リモート・センシングのための自己教師マテリアル・テクスチャ表現学習
3つの要点
✔️ リモート・センシングデータの下流タスクのために必要な、高い帰納バイアスを持つ特徴量を取得するために、新しいマテリアル・テクスチャベースの自己教師学習手法を提案した。
✔️ 教師ありと教師なしの変化検知、セグメンテーション、土地被覆分類実験において、本手法で事前学習したモデルはSOTAを記録した。
✔️ 自己教師学習に用いた、変化していない領域での多重時間の空間調整された、大気処理済リモート・センシングデータセットを提供した。
Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks
written by Peri Akiva, Matthew Purri, Matthew Leotta
(Submitted on 3 Dec 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Image and Video Processing (eess.IV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
自己教師学習は、アノテーションデータ無しで画像の表現特徴量を学ぶことを目的としています。また、下流タスクで、ネットワークの重みを自己教師学習で学習した重みに初期化することで、収束が早くより高い性能を得ることがあります。しかしながら、自己教師学習では高い帰納バイアスを必要とします。本論文では、MATTER(MATerial and TExture Representation Learning)と呼ばれる、マテリアル・テクスチャベースの自己教師学習を提案しました。MATTERでは、輝度や視角不変量を取得するために、変化していない領域での多重時間の空間調整されたリモート・センシングデータを学習しました。
手法
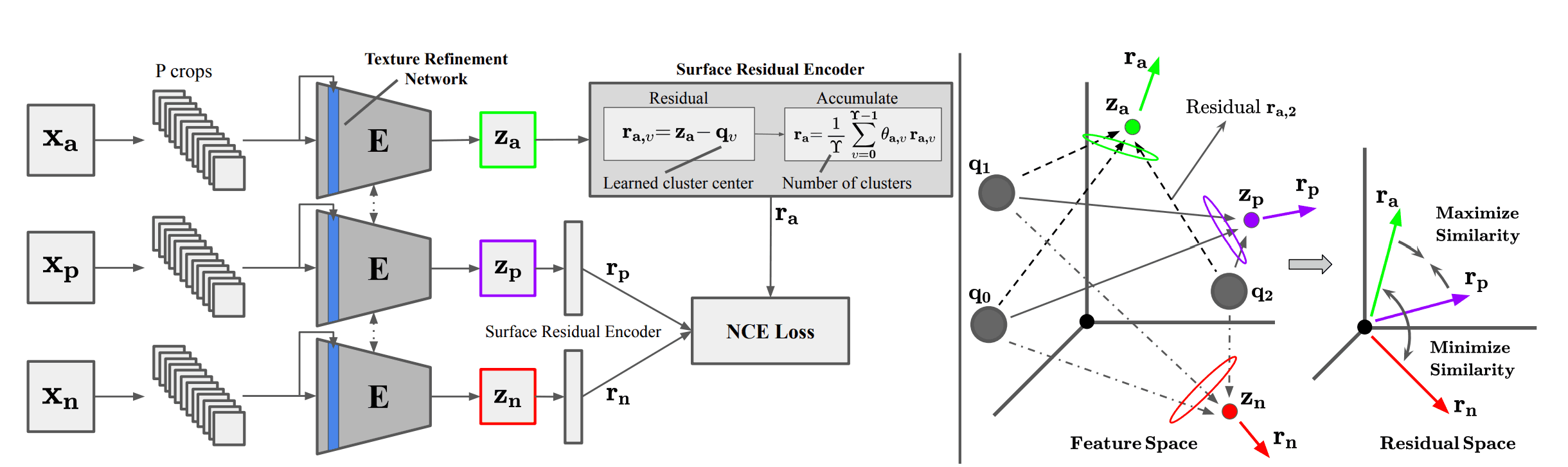
