプロトコルも提案しています。
WebFaceで学習したモデルは、IJB-Cデータセットにおいてエラー率を40%も削減してSOTAを達成し、NIST-FRVTでは430モデルの中で3位の性能を示しています。この結果からアカデミックと民間企業のデータ格差がなくなり、双方でより一層、顔認識の研究が進むきっかけになると考えられます。
超大規模データセット「WebFace260M/42M」とは?
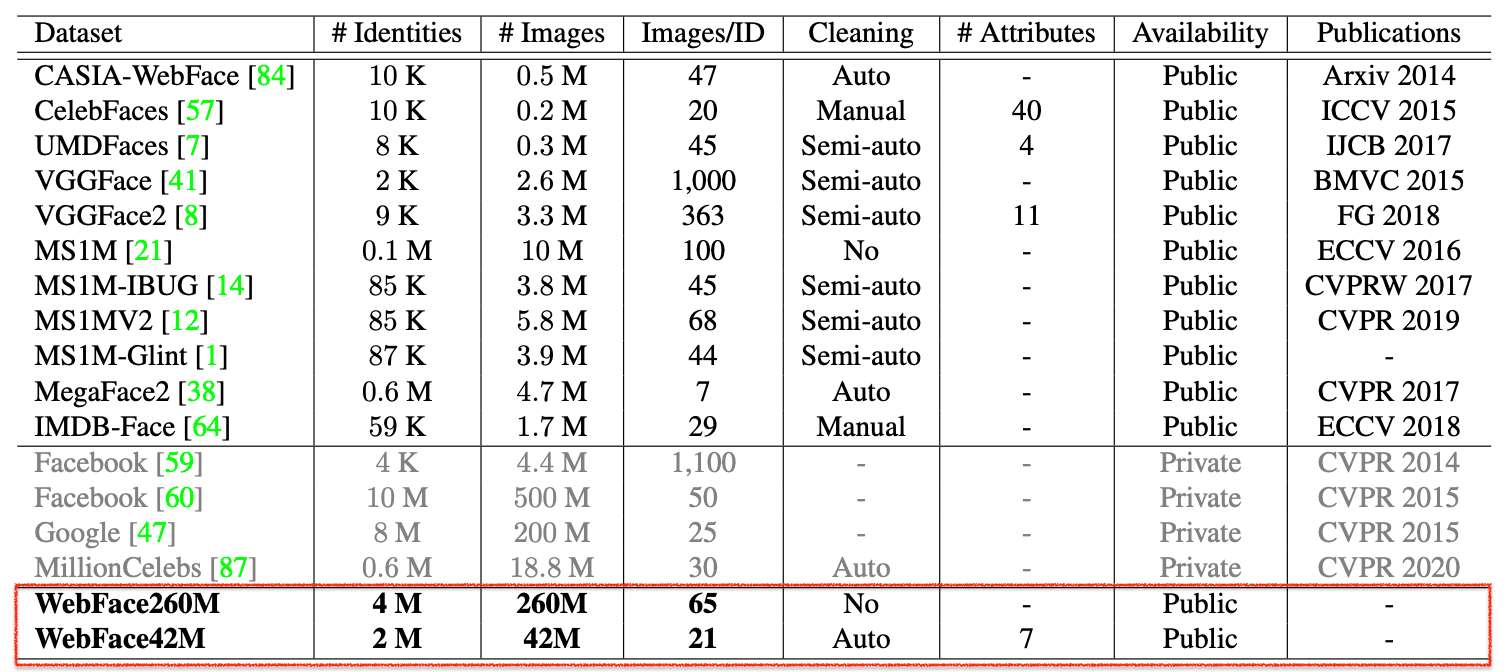
今回提供された大規模データセットは「WebFace260M」と「WebFace42M」の2つです。Webで収集したノイズを含む大規模なWebFace260Mを生成したのち、CASTというパイプラインで自動クリーニングすることでWebFace42Mが得られます。
WebFace260Mの構築にあたって、まずMS1M(Freebaseから構成)とIMDBから4Mの人物のリストを取得しています。その後、Googleの画像検索を利用して、画像を取得しています。画像取得時は、対象人物の10%は各200枚、20%は各100枚、30%は各50枚、40%は各25枚...と取得し、合計で260Mの画像を取得しています。
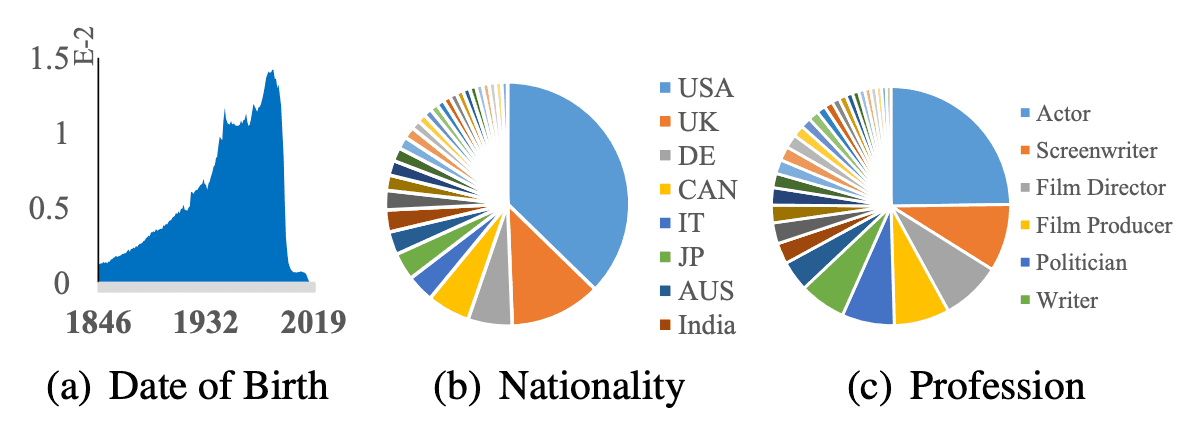
