アノテートされたデータがないドメインで固有表現認識!?
3つの要点
✔️ 弱教師あり学習の手法でラベリングされたデータセットがないドメインでの固有表現認識
✔️ 複数のラベリング関数と隠れマルコフモデルによる、ドメイン外のデータセットのラベリング
✔️ 2つのデータセットで従来のドメイン外の固有表現認識のモデルから7%の性能向上
Named Entity Recognition without Labelled Data: A Weak Supervision Approach
written by Pierre Lison,Aliaksandr Hubin,Jeremy Barnes,Samia Touileb
(Submitted on 30 Apr 2020)
Comments: Published by ACL 2020
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG); Machine Learning (stat.ML)
はじめに
固有表現認識(Named Entity Recognition: NER)とは、テキストから人名、地名、日付などの固有表現を抽出するタスクです。テキストの単語ごとに人物であることを示す<PERSON>、日付であることを示す<DATE>などのラベル付けをモデルによって行います。また固有表現ではない単語にはそれを表す<O>がつけられます。このタスクは以下のような様々なタスクの要素の1つになっています。
- 機械翻訳
- 対話モデル
- Question Answering
- 情報抽出
- 文書匿名化
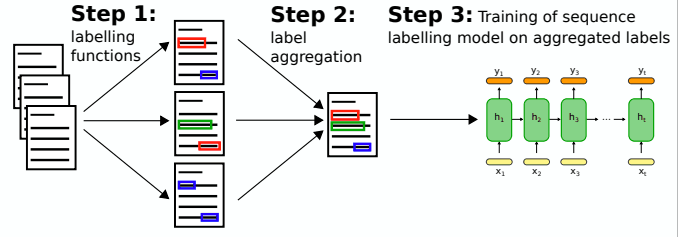
このように重要なタスクである固有表現認識ですが、ターゲットのドメインがソースのドメインと異なっていると急激に性能が低下してしまうことが知られています。逆にターゲットのドメインに一致した学習データがあれば固有表現認識でも転移学習が有効です。よってこの記事では、対象のドメインの学習データがないときターゲットのテキストに自動的にラベリングを行う手法を紹介します。おおまかに以下の2つの手順でターゲットテキストを自動的にラベリングします。
- 複数のラベリング関数でそれぞれテキストにラベル付けを行う
- 隠れマルコフモデルによりバラバラにラベリングされたデータを1つに集約する
そしてこのように集約されたデータを使ってモデルを訓練することで、学習データがないドメインのテキストに対して固有表現認識を行うことができます。
また今回紹介する手法はオープンソースとしてGitHubに公開されています。
https://github.com/NorskRegnesentral/weak-supervision-for-NER
続きを読むには
(5395文字画像4枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






