テスト精度はGANサンプルから推測できる!?
3つの要点
✔️ GANによる合成データセットを用いてテスト精度の予測を行う試み
✔️ 既存の様々な手法を上回る結果を発揮
✔️ GANの生成分布がトレーニングセットよりテストセットに近いことなどの興味深い性質を確認
On Predicting Generalization using GANs
written by Yi Zhang, Arushi Gupta, Nikunj Saunshi, Sanjeev Arora
(Submitted on 28 Nov 2021 (v1), last revised 17 Mar 2022 (this version, v2))
Comments: ICLR2022
Subjects: Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
トレーニングデータセットとネットワークのみからテスト誤差を予測することは、深層学習における重大な課題です。
この記事で紹介する論文では、同じトレーニングデータセット上で学習したGAN(Generative Adversarial Network)により生成した合成データを用いることにより、この問題に取り組みました。
その結果、GANにはよく知られた限界(モード崩壊など)があることに反し、GANによりテスト誤差を予測する試みが成功したことが示されました。
GANサンプルによるテスト性能予測
論文では、GANにより生成した合成データによりテスト性能を予測する試みが行われています。ここで、トレーニングセット、テストセット、GANにより生成された合成データセットを、それぞれ$S_{train},S_{test},S_{syn}$と表します。
このとき、トレーニングセット$S_{train}$で学習した分類器$f$が与えられたとき、テスト集合$S_{test}$における分類精度$g(f) := \frac{1}{|S_{test}|}\sum_{(x,y) \in S_{test}} 1[f(x)=y]$を予測することが目標となります。
論文での試みはシンプルで、この目標を達成するために、$S_{train}$上で学習した条件付きGANモデルにより、ラベル付き合成データセット$S_{syn}$を作成します。そして、$S_{syn}$における$f$の分類精度$\hat{g}(f)$を、テスト精度の予測値として使用します。
全体の疑似アルゴリズムは以下の通りです。

ここで、GANとしてStudioGAN libraryの事前学習済みBigGAN+DiffAugを、分類器としてVGG-(11,13,19)、ResNet-(18,34,50)、DenseNet-(121,169)を利用し、CIFAR-10とTiny ImageNetでこの試みを実行した場合の結果は以下の図の通りです。
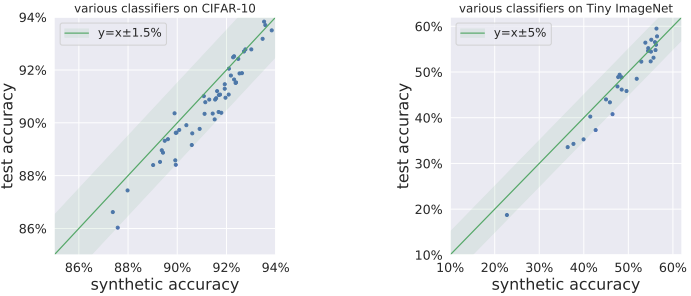
図の通り、どちらのデータセットについても、様々な分類器を用いた場合について、一貫して合成データ上での精度はテスト精度の近傍に存在しており、良い予測値として機能していることがわかりました。
PGDL COMPETITIONにおける評価
次に、NeurIPS 2020 Competition on Predicting Generalization of Deep Learningにおけるタスクについて、同様の試みを行います。
ただし、このタスクではテスト精度ではなくGeneralization Gapを予測するのが目標となるため、先述のアルゴリズム1は合わせて修正されています。その他の実験設定(使用するGANなど)は先程と同様となります。結果は以下の通りです。
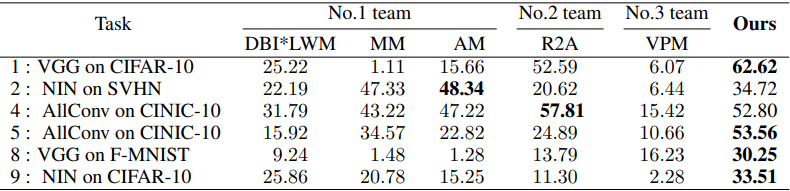
ここで、GANの学習がうまくいかなかったタスクを除くタスクについて結果が示されています。