データセットの属性データに関する統計値は下図のようになっています。1846年以降に生まれた200以上の異なる国/地域で、500以上の異なる職業の人物から構成され、学習データとしての多様性も保証されています。
次に、後述するCASTを利用して、自動的にノイズを除去していきます。その結果、2Mの人物と42Mの画像で構成されるWebFace42Mが構築されます。このデータセットでは各人物に対して3枚以上、平均21枚の画像が含まれています。
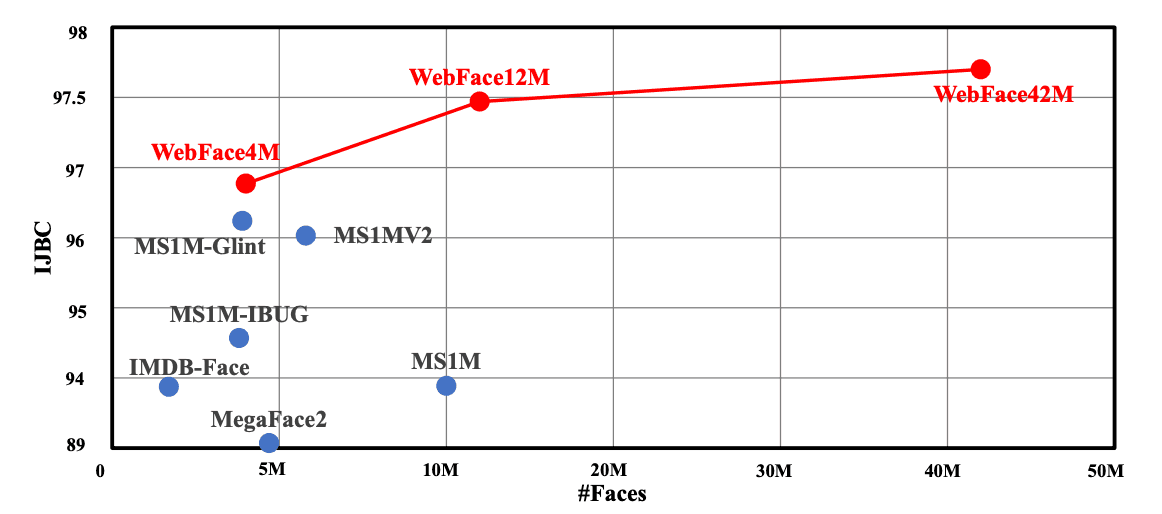
冒頭でも触れたように、従来主流であったMS1Mと比べると、IDは3倍、画像は10倍になっています。MagaFace2ではIDが20倍、画像数が4倍になっています。ノイズの割合についても、MS1Mが約50%、MegaFace2が約30%とされているのに対して、WebFace42Mは10%以下となっています(サンプリングでの結果)。
また、ポーズ、年齢、人種、性別、帽子、ガラス、マスクなど7つの顔属性ラベルも提供しています。特に、顔の向き、年齢、人種は下図の構成割合になっています。
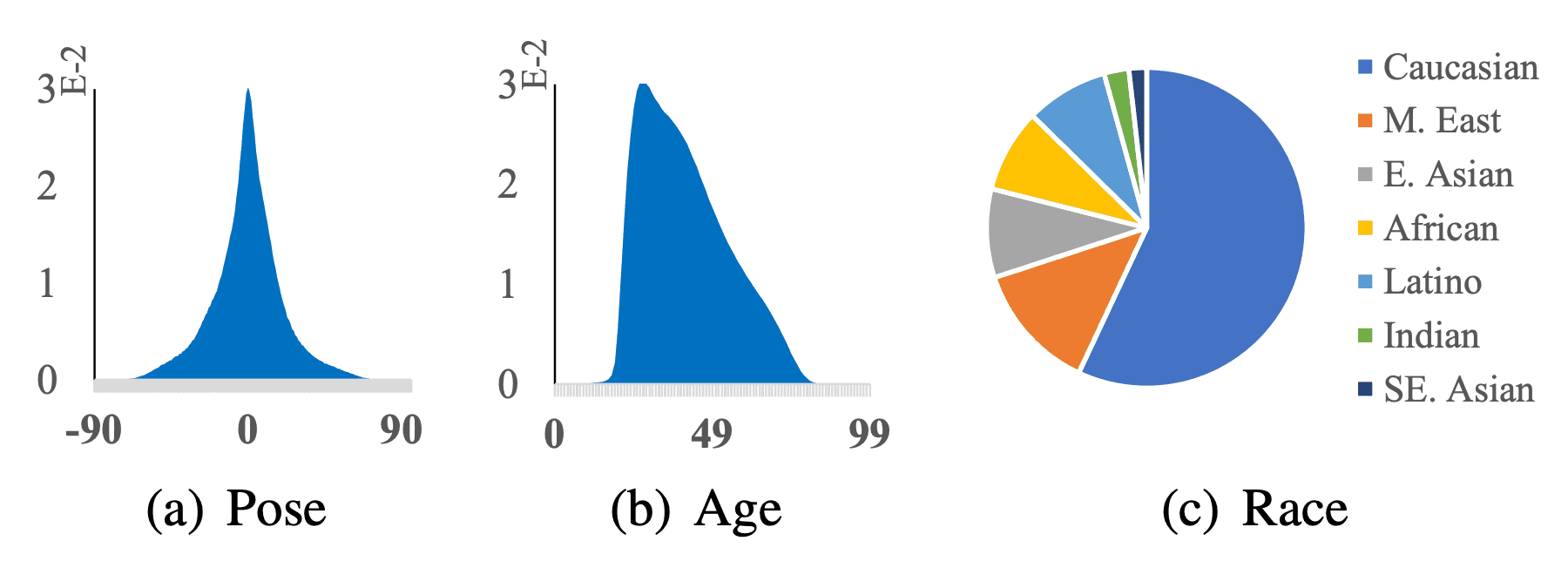
自動クリーニング「CAST」とは?
