AIが難病を治療!?強化学習を活用した、パーキンソン病の服薬管理の提案!
3つの要点
✔️ パーキンソン病は、病態進行にともない、多くの要因が変化することから、服薬管理に対する意思決定の困難さが指摘されている
✔️ 強化学習を活用し、個人特性を考慮した、PDの運動症状を最小化するモデルを提案している
✔️ 本評価結果から、RLの導入により、パーキンソン病管理を強化できるモデル開発が期待される
Computational medication regimen for Parkinson’s disease using reinforcement learning
written by Yejin Kim, Jessika Suescun, Mya C. Schiess, Xiaoqian Jiang
(Submitted on 129 Apr 2021)
Comments: nature
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
背景
AIは専門医よりも効果の高い治療方針を打ち出せるのか?
本研究では、強化学習—Reinforcement Learning: RL—を活用し、難治性疾患である、パーキンソン病—Parkinson Diseases: PD—における、運動症状を最小化を目的とした学習モデルを提案する。
PDは、急速に増加している神経変性疾患の一種であり、患者数・経済的コストが増加し続けている。治療では、ドーパミンの補充による緩和治療が主流である一方、病態進行にともない多くの要因が変化することから、服薬管理の困難さが、課題としてあげられる。また、治療ガイドラインが提唱されている一方、個人特性などを考慮した介入をおこなう必要があり、意思決定には膨大な要因を考慮する必要がある—実臨床現場では、低用量の単剤療法から開始し、患者の反応や病態に応じ、投与量の調整・補助療法を追加、をおこなっている。このプロセスでは、PDの運動症状を考慮し、QOLを向上させる適切な薬剤の組み合わせを決定する必要がある;こうした意思決定では、多くの要因を考慮し柔軟に対応する—患者の状態に応じて適用的に変更するなど—必要があり、人間の手による決定が困難である。本研究では、RLを活用し、個人特性—各PDの病態—を考慮した、頑健性の高い最適な薬の組み合わせの導出を目的としている。
パーキンソン病—Parkinson Diseases: PD—とは?
まず初めに、本研究の解析対象である、パーキンソン病—Parkinson Diseases: PD—について簡単に解説する。
