まるで現実?G-buffersとレンダリングのパイプラインを用いたPhotorealistic画像の生成!
3つの要点
✔️ G-buffersとレンダリングのパイプラインを用いたリアル画像の生成
✔️ レイアウトの崩れの原因となるArtifacts発生の分析
✔️ GTA Vのシーンをphotorealisticなシーンに転移することに成功
Enhancing Photorealism Enhancement
written by Stephan R. Richter, Hassan Abu AlHaija, Vladlen Koltun
(Submitted on 10 May 2021)
Comments: Accepted by arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR); Machine Learning (cs.LG)
code:

研究の概要
この研究はsynthetic画像(コンピュータで現実世界を表現する画像)のリアルさを追求した研究です。焦点は主にゲームの世界を現実世界のように見せることに置かれており、研究では例としてGrand Theft Auto Vに提案手法を適用させることでリアルなゲーム世界を生成しています。
従来の手法だと、レンダリングの手法を用いて中間層の表現を得るような畳み込みネットワークを改善する、という手法を用いており、このネットワークに対して最新のadversarialな目的関数を使って、そこから複数のperceptualなレベルで超解像になるような学習を行う、というものでした。
しかし、従来研究では制御が困難で、様々なartifacts(人工物または生成画像内の不純物)が生成されてしまい、偽物っぽい画像が生成されてしまうという問題点がありました。そのため、この研究では学習中に画像のパッチをサンプリングする手法や深層ネットワークの多層構造を提案することで、リアルさの向上と安定した画像の生成に成功しました。
総括的なPhotorealistic手法の提案
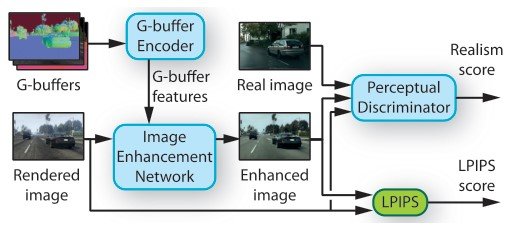
提案手法の概要
提案手法は3つのネットワークで構成されています。①Image enhancement network、②中間層に対するレンダリングバッファ(G-buffers)、そして③Perceptual Discriminatorです。そして最後に敵対的に学習する際にartifactsによるレイアウトの崩れを防止するためにデータセットの分析を行っています。
①Image enhancement network
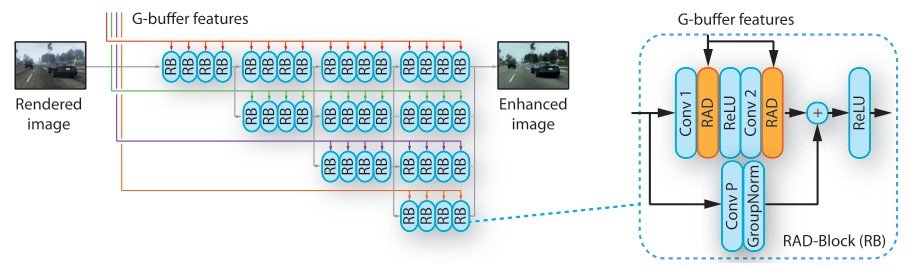
Image enhancement networkはHRNetV2をベースとしている予測タスクに秀でているネットワークで、レンダリングされた画像、そして後ほど説明するG-bufferの特徴量を入力とし、リアルっぽい画像を出力します。入力となるG-bufferは解像度ごとに分かれており、HRNetはこの異なる解像度を扱う複数のブランチを通して画像を並列的に扱います。(画像の色が異なる解像度に対応しています)
この研究では、HRNetを以下の2点において改良しています。
- 完全な解像度を扱い、画像の詳細情報を保つために、最初のstrided convolutionsをregular convolutionsで置き換えています
- residual blocks内で、batch normalization層をrendering-aware denormalization (RAD)モジュールで置き換えています
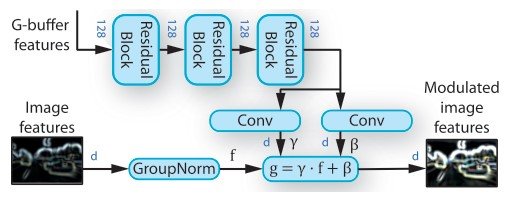
・Rendering-aware denormalization (RAD)
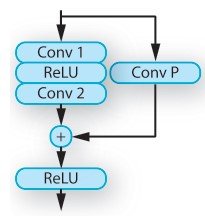
RADは外部情報をベースに特徴ベクトルを調節する役割を持つモジュールです。特に、シーンの表現から重みを学習するモジュールで、G-buffer encoder networkから得た特徴ベクトルを2つのresidual blocksを用いて変換しています。Residual blocksはG-buffer encoderとRADに使われており、畳み込み層とspectral noramlization、ReLUで構成されています。
この変換された特徴量はelementwise scale $\gamma$ とshiftの重み $\beta$の学習に用いられます。下記の図にもある通り、重みは正規化された画像の特徴のアフィン変換のパラメータを表しています。($g = \gamma \dot f + \beta$)ここで、入力となる外部情報はレンダリングを通して得た画像の地理的情報、物体的情報、光情報、意味的情報の特徴ベクトルです。それぞれのRAD moduleに対して3つのresidual blocksを用いてG-bufferの特徴ベクトルを変換しています。
・目的関数
Image enhancement networkは2つの目的関数で学習されています。
- LPIPS lossを用いて入力画像と出力画像間での構造的な違いに対して損失を与えています (LPIPS score)
- perceptual discriminatorによって出力画像のリアルさを評価しています(Realism score)
従来手法と比較して、学習している間、現実の画像パッチとsyntheticな画像パッチにおける特定のサンプリングの手法を用いて、重大なartifactsを減らしています。
レンダリングのパイプライン
リアルタイムレンダリングは、通常複数のパスをレンダリングプロセスに組み込んでいます。有名なものにはdeferred shadingやdeferred lightingなどがあり、見た目や影などの計算結果をG-buffersの結果としてレンダリングされた中間層表現として分解します。G-buffersの特徴として、semanticな情報を与えなくても、semanticなものを理解するように学習できるというものがあり([S. R. Richter et al., A. Shafaei et al.])、地理的、物体的な特徴を捉えネットワークに入力することで、擬似画像からリアル画像への変換がより高精度で行われます。
・G-buffersの抽出
この研究では、G-buffersをGrand Theft Auto Vというゲームから得ることを目的としています。コンピュータゲームからレンダリング用のリソースを抽出する技術を用いて([S. R. Richter et al, S. R. Richer et al., P. Kr¨ahenb ¨uhl])おり、地理的構造(表演、深度)、物体(シェーダーID、反射能、透明度)、光度(近似光輝と放出、空)などの情報をもつG-buffersを抽出しています。