Webで収集したデータをそのままでは多くのノイズデータを含んでいます。そのため、高品質なデータセットを構築するためには、データのクリーニングが必要です。多くのノイズを含む学習データでモデルを構築すること性能を低下させてしまいます。WebFace260Mのソースとして使用しているMS1Mは前述の通り、ノイズ割合が50%になると言われています。
これまで構築されたデータセットでもクリーニングのために、さまざまな手法が利用されています。VGGFace、VGGFace2、IMDB-Faceでは、手動あるいは半自動でクリーニングを行っていますが、人力の割合が高く、非常にコストがかかります。そのため、大規模なデータセットの構築は非常に困難になります。また、MegaFace2では、自動クリーニングを適用していますが、そのプロセスが複雑であり、適用しても30%をはるかに超えるノイズが含まれると言われています。
この他にも教師なしの手法や、教師ありのグラフベースの手法で顔情報をクラスター化する方法も研究されていますが、これらはいずれもデータセット全体がある程度精巧であることを前提としているため、ノイズが非常に多いWebFace260Mには適していません。
一方で、最近では、半教師あり学習の標準的なアプローチであるSelf-Traningという手法が画像分類の性能を大幅に向上させるために研究されています。
この論文では、下図のように、Self-Trainingで自動クリーニングを行うCAST(Cleaning Automatically by Self-Training)を導入しています。ただし、クローズセットのImageNetの分類とは異なり、オープンセットの顔認識で疑似ラベルを直接生成することは実用的ではないため、この点を考慮して、Self-Traningによる自動クリーニング(CAST)とうパイプラインを設計しています。
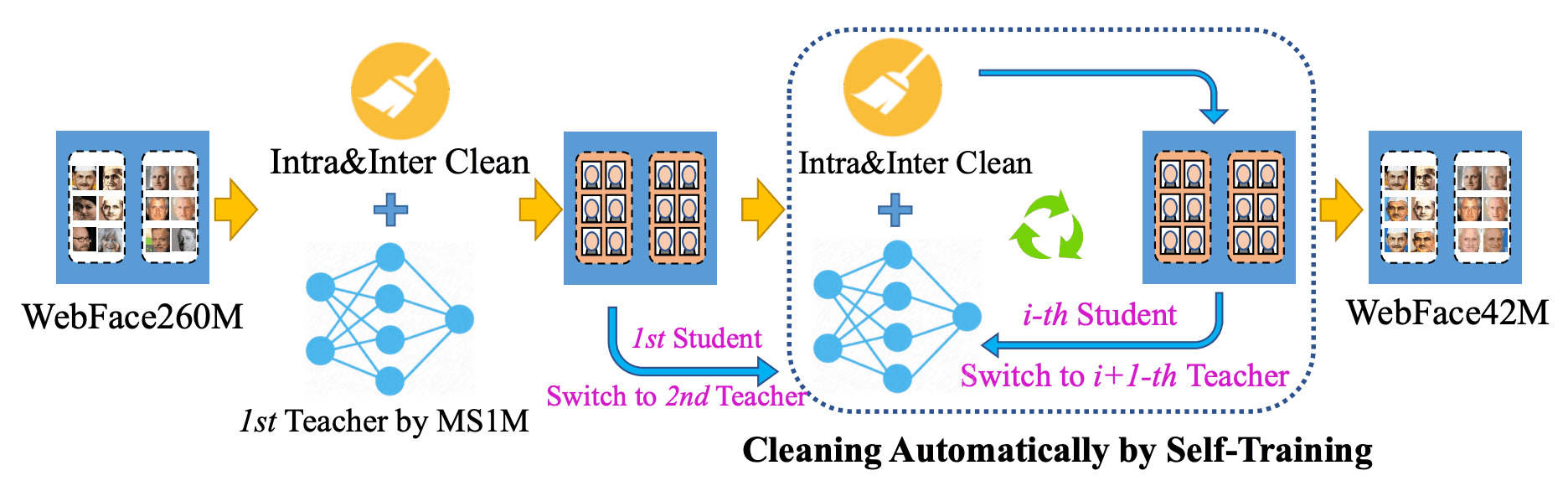
CASTでは、まずPublicデータセットMS1MV2を使用して教師モデル(ResNet100/ArcFace)を学習させ、260Mの画像をクラス内/クラス間でクリーニングします。次に、このクリーニングされたデータセットで学生モデル(同じくResNet-100/ArcFace)を学習させ、クラス内/クラス間でクリーニングします。この後、高品質の42Mの画像が得られるまで、学生モデルと教師モデルに切り替えることを繰り返していきます。
CASTの後、コサイン類似度が0.95を超えた場合、同一人物とみなし重複が削除されています。さらに、各対象者の特徴量の中心は、主要なベンチマーク(LFW、FaceScrub、IJB-Cなど)と、後述する、この論文で構築する提案されたテストセットと比較し、コサイン類似度が0.70より大きい場合、重複として削除されています。
CASTの反復回数が多いほどきれいになり、ID数と画像数が少なくなり、これら重複を削除すると、最終的に、2,059,906個のIDと42,474,558個の画像のWebFace42Mを取得できます。
FRUITSプロトコルとは?