パーキンソン病—PD—は、近年、急速に増加している神経変性疾患—指定難病—の一種で、脳の異常のために、体の動きに障害があらわれる。主な症状は、運動障害—振戦:ふるえ、動作緩慢、筋強剛:筋固縮、姿勢保持障害:転びやすいこと、など—がある。また、運動症状以外の症状として、下記のような症状がある:便秘;頻尿;発汗;易疲労性—疲れやすい—;嗅覚の低下、;起立性低血圧—立ちくらみ—;気分が晴れない—うつ—;興味が薄れる・意欲が低下する。PDは、2040年までに、世界で1750万人が罹患すると予測され、1990年以降、有病率は74.3%増加しており、米国での年間経済的負担は520億ドルと推定されている。PDに対する治療方針では、薬物療法が主流である—ドパミン神経細胞の減少が発生するため、少なくなったドパミンを補填し、症状を緩和する治療;一方、服薬をはじめとする薬理学的な管理は、病態の進行など、個人要因をはじめとする、多様な要因が変化するため、意思決定の難しさが課題となっている。
研究目的
本研究では、強化学習—Reinforcement learning: RL—を活用し、PDの運動症状を最小化するための最適な治療方針を目指す。
前述のように、PDでは、個人要因を考慮した治療方針を決定する必要があるため、複雑かつ膨大な要因が絡み合い、人の手による意思決定が困難な側面がある。そのため、本研究では、RLを用いて、個人特性を考慮した最適な治療方針の導出を目指す。RLモデルを臨床現場で活用することを考えた際、2つの懸念—解釈可能性と頑健性—が考えられる:現場の医師に対するモデルの指針の明瞭さ—解釈可能性—や、学習間における導出方針の一定性—頑健性—、が重要である。そのため、本研究では、解釈可能性に対して決定木回帰を、頑健性に対してアンサンブル学習、を活用し、臨床的有用性の向上を目指す。
手法
本章では、提案手法の概要について述べる。本手法は、PD患者の縦断的観察コホートであるParkinson's Progression Markers Initiative—PPMI—データベースを用い、マルコフ決定過程—Markov Decision Process : MDP—による環境構築・反復学習をおこない、臨床的に関連性の高い病態と、最適な薬剤の組み合わせを導出した。また、8つの治療薬—ドパミンアゴニストであるレボドパと他のPD治療薬—の組み合わせをエージェントの選択肢として、運動症状の評価指標である、Unified Parkinson Disease Rating Scale—UPDRS—IIIに基づくスコアを報酬・罰則として、設定した。
データセット
ここでは、提案手法に活用した、データセットの概要を述べる。