さらに、G-buffersから
- 物体の表面に視点ベクトルを用いてピクセルごとの反射を確認して、反射ベクトルを抽出
- 表面とこの反射ベクトルのドット積を計算
しています。
ここでの結果は本文のセクション4.4にあり(Do G-buffers help?)、G-buffersからの情報を用いなければ低次元の特徴量に対しての計算が荒くなり、G-buffersを加えることでVIPERデータセットにおいてすべての次元の特徴量でリアルなシーンが再現できていることがわかっています。
また、G-buffersをどのように入力するのか(How to ingest G-buffers?)、という実験において、単純に加えたもの(concat)はRADモジュールの代わりにSPADEモジュール([14])を用いたネットワークに比べて、全体的な性能が高い結果となっています。またSPADEモジュールを用いたネットワークはデータセットにおける結果の変動が大きく、リアルな結果もあれば完全に失敗している結果も出力してしまいます。それらに比べこの研究の提案手法のRADモジュールを用いたものは、一貫して高精度な出力が可能となっています。

・G-buffers Encoder
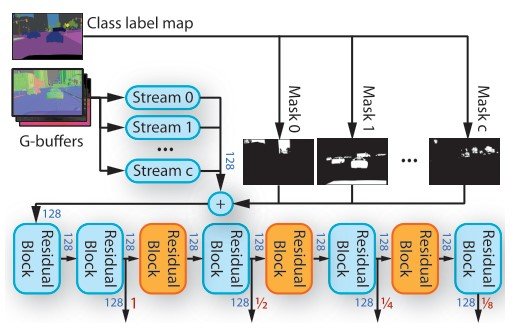
G-buffersでは物質情報、深度画像、通常画像、色画像における深度の連続値、樹木や空などのスパースな連続情報を抽出しています。空などの地理的、物体的な情報を持たないものに対してはG-buffersはゼロのを出力します。G-buffersのそれぞれの情報に対処するために、上図のようなG-buffer encoderを用いています。G-buffers encoderは複数のネットワークstreamを持っており、それぞれのstreamは2つのresidual blocksで構成されています(図8)。このresidual blocksの機構のおかげで複数のスケールでの学習を可能にしています。
$f_c$をオブジェクトクラス$c$をターゲットとしたときのstreamの特徴量テンソルとし、$m_c$をその物体のマスクと表記します。そして物体をマスクしています。($\Sigma_c m_c \cdot f_c$)。
物体のIDはsemanticセグメンテーションマップからの複数のクラスラベルをグループ化しています。これによりG-buffersが物体のタイプをstreamにマッピングすることができます。出力される特徴量テンソルはRADモジュールを通してimage enhancement networkによって入力されます。
Perceptual Discriminator
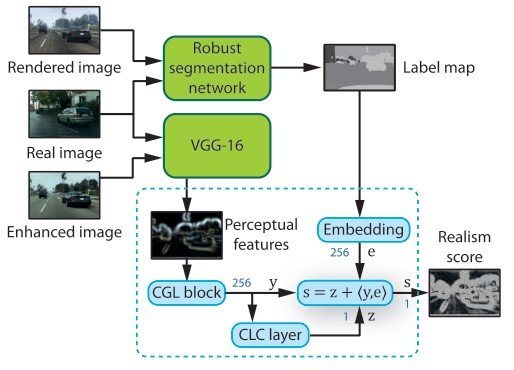
image enhancement networkを学習している際、出力される画像のリアルさはperceptual discriminaotorによって評価されます。このdiscriminatorはロバストなsemanticセグメンテーションネットワーク(MSeg)、perceptual特徴量抽出ネットワーク(VGG-16)、そして複数のdiscriminatorネットワークで構成されています。
このセグメンテーションネットワークをターゲットとなるデータセットと改変していないレンダリングされた画像に適用します。これによりリアル画像とsyntheic画像のsemantic情報を得ます。ここで、synthetic画像で学習してしまうと、リアルなデータに対して汎用性が失われるので注意が必要です。また、リアル画像の生成に必要ないため、セグメンテーションネットワークに対してバックプロパゲーションは用いていません。