FRUITS(Face Recognition Under Inference Time conStraint)は、実用時のユースケースに応じて、特定の推論時間における性能評価を行うプロトコルです。
これまで、のようにさまざまな性能評価のプロトコルは提案されていますが、推論時間を考慮したモデルはあまり見られませんでした。しかし、この観点は、特にエッジで利用するなど軽量モデルを利用する際に重要になります。
これまで同様の目的で提案されたものとしてLightweight face recognition challengeがあります。しかし、これは顔認識に必要な前処理であるFace Detection、Face Alignmentなどは考慮されていないため、実用を考えるとやや制限された条件下での性能評価になります。この論文で提案しているFRUITSは、Face Detection、Face Alignmentも含めた顔認識の一連の処理を評価対象にしています。
また、同様の性能評価を行うプロトコルとして、NIST-FRVTが実施しているものがありますが、申請に条件があり、気軽に評価することが難しいのが現状です。そこで、この論文ではPublicデータを使用して、気軽に評価できる新しいプロトコルを提案しています。
このFRUITSプロトコルでは、3つの条件を用意しています。
- FRUITS-100
Face Detection、Face Alignment、Feature Embedding、Matchingを含めた顔認識の一連の処理を100ms以内とした時の性能評価です。これは主にモバイルデバイスに実装される顔認証システムのベンチマークを想定しています。 - FRUITS-500
