
画像生成でBigGANに勝った?!Diffusion Modelsについて
3つの要点
✔️ Diffusion Modelsが高精度な画像生成において、SOTAのBigGANに勝利
✔️ 大量なアブレーション実験とテクニックによって、Diffusion Modelsの良いアーキテクチャを探索
✔️ Diffusion Modelsで生成データの忠実度と多様性のバランスをコントロール
Diffusion Models Beat GANs on Image Synthesis
written by Prafulla Dhariwal, Alex Nichol
(Submitted on 11 May 2021 (v1), last revised 1 Jun 2021 (this version, v4))
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
この何年間で生成モデルが人間レベルの文章(GPT-3の真価を引き出す方法 : Promptプログラミング)、高精度な画像(事前学習済みGANモデルを超解像技術へ)、または人間のようなスピーチや音楽を生成できるようになりました。ただし、現状のSOTAモデルを超えて更なる研究が求められており、グラフィックデザイン、ゲームや音楽の制作といった幅広い分野での活用が期待されています。
生成データクオリティが重視されている現在の評価指標においては、GANが主なSOTAを手にしています(GANの発展の歴史を振り返る!GANの包括的なサーベイ論文の紹介(応用編))。一方でGANは訓練時にモデルが崩壊しやすいことや、生成データの多様性が低いことが問題として挙げられています。
本記事では、Diffusion ModelというGANとは異なるアプローチなモデルがついにGANを越えたを主張する論文紹介します。

Figure 1.はDiffusion Modelで生成した画像例で、GANと同様に区別のつかない画像が生成できることが分かります。Diffusion Modelは与えられたシグナルから徐々にノイズを取り除いていくことで、データを生成します。CIFAR-10データセットにおいては既にSOTAを達成したがImageNetのような難しいデータセットにおいてはまだ精度が足りません。
著者たちはDiffusion ModelとGANとの差は、2つあると仮設を立てています。1つ目はDiffusion ModelがGANほどアーキテクチャ探索がされていないこと。2つ目はGANが生成データにおける多様性と忠実性のトレードオフをコントロールできること。この2点を考慮した上Diffusion Modelの良いアーキテクチャを大量な実験によって探し出し、現状のSOTAであるBigGANにも勝てることを示します。
Diffusion Modelの背景
Diffusion Modelはあたえられたシグナルから徐々にノイズを取り除くことで画像を生成します。実際はノイズx_Tからスタートして、x_(T-1),x_(T-2),...,x_0まで辿り着きます。つかりx_tはx_0にt回ノイズを加え続けたものと考えられます。Diffusion Modelはノイズを予測するように学習します。
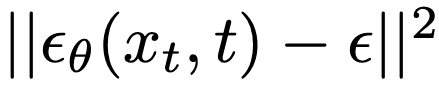
また本論文では全てのノイズをガウスノイズとするため、各x_tからx_(t-1)に移すために消すノイズは次の式で表せます。
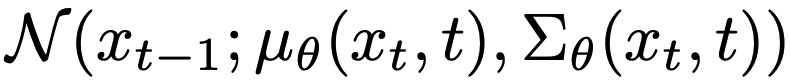
ここで、μはガウスノイズの平均でシグマは分散であり、本研究においては両方ニューラルネットワークで近似を行います。モデルに関する詳細は付録を参考してください。
Model
Architecture Improvements
先行研究で有効性が示されたUNetアーキテクチャーをベースにして、次のようなところにフォーカスしてアーキテクチャ探索を行いました。モデルの深さと広さ、attention機構のヘッド数や異なる解像度、BigGANで用いられる残差ブロックなどです。具体的には対照実験を行いこれらのとるべき値を決めます。