リアル画像と高精度化された画像に対してVGGを適用することで、次元ごとの抽象的な情報のperceptualな特徴量を得ることができ、perceptualレベルによってネットワークを適用することが可能となります。
Artifactsによるレイアウトの変化に対する分析
敵対的な設定の時、discriminatorは学習中に画像を識別するためにrealまたはfakeのラベル付けを行います。そしてこの勾配に対してバックプロパゲーションを行うことでgeneratorがよりリアルな画像を生成可能なようにノイズを加えます。
ここで、偽の特徴量でfaceとrealな画像が識別できてしまった場合、例えば偽のGTA Vの空の画像の方を多く学習し、Cityscapesデータセットの同じピクセル位置には木がある場合、GTA Vの空の位置に木が生成されてしまう、といった問題が発生します。

上図の確率深度マップを見てもらうとデータセットからは一様分布で学習しているために、サンプリングする位置の情報が異なると生成する情報に相違が発生してしまいます。

・対応するパッチのサンプリング
上の分析によると、GTAとCityscapesにおいてランダムで画像をサンプリングすると同じ物体情報が得られても期待するレイアウトとは異なるレイアウトが出力されることがわかります。
そのため、ここでは異なるサンプリングの手法を提案しています。まず、全表示画像の7%のみを切り取るようにします。次に、サンプリングしたパッチをdiscriminatorで表示される物体の分布が安定するように調整します。これは切り取ったパッチとVGG16により抽出された特徴量テンソルのピクセルのcosine similirityが0.5よりも高ければ2つのパッチはマッチする、ように計算しています。(詳細は論文をご覧ください)
discriminatorはPatchGANのものを用いています。(Which discriminator?)上記で説明したprojection層は高次元になるにつれ精度が悪くなり、適応的なバックプロパゲーションは最も高次元で精度が向上しています。

実験
実験ではリアルさを評価するためにthe Kernel Inception Distance (KID) を用いています。KIDはsemanticな構造の距離を測っているのですが、リアルさを直接測っているわけではなく、レンダリングした画像の情報が無視されてしまう可能性があります。そのため、inceptionネットワークで得た特徴量をVGGの異なる層の特徴量で置き換える手法を提案しています。(the squared maximum mean discrepancy (MMD))これにより、perceptualな画像の品質を考慮することが可能です。([Q. Chen, R. Zhang])
また、データセット同士での特徴量を得るために用いるパッチの分布をそろえるため、それぞれのデータセットのsemanticラベルマップから画像サイズの1/8のパッチを抽出し、さらにダウンサンプリングします。そして、syntheticデータセット(ここではGTA V)のベクトルをnearest neighborを用いてリアルなデータセットからペアとなるパッチを探します。これにより、以下のようなsemanticに対応するパッチが得ることができます。