顔認識の一連の処理を500ms以内とした時の性能評価です。
ローカルの監視カメラにに実装される顔認証システムのベンチマークを想定しています。 - FRUITS-1000
顔認識の一連の処理を1000ms以内とした時の性能評価です。
クラウド上で利用する顔認証システムのベンチマークを想定しています。
これらの推論時間はIntel Xeon CPU E5-2630-v4@2.20GHzによって計測されます。
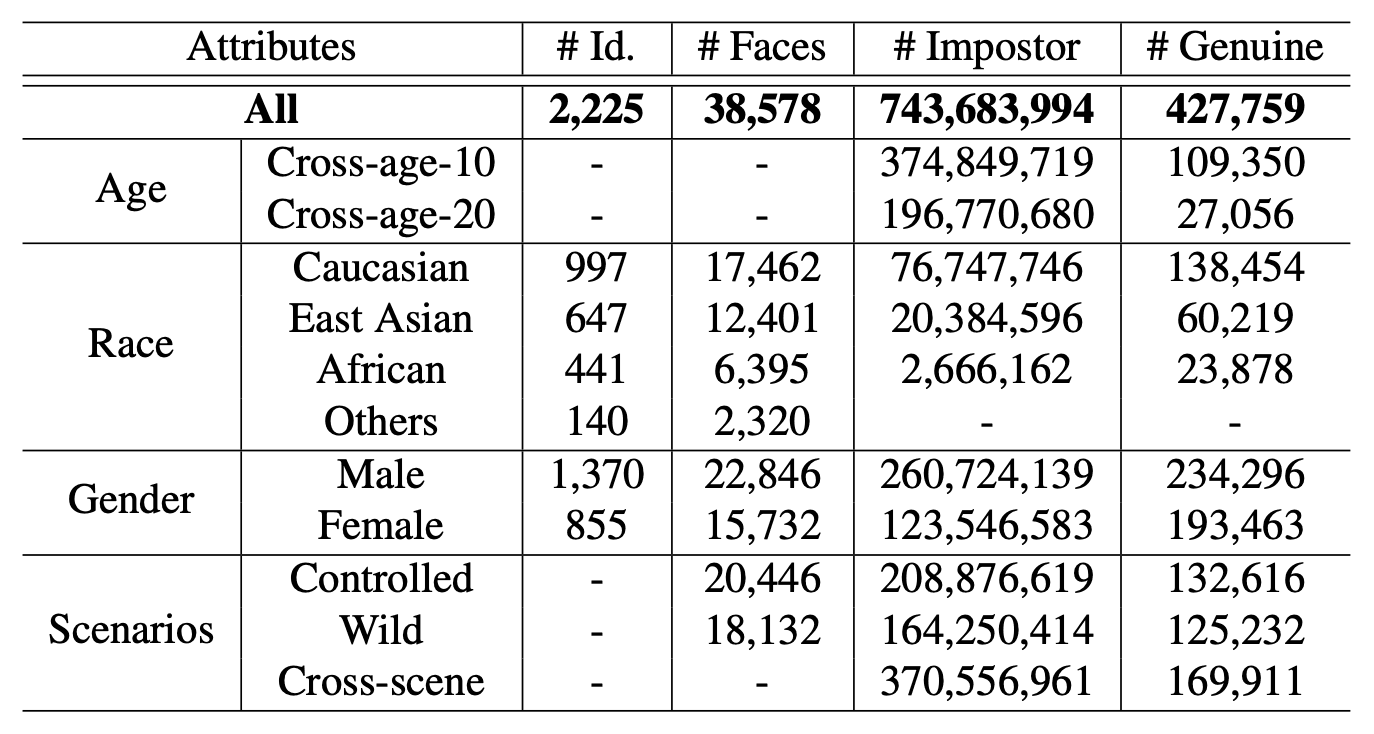
FRUITSでは、ノイズを除去した、より精巧なテストセットを厳選して用意しています。アノテーターが手動で属性情報のバランスがとりながら高品質な画像を選定しています。最終的にテストセットの統計値は下表のようになっています。人物の合計が2,225人、画像の合計が38,578枚となっています。
性能評価は、このFRUITSプロトコルと、後述するテストセットに基づいて、1:1のverificationの性能を評価しています。False Match Rate(FMR)とFalseNon-Match Rate(FNMR)を用いています。同じFMRでFNMRがより低いほど良い性能を示すことになります。
実験
学習データセットの影響
新しい学習データの影響を調べるために、ResNet-100を用いたをベースに、主要な損失関数(ConFace/ArcFace/CurricularFace)を適用し、Publicテストセットを利用した比較検証をしています。下表が様々な学習データセット(Data)で学習したモデルを様々なテストデータセット(Pairs/RFW/Mega/IJB-C/Ours)で評価した結果です。