Table 2.からHeadsの数は多い方が良くて、channels数は少ない方が良い(低い)FIDが得られます。
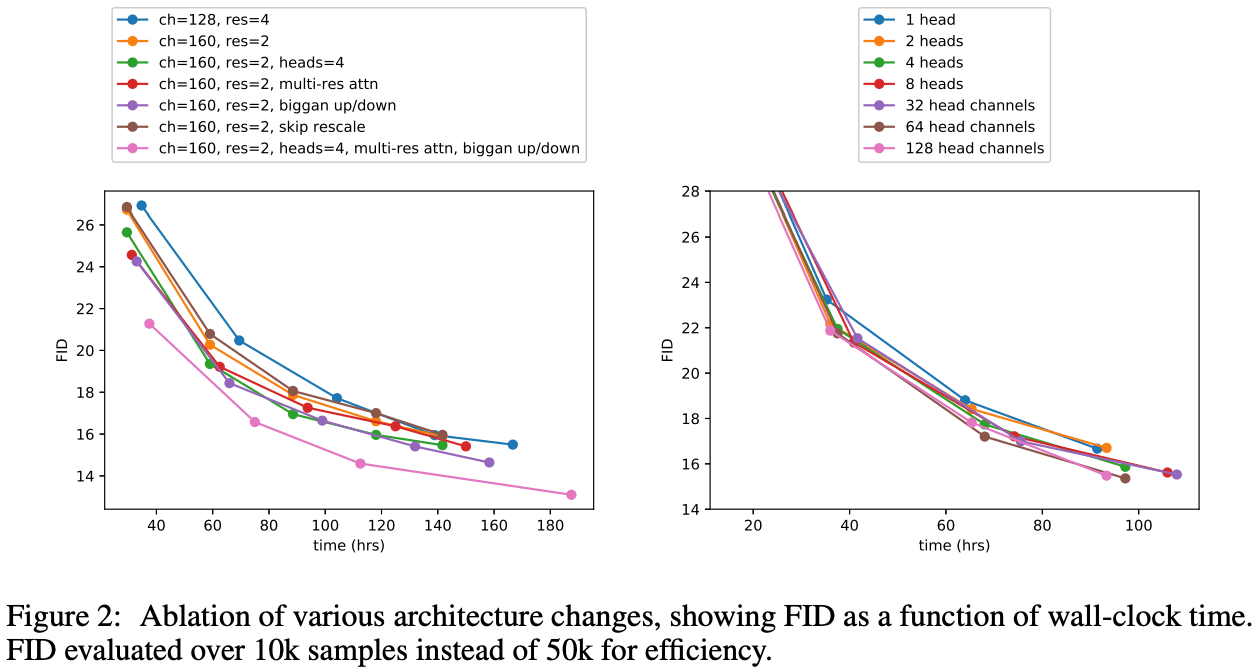
またFigure 2(左)の結果から、 residual blocksの数を増やすこと(res=4, blue)でFIDの値が小さくなるが、同等程度な精度を達するのに訓練時間がかかりました。またピンク線の結果が短い訓練時間で同等程度な結果が得られることと、最終的に低いFIDが得られることが分かります。またHeadsに関してはFigure 2.(右)の結果から64headを採用します。以後の実験では本実験で見つけた最善のアーキテクチャを用いて比較を行います。
Classifier Guidance
GANsではラベルを用いた条件付き生成が効果的であることが知られています。Diffusion Modelsでもそのアイデアを適用すると精度があがることが先行研究で示されました。Algorithm 1と2では、確率過程を仮定するDiffusion Modelsと決定的サンプリング仮定を持つDiffusion Modelsに対してそれぞれをラベル分類器で条件づけるアルゴリズムを示します。