本研究では、後ろ向きコホート研究として、PPMIを活用している。PPMIは2010年に開始された観察研究で、Hoehn and Yahrステージ、UPDRS IIIなどの臨床評価と投薬—レボドパ、ドーパミン作動薬、他のPD治療薬—を収集している。解析では、431人の早期PD患者を対象とし、55.5ヶ月のフォローアップを受けた、計5077回の受診を分析した。UPDRS IIIのスコアや投薬記録がない患者は除外している。また、ほとんどのケースで、レボドパ、ドパミンアゴニスト、その他のPD治療薬—MAO-B阻害薬、COMT阻害薬、アマンタジン、抗コリン薬—を組み合わせた治療が実施されていた。PDの進行速度を測定するため、UPDRS IIIの総得点の変化率を計算した。
マルコフ決定過程—Markov Decision Process: MDP—の活用
本章では、提案手法におけるMDPの活用法、について述べる。
薬物管理は、3つの要素—現在の病状、薬物療法の選択肢、UPDRS IIIの総得点—から構成され、臨床医は、現在の病状に基づき、薬の組み合わせを決定する—この組み合わせは、運動症状に影響を与え、現在の病状を変化させるもの、として解釈できる。このモデルの目的は、こうした組み合わせに基づく、最適な薬物療法を選択、UPDRS IIIにおける総スコアの最小化である。
本研究では、マルコフ決定過程—Markov Decision Process: MDP—を用いて、治療法をモデル化している。MDPでは、エージェントが見積もり報酬を最大化させるように行動を選択する—エージェントは、膨大な行動を探索し、累積報酬が最大となるように最適な行動を選択する。各要素の設定は、下記の通りである:
(1) 状態 𝑠: 現在の診察時の病状作用
(2) 行動 𝑎: 治療薬であるレボドパと他のPD治療薬の8つの組み合わせ
(3) 報酬/ペナルティ 𝑟(𝑠,𝑎,𝑠’): 患者さんの薬に対する反応:具体的には、累積UPDRS IIIスコアと、行動𝑎での薬の数に加重定数𝑐を乗算した値
定式化にあたり、決定木回帰を活用し、複数の要素—PDサブタイプ、Hoehn and Yahrステージ、受診時の年齢、UPDRS III総スコア・変化率など—を用いて、疾患状態を定義した。これら状態間の遷移確率は、PPMI 軌跡で観測された各遷移をカウントし、遷移の総数で除算している。また学習には、TD学習を活用し、RLモデルを構築している。
治療方針に関するアンサンブル
この章では、治療方針のロバスト性—頑健性—を高めるアンサンブル学習について述べる。
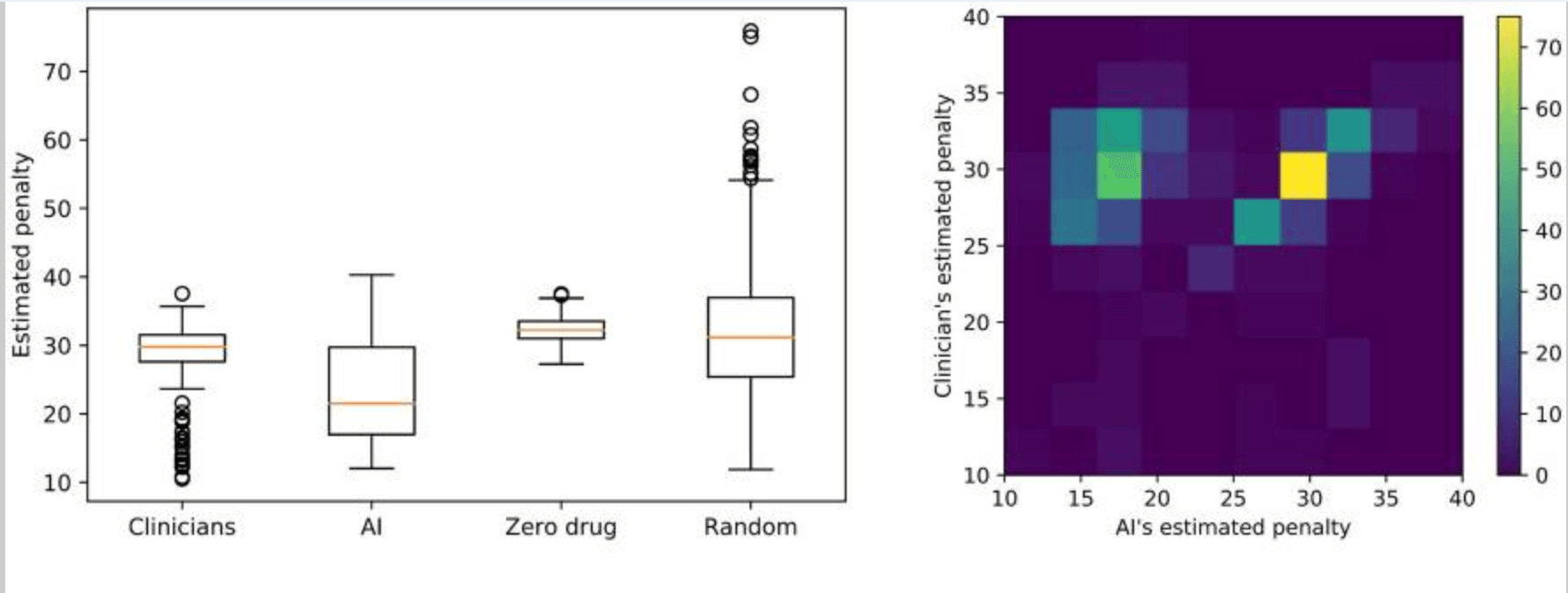