・先行研究との比較
ここでは、先行研究とのphotorealism enhancementの精度に関する比較を行います。semanticセグメンテーションラベルを入力として必要とする手法には、MSeg [72]で提案されているsyntheticとrealな画像を用い、提案したdiscriminatorにも同様のロバストなセグメンテーションネットワークを用いました。
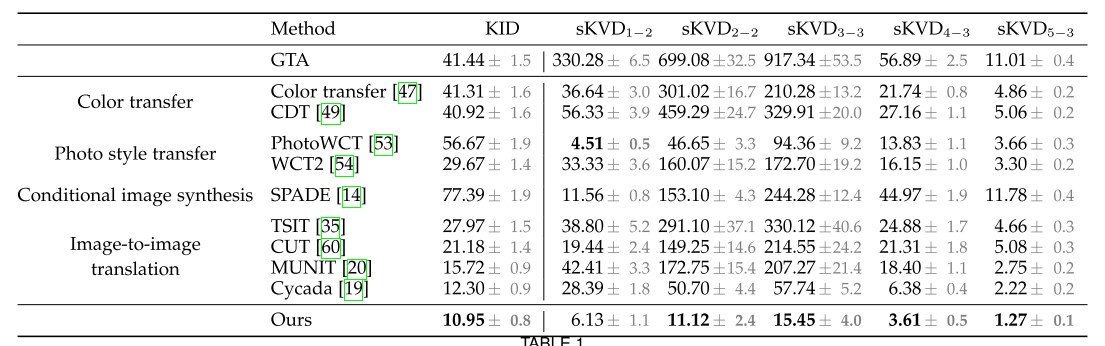
表1の結果を見ていきます。比較の対象実験として、
- Color transfer(色が上手く生成できているか)
- Photo style transfer(画像のスタイルが上手く生成できているか)
- Conditional image synthesis(ある条件下で画像が再現できているか)
- Image-to-image translation(画像が他のドメインで生成できているか)
の4つを行っています。
Color transferでは、色の遷移(Color Transfer)、色の分布の遷移(color distribution transfer: CDT)と比較しています。これらの手法を用いるとピクセルの色を制限してしまい、テクスチャの表現力の向上が困難になったり、artifactsを発生させる要因になっています(以下の図を参照)。結果、低次元の特徴量の評価においてより大きな改良が見られています。

Photo style transferでは、fast photographic style transferの閉形式(解が存在する式)の解 (PhotoWCT)、現在のSoTAのwavelet transforms (WCT2)と比較しています。それぞれのアプローチはソースとスタイルの画像にスタイル画像とsemanticセグメンテーションマップを必要とします。color transferと異なる部分は、ピクセルの色を変換するわけではなく、セマンティックセグメンテーションによって導かれた学習済みの高次元の特徴量空間を変換していることです。よって、color transferよりも強力に変換されます。
しかし、photo style transferは入力画像にマッチするスタイル画像に依存します。そのため、入力画像が変化すると、syntheticな環境をインタラクティブに学習することでphoto style transferは非現実的な色の遷移や一時的に不安定な画像を生成してしまいます。
Conditional image synthesisでは、最も強力なSPADEと比較しています。用意した都市部での画像で学習していますが、結果はSPADEがどの手法よりも精度が低くなりました。理由としては、semanticセグメンテーションマップのみからの写真を合成することは、単に画像を修正するよりも難しく、またSPADEは画像をCityscapesデータセットの画像に合成するように学習されているので、CityscapesとGTAの間でシーンレイアウトの分布の遷移が発生するためです。
Image-to-image translationでは、Cycada や他の様々な手法と比較しており、Cycadaは合成画像をリアルな写真に変換することに特化した手法です。この手法では、低次元の特徴量のcycle-consistencyとsemantic consistency loss(合成画像の情報を保存するためのsemanticラベルを扱う)を用いてピクセルレベルのcycle-consistencyを用いています。
これらの手法の中でCycadaが一番良い精度を出しましたが、perceptual loss(視覚的に捉えられる違い)よりもsemanticな情報をより用いていましたが、図にもある通り関係のない物体を生成してしまいます。これはおそらくセグメンテーションネットワークを改変していない合成画像で事前学習し、画像の合成ネットワークの学習中に更新していないことが考えられています。(図11)
まとめ
この研究では、G-buffersの情報を上手く特徴量空間に落とし込み、レンダリングの技術を用いて、スケールごとに高精度画像を生成するネットワークであるImage Enhancement Networkを学習させたことがphotorealisticのタスクにおいて、うまく行った要因であると考えられます。また、データセット同士の確率密度分布を比較することによる分析はArtifacts発生の要因を捉えたのではないかと思われます。将来、GTAや他のテレビゲームがリアルと区別のつかなくなる日が来るかもしれませんね!





この記事に関するカテゴリー