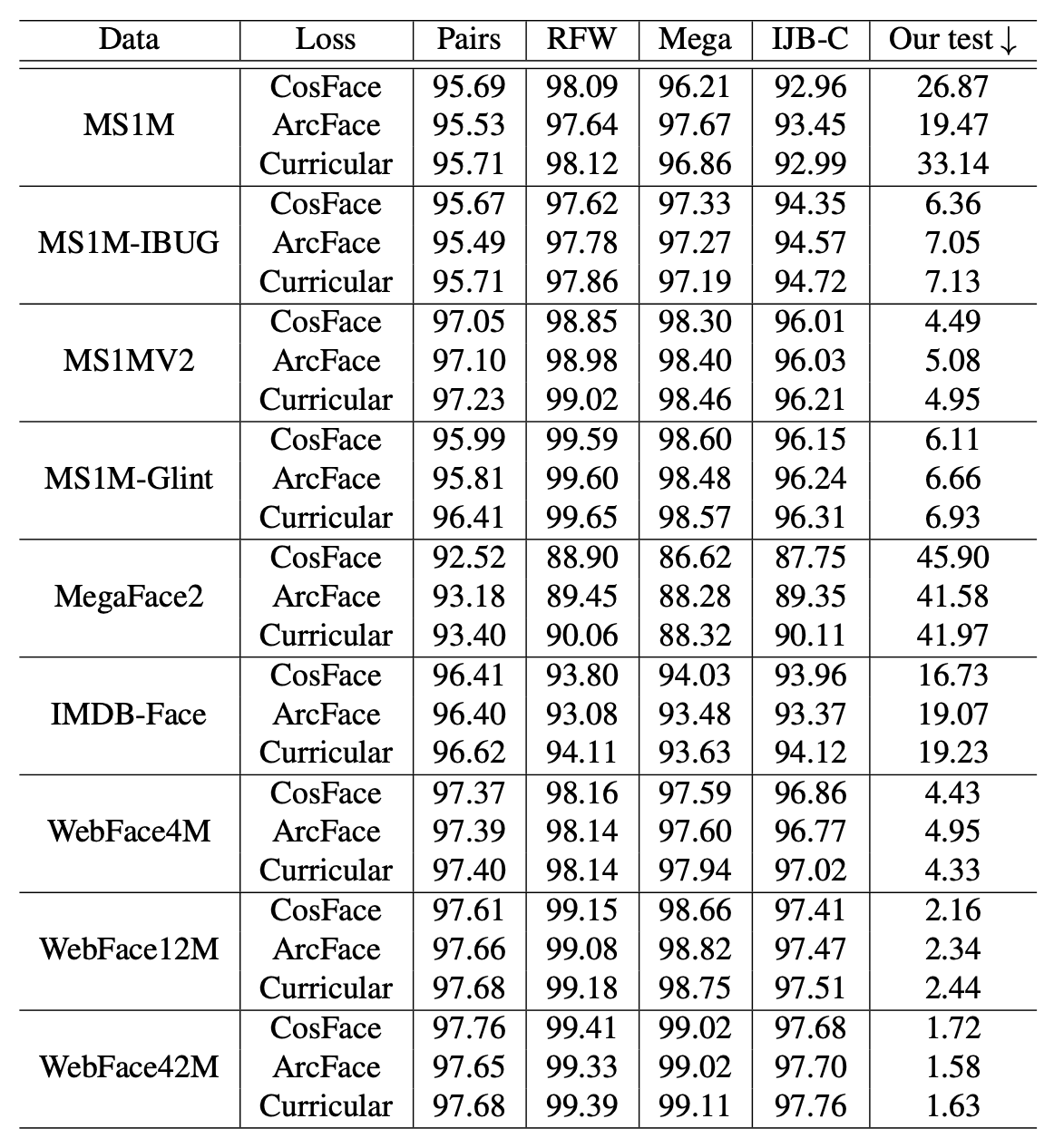
WebFace42Mで学習させたモデルが最も高い性能を示していることがわかります。特に、MS1MV2の学習データに対して、テストデータとしてIJB-Cを使用した場合と比較すると、FAR(False Accepte Rate)=1x10-4におけるTAR(True Accepte Rate)が96.03%から97.70%に向上し、エラー率が40%も減少していることがわかります。
また、WebFaceにおいても4M、12M、42Mを比べると、データ量が増えるにしたがって、性能が向上していることがわかります。
FRUITSプロトコルによる結果
FRUITSプロトコルでの性能を評価しています。下表は、今回用意されたベースラインのリストです。Face Detection(Det)、Face Alignment(Align)、Face Embeddingまでのモジュールを含む様々な顔認識システムとそれらの推論速度(Time)を示しています。
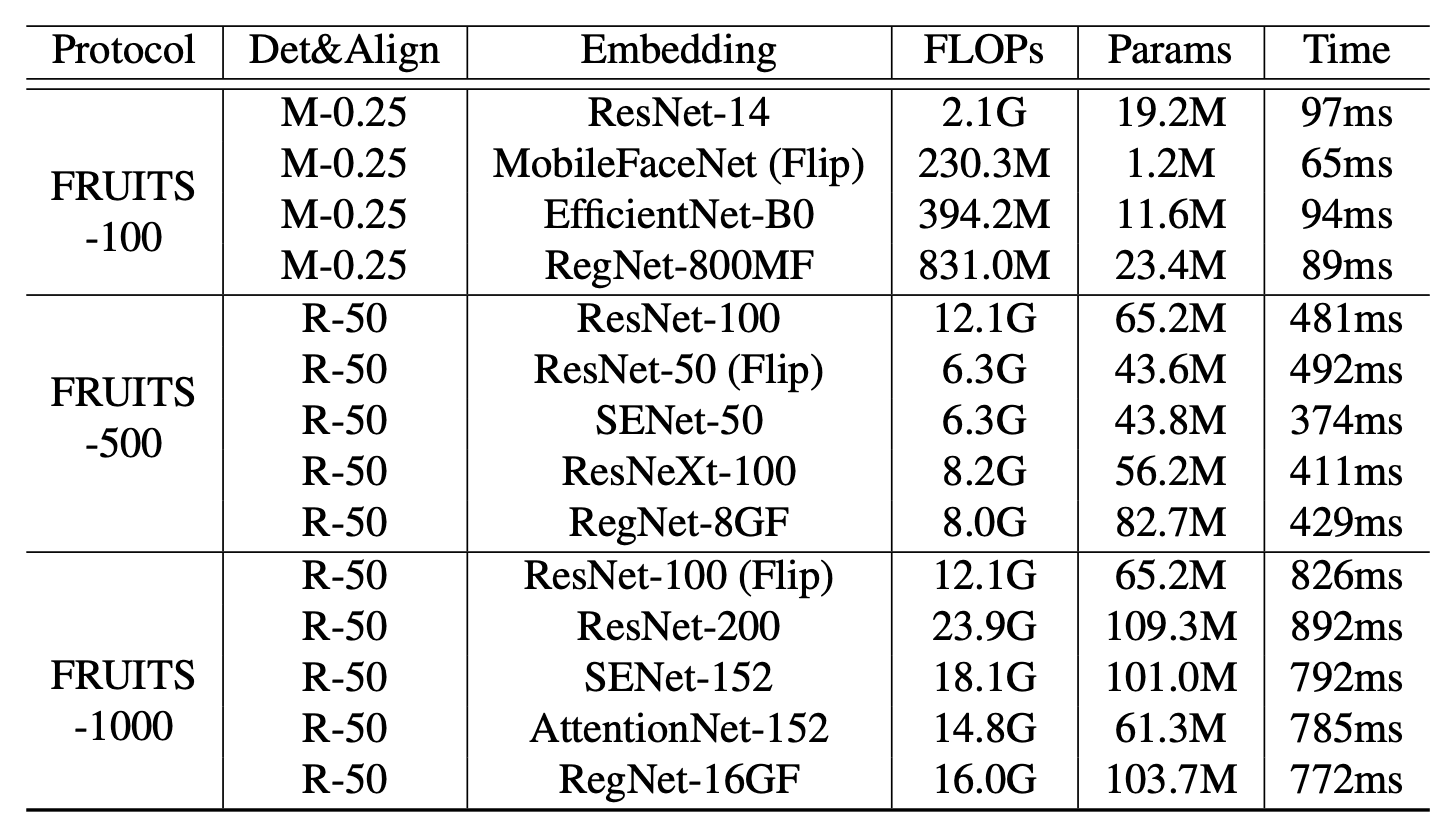
すべてのモデルがArcFaceを適用しており、WebFace42Mで学習しています。また、Embeddingには、MobileNet、EfficientNet、AttentionNet、ResNet、SENet、ResNeXtなど代表的なネットワークアーキテクチャを適用しています。