RLによって提案された、治療方針のロバスト性—学習間での一貫性—を高めるため、アンサンブルの手法を活用している。手順は、下記の通りである:データセットを80%のトレーニングと20%のテストに分ける;トレーニングからRLと臨床医による治療方針を導出し、テストセットでこれらの推定報酬—またはペナルティ—を評価する;トレーニングとテストをランダムに500回再サンプリングし、推定報酬の分布(下図)を計算する。その後、500回のブートストラップをおこない、多数決により、最適な治療方針を選択する。
結果
このセクションでは、RLモデルにより導出された治療方針に対する評価結果を述べる。
最初に、多変量回帰モデルを用いて、臨床評価点—病態—と薬物—作用—が、UPDRS IIIスコア—ペナルティ—の予測に対し、統計的有意性を持つことを確認した(下表)

続いて、統計的に有意な変数、および、決定木回帰モデルを用いて、UPDRS III総スコアを対象に回帰をおこない、関連する病態を導出した。疾患状態は、運動性硬直型、振戦優位型、混合型となり、対応するスコアは、21、4、3、となった。本研究では、病態をUPDRS IIIの総スコアと変化—前回と今回の差分値—、年齢、から定義した。その他の変数—認知スコア、Hoehn and Yahr病期など—は統計的に有意であった一方、決定木回帰での有意性は低かったため、病態の定義に使用していない。
RLモデルは、疾患状態から、ペナルティ—UPDRSスコアの累積値—の中央値が最小となるような最適な行動を導出した(下図)。
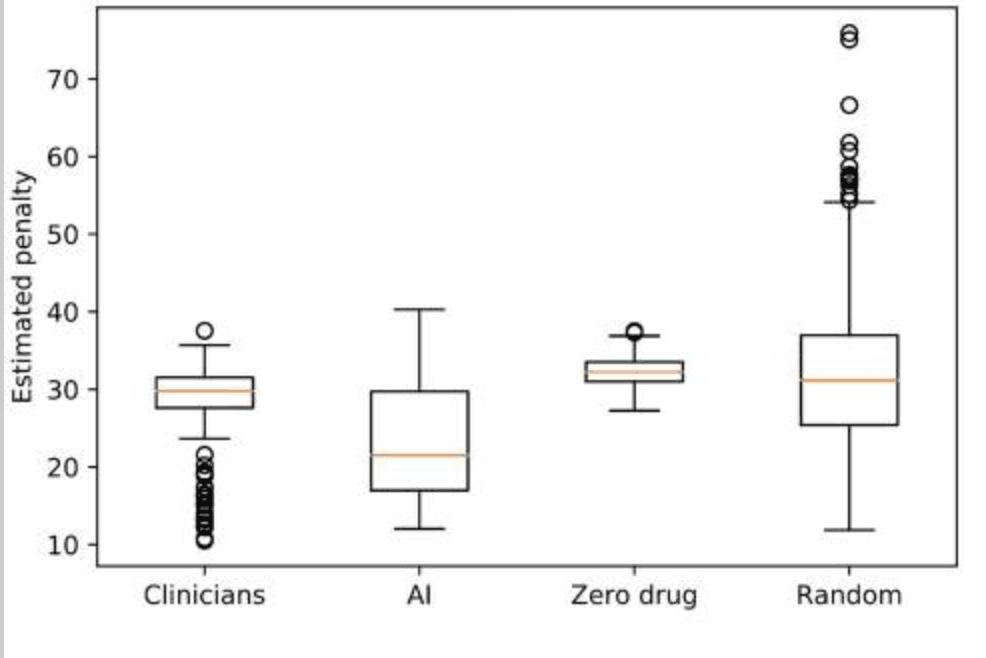
ペナルティ値の中央値は、臨床医が29.8、AIが21.5で、範囲と分散は、下記のようになった:臨床医:min=10.5,max=37.6,var.=16.1;RL:min=12.0, max=40.3,var.=47.4。これらの結果から、提案モデルによる投薬方針は、不安定さがある一方、より低いペナルティ—運動症状が少ない—となった;一方、臨床医による投薬方針は、安定性が高い一方、高いペナルティ—運動症状が多い—が示唆された。同じトレーニング/テストセットを用いて、RLと臨床医のペナルティ分布を比較した際、RLのペナルティスコアは、臨床医より小さい、もしくは、同程度であった。加えて、臨床医と提案モデルから導出された投薬方針ではゼロまたはランダム方針よりも有意に低いペナルティを達成していた—t値=-16.7,p値=1e-55:臨床医 vs ゼロドラッグ,t値=-6.2,p値=1e-10:臨床医 vs ランダムドラッグ。
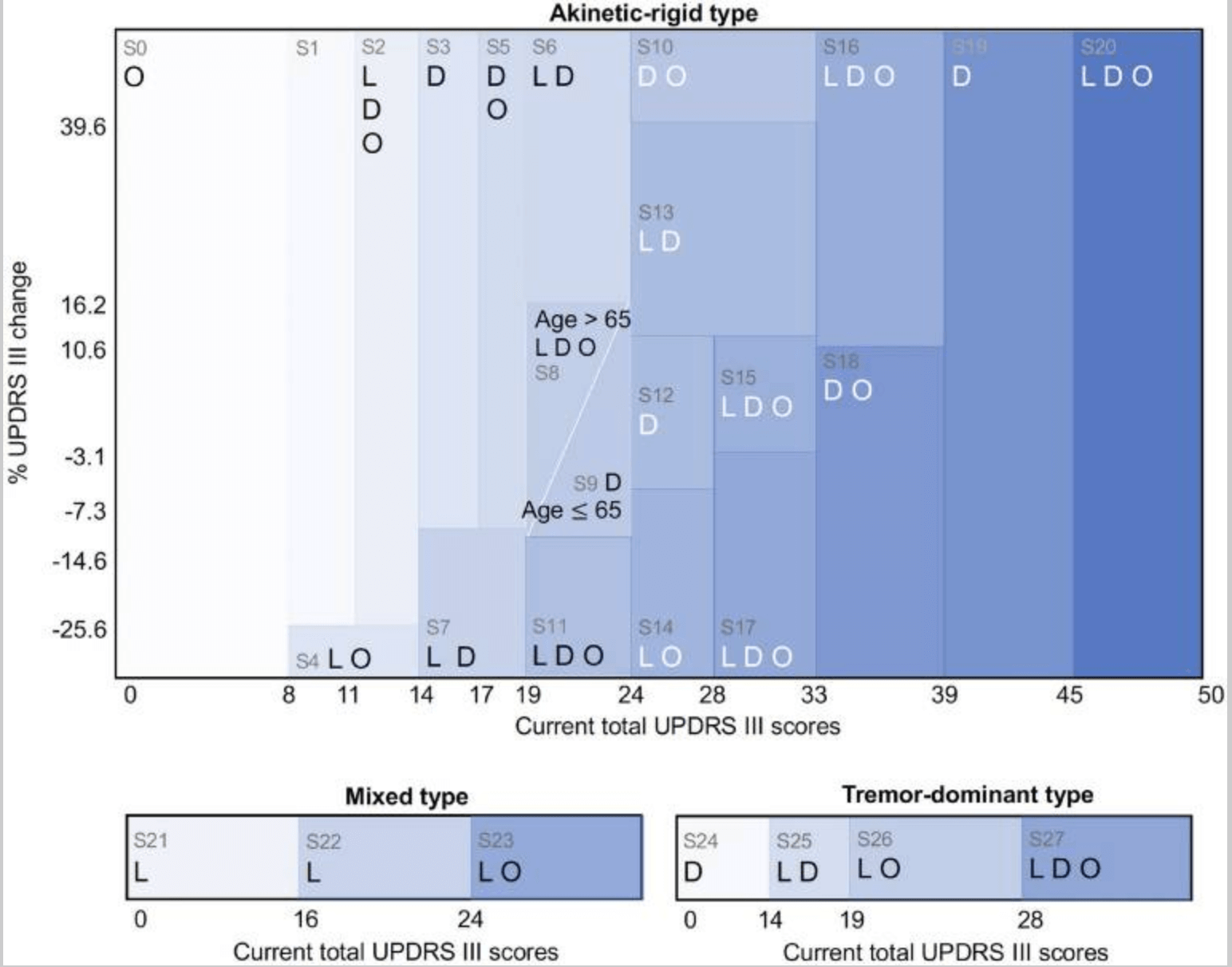