Algorithm 1.のように一般的な確率過程を持つDiffusion Modelsでガウス分布が仮定されています。ラベル分類器条件付けをするのは、ガウス分布を分類器の勾配に比例してシフトを行うことと一致します。一方でAlgorithm 2. に示したような決定的サンプリング過程においてはDiffusion Models自体に分類器の勾配を取り入れます。詳細の導出は論を文のセクション4を参考にしてください。 実際本論文でAlgorithm 1.用いており、ImageNetで訓練したUNetを分類器として用いました。またハイパーパラメータsは生成の精度と多様性のバランスをコントロールできます。
ここまではDiffusion Modelsに対してクラス分類器勾配を用いて条件付けを行ったが、直接条件付けDiffusion Modelsを学習することはもちろん可能です。さらに条件付けDiffusion Modelsに対して分類器勾配を活用するのは、同様な方法でできます。
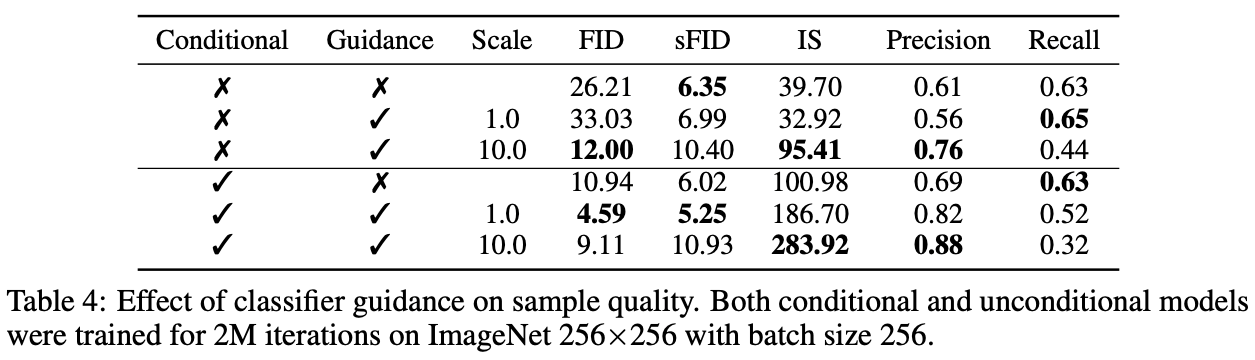
Table 4.ではラベル条件づきで学習するConditional Diffusion Modelsと分類器の勾配を利用するClassifier Diffusion Modelsの効果をまとめました。Conditionalを用いた方が基本にFIDが低くて精度が良いですが、多様性を犠牲にしています。
Table 4.ではラベル条件付きで学習するConditional Diffusion Modelsと分類器の勾配を利用するClassifier Diffusion Modelsによってもたらす効果をまとめました。Conditionalを用いたい方が基本敵にFIDが低くて精度が良いですが、多様性を犠牲にしていることが結果からわかります。
また単にクラス分類器の勾配を利用するのはConditionalのみを用いるのと同等程度なFIDが得られます。
さらに両方をとりいれた方がいい精度が良いことが分かります。またハイパーパラーメータsはPrecisionとRecallのバランスを調整していることも分かります。
比較実験
本研究で最適したアーキテクチャの検証実験は、通常のDiffusion ModelをLSUNデータセットのBedrooms、Horses、Catsクラスで、Conditional Diffusion ModelをImageNetの異なる解像度の画像で行いました。
Table 5.はメイン結果をまとめています。提案手法が全ての実験でベストなFIDを達しており、sFIDの指標でもImageNet 64x64を除いてもっとも良い結果が得られました。
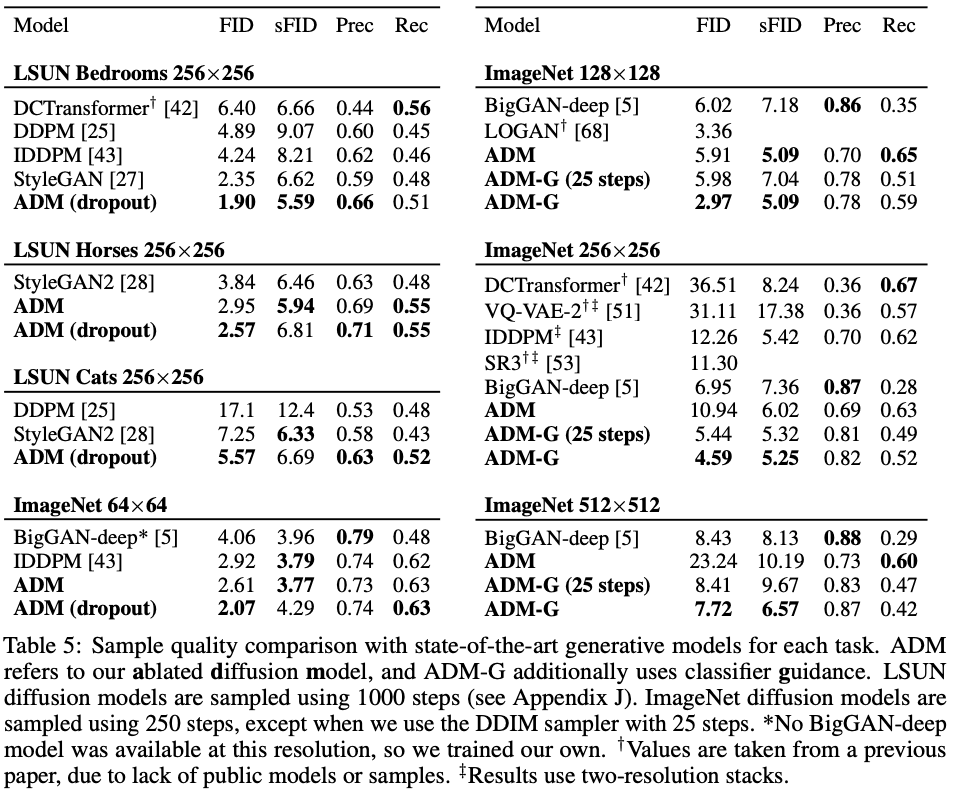

Figure 6. は同等程度なFIDを持つBigGAN-deepの生成サンプル(左)、提案手法(中央)、訓練サンプルを示しています。提案手法はより多様なサンプルが生成できる事がサンプルからわかります。
まとめ
本研究ではDiffusion ModelsがSOTAモデルGANsよりも精度(FID)の良いサンプルを生成できることを示しました。まずはアーキテクチャの探索をGANsの研究に見習いながら行いました。次に得られた効率的なアーキテクチャに加えてクラス分類器の勾配を利用するテクニックを用いました。また分類器の勾配を調整することで生成画像の忠実度と多様性のバランスをコントロールできる事が分かりました。
本記事はGANs主導している画像生成分野において、有望かつGANsほど注目されていないDiffusion Modelsについて紹介しました。またDiffusion Modelsの後続研究がGANのように盛大に盛り上がることを期待しており、紹介させていただきました。




この記事に関するカテゴリー