FRUITS-100は、推論速度の制限が非常に厳しいため、Det&AlignにRetinaFace-MobileNet-0.25(M-0.25)、EmbeddingにResNet-14、MobileFaceNet、EfficientNet-B0、RegNet-800MFなどの軽量アーキテクチャを適用しています。テストセットのAllに対するFNMRと属性バイアスの分析結果は、下図の(a)(b)のようになります。
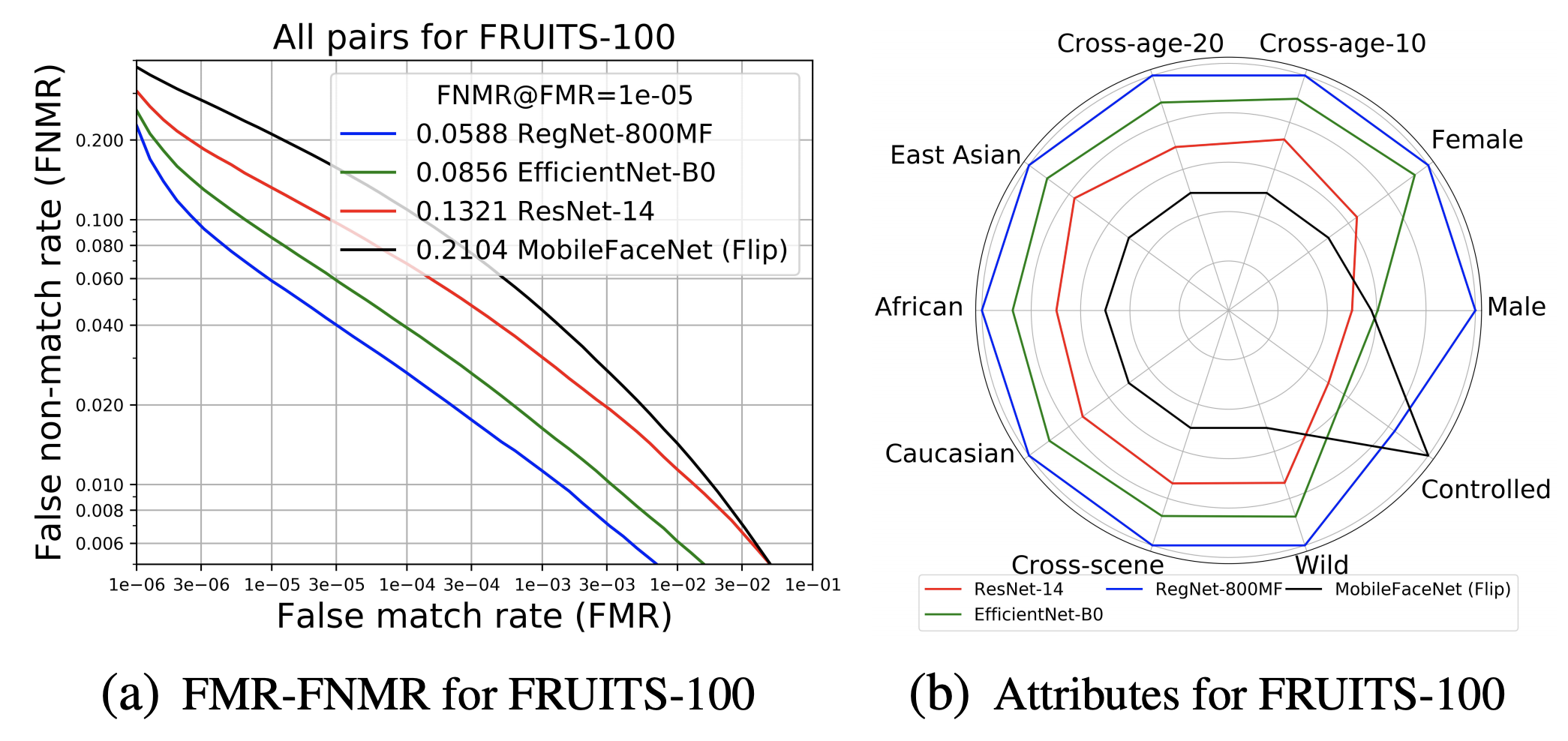
非常に制約された条件下で軽量モデルを適用しているため、最良のベースライン(RegNet800MF)で、5.88%FNMR@FMR=1x10-5ほどの精度となっています。FRUITS-100では、未だ改善の余地が非常に大きいと言えます。
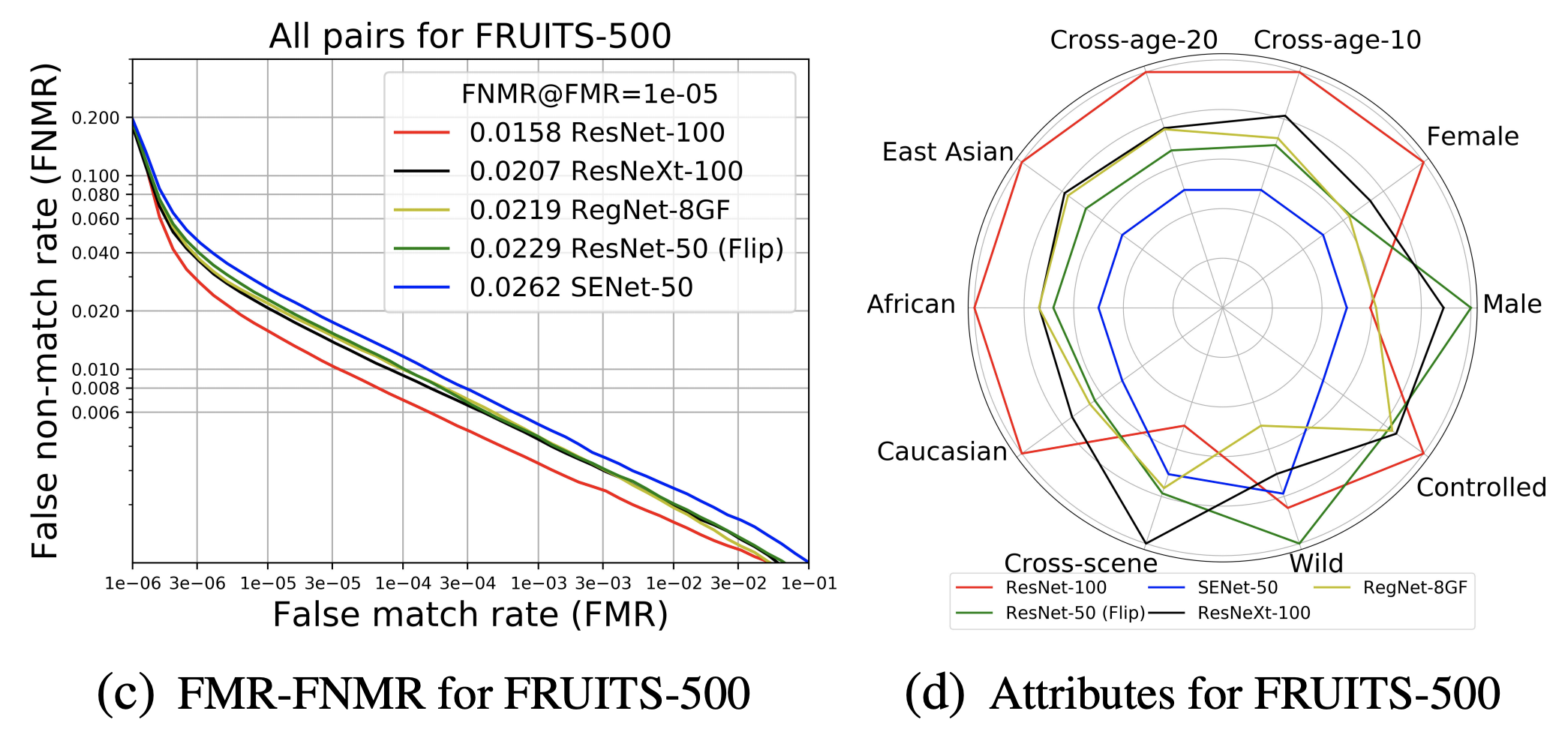
FRUITS-500は、FRUITS-100に比べると、より高性能なモデルを適用できるようになります。Det&AlignにRetinaFace-ResNet-50(R-50)、EmbeddingにResNet-100、ResNet-50、SENet-50、ResNeXt-100、RegNet-8GFを適用しています。テストセットのAllに対するFNMRと属性バイアスの分析結果は、下図の(c)(d)のようになります。最良のベースライン(ResNet-100)は、偏りなく全体的に最高の性能を示しています。
FRUITS-1000は、EmbeddingにResNet-100、ResNet-200、SENet-152、AttentionNet-152、RegNet-16GFを適用しています。テストセットのAllに対するFNMRと属性バイアスの分析結果は、下図の(e)(f)のようになります。ResNet-200は最も高い性能を示しています。