また、臨床医による治療方針とRLによる推奨行動(下図)は、ほとんど同じ方針であった一方、RLモデルでは、特定の病態の変化を併せて提案していた—28状態のうち、16において、RLは臨床医と同じ行動を、12で異なる行動を提案した:例えば、UPDRS IIIの累計スコアが9~11の運動性硬直型PDの初期段階である病態1において、臨床医はドパミンアゴニストを処方するが、RLモデルは薬剤を控えること、を提案している。状態9—運動性硬直型PDの軽症—では、UPDRS IIIの合計スコアが20~24点、年齢が65歳未満において、臨床医はレボドパとドーパミン作動薬を処方する一方、AIモデルはドーパミン作動薬のみの服用を示唆している。
考察
本研究は、RLを活用することで、PD病の運動症状に対する頑健な最適薬物併用法の導出モデルの構築をおこなった。構築にあたり、PD患者の観察的縦断コホート—PPMI—を用いて、マルコフ決定過程の反復により、各病態に対する最適な薬の組み合わせを提案した。導出された組み合わせの結果、提案モデルでは、臨床医と同等の性能を持つ、薬物療法を出力し、臨床医より低いレベルの運動症状重症度スコアを達成した;一方、臨床医による治療方針は、提案モデルより一貫性を持っていた。提案モデルは、臨床医の治療方針をベースとしつつ、複数の変更点を提案しており、これらが、重症度低下の差につながった。
提案モデルの強みとして、外来において利用できる点が考えられる:重症度に対する表記を活用し解釈が容易である。また、PDにおけるサブタイプを初期ノードとすることで、臨床医の経験に基づく、病態定義をおこなった;そのため、本研究で定義された病態は、臨床的に解釈しやすいと考えられる。
一方、課題として、下記のものが想定される:提案モデルの一貫性の低さ;UPDRSスコアの一貫性の欠如。提案モデルは、より高い性能—UPDRSスコアの低下—を示している一方、推定ペナルティに対してばらつきが大きい結果となった—臨床医による投薬指針より、異なる試験間での一貫性が低い。これら、行動空間—各病態における薬剤の組み合わせ—における、試行錯誤的な探索に起因している、と考えられる。解決策として、アンサンブル学習—ランダムフォレスト、gradient boosting—における精度向上や、RLと医師の治療方針を組み合わせることによる、相互補完が検討される。また、UPDRS変化率として、正常な病気の進行と一致しない負の値が示されるケースがあった;理由として、解析対象としたデータセットにおけるコホート規模の小ささ、UPDRS IIIスコアにおける一貫性のなさ、が考えられる。解決策としては、このスコア以外の手法を導入し、運動機能を評価することを検討している。




この記事に関するカテゴリー