総じて、提案手法は上位3チームを大きく上回る結果を示しています。なお、全てのタスクについて、ハイパーパラメータ探索は行われていないため、追加の調整によってより性能を改善できる可能性もあります。
DEMOGEN BENCHMARKにおける評価
次に、Deep Model Generalization benchmark (DEMOGEN)における結果は以下の通りです。
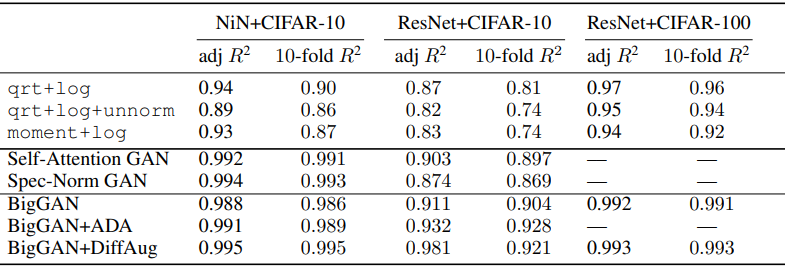
この表では、様々なGANモデルを利用した場合の結果が示されています。全体として、GANを利用した予測は、非常に優れた結果を示しました。
GANサンプルとテストセットの類似性
GANサンプルがテスト精度の予測に良好な性質を示す理由を分析するため、GANが生成する合成データとテストセットの類似性について調査を行います。この目的のため、Class-conditional Frechet Distanceと名付けられた指標によってデータセット間の類似性を測定します。
ここで、ある特徴抽出器$h$について、二つの集合$S,\tilde{S}$間の距離は以下の式で与えられます。
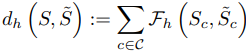
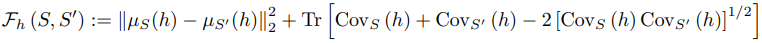
定義の詳細は元論文に譲ります。この指標に基づいて測定された、合成データセット・トレーニングセット・テストセットの分布間距離の関係は以下のようになりました。
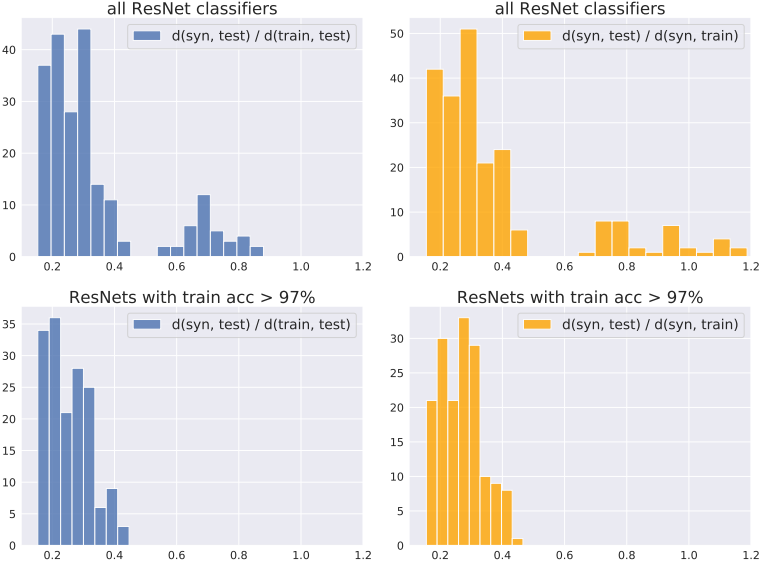
ここで、図の上は精度の低い分類器を含む場合、下は97%以上の精度を示した分類器のみを特徴抽出器として用いた場合の分布間距離の比が示されています。総じて、$d_h(S_{syn}, S_{test}) < d_h(S_{syn}, S_{train})$となる傾向がみられ、特に良好な性能を発揮した分類器を用いた場合はこの傾向が顕著となっていました。
これは、合成データセットがトレーニングセットよりもテストセットに近い、という結果を示しています。この結果は、GANが$S_{syn}$と$S_{train}$間の類似性を高めるよう学習されていることを踏まえると、非常に驚くべき結果であるといえます。
よりこの結果について検証するため、GANモデルのDiscriminatorと異なるモデルを分類器として使用した場合について、同様に分布間距離を求めた結果は以下の通りです。
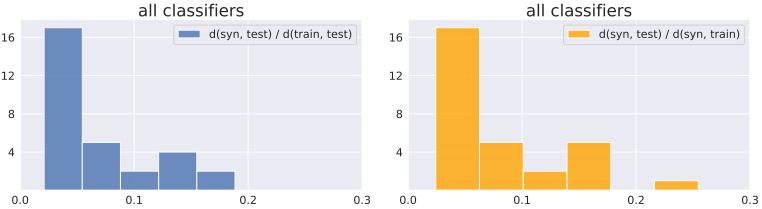
この場合でも同様の結果が得られており、やはり合成データセットがトレーニングセットよりテストセットに近いという現象が見られました。
データ増強の効果について
最後に、GANの学習時と分類器の学習時のデータ増強の有無によるテスト精度と合成データ精度のプロットは以下のようになりました。
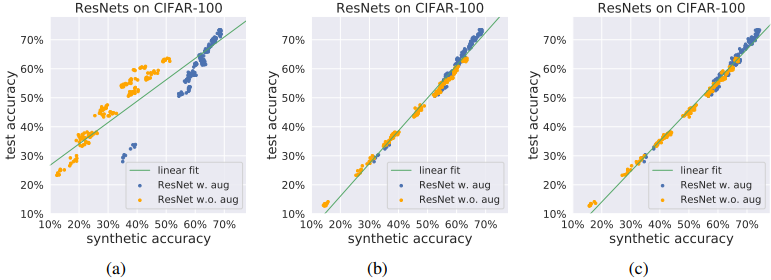
図の(a)は実画像サンプルにのみ増強を適用した場合、(b)は増強なし、(c)は微分可能な増強を適用して学習したGANの結果が示されています。また、分類器の学習時のデータ増強がある場合は青、ない場合はオレンジの点でプロットされています。総じて、データ増強は必ずしも汎化予測に有益であるとは限らないことがわかりました。
最も良い結果が得られるのは、実画像と偽画像の両方に微分可能な増強を適用し、目標分布を操作せずにDiscriminatorの正則化を行う場合であると考えられます。
まとめ
本記事では、GANにより生成された合成データを汎化予測に用いるという新たなアイディアについて取り組み、有益な結果を得た研究について紹介しました。総じて、GANの生成分布がトレーニングセットよりテストセットに近い等、直感に反する驚くべき結果が得られています。
新たな理論による理解も含め、今後のさらなる研究のきっかけとなりうる興味深い研究であると言えるでしょう。






この記事に関するカテゴリー