NIST-FRVTの結果
NIST-FRVT(Face Recognition Vendor Test)とは、セキュリティ基準を定めるNIST(米国 国立標準技術研究所)が行っている顔認識モデルの性能評価テストです。国際的にNIST-FRVTの結果で顔認識モデルを評価することが一般的になっています。
この論文は、この国際的な評価テストであるNIST-FRVTにも申請しいます。申請したモデルは、FRUITS-1000の設定に従って、Face DetectionとFace AlignmentにRetinaFace-ResNet-50、Face EmbeddingにArcFace-ResNet-200を用いて、WebFace42Mで学習したものです。
WebFace42Mで学習させたモデル(ours)は、提出された430個のモデルの中で、3位の結果となっています。さまざまなタスクで高い性能を示していることがわかります。NIST-FRVTにおける上位5つのモデルのFNMRでの比較結果は下表のようになっています。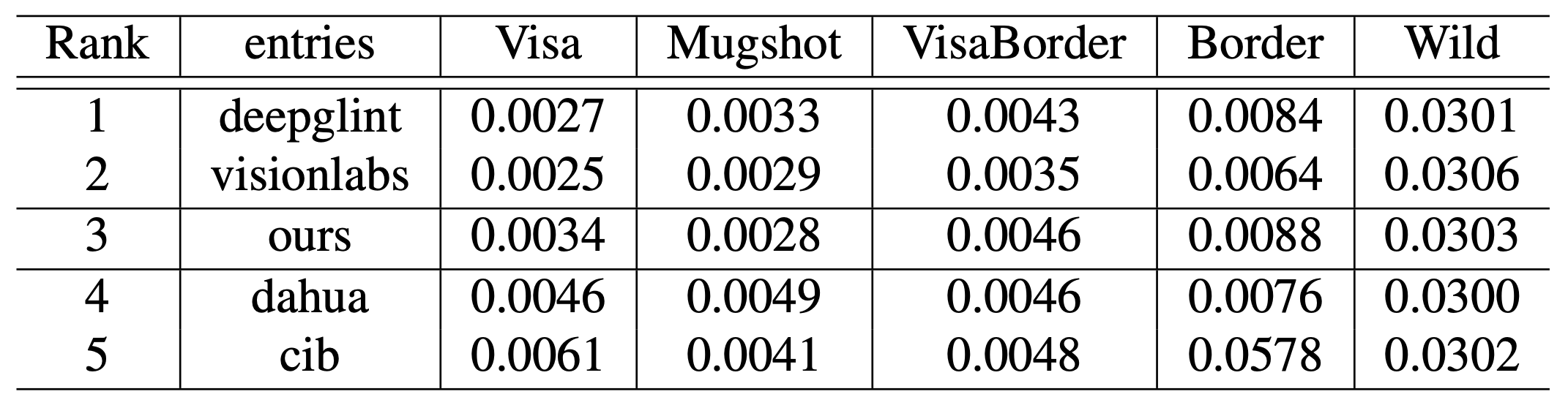
このNISTの結果でわかるように、大規模なデータセットを持つ民間企業が上位を占める中、PublicデータのWebFace42Mで高い性能を示したことで、今後は顔認識の研究におけるアカデミックと民間企業の間のギャップを埋める重要なきっかけになると考えられます。





この記事に関するカテゴリー