MATTERの概略図は下図のようになります。変化していない領域でのアンカー画像$x_a\in {\cal R}^{B\times H \times W}$が与えられた時、同一領域の正の画像$x_p\in {\cal R}^{B\times H \times W}$と別の領域の負の画像$x_n\in {\cal R}^{B\times H \times W}$を得ます。ここで$B,H,W$は入力画像のバンド数、高さ、幅です。全ての画像をサイズ$h\times w$のPパッチにタイル化し、それぞれ$c_a, c_p, c_n$とします。マテリアル・テクスチャ中心特徴量を学ぶために、Texture Refinement Network(TeRN)とpatch-wise Surface Residual Encoderを提案します。TeRNは、テクスチャ表現量に必要な低レベル特徴量のアクティベーションを増大することを目的とし、Surface Residual Encoderは、表面ベースの残差表現量を学習するために、先行研究のDeep-TENをパッチワイズに適用したものです。ネットワークは正のパッチペア$c_a, c_p$の特徴量距離を最小化し、負のパッチペア$c_a, c_n$の特徴量距離を最大化することで学習します。ここで特徴量は学習された残差表現量です。目的関数として、ノイズ・コントラスティブロスを用いました。
$${\cal L}_{NCE}=-{\mathbb E}_C\left[{\log}\frac{\exp (f(c_a)\cdot (f(c_p))}{\sum_{c_j \in C}\exp (f(c_a)\cdot f(c_j))}\right]$$
ここで$f(c_j)$はパッチ$c_j$の特徴量、$C$は正負のパッチ集合です。
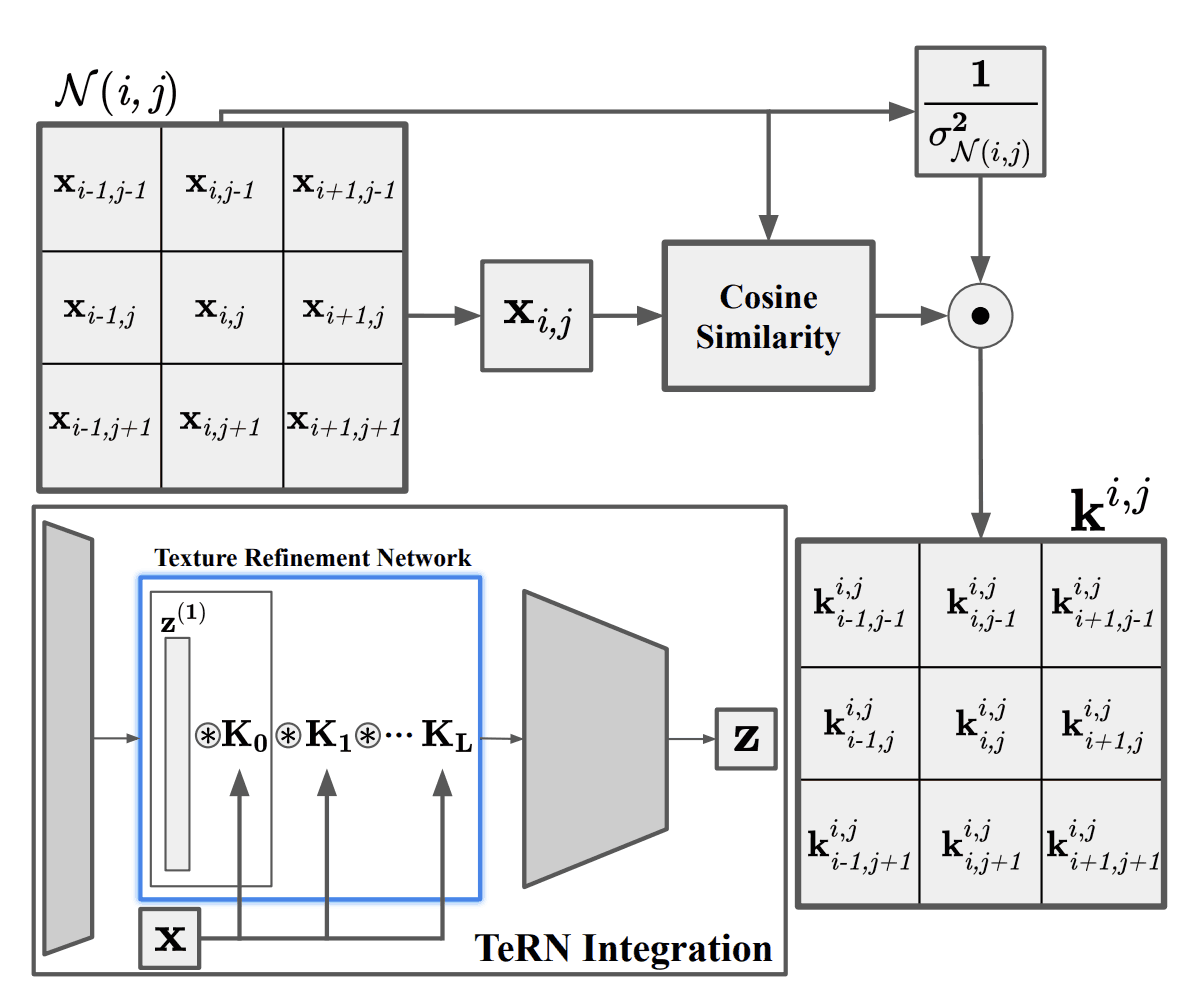
Texture Refinement Network
TeRNでは、衛星画像などで低レベルになってしまうテクスチャ特徴量を精製します。近年提唱されたピクセル適応畳み込み層を採用し、位置$(i,j)$を中心としたカーネル$k^{i,j}$が与えられた時、ピクセル$x_{i.j}$と近傍点${\cal N}(i,j)$とのコサイン類似度を計算し、近傍内の全ピクセルの標準偏差$\sigma_{{\cal N}(i,j)}$の二乗で割ります。
$$k^{i,j}=-\frac{1}{\sigma^2_{{\cal N}(i,j)}}\frac{x_{i,j}\cdot x_{p,q}}{||x_{i,j}||_2\cdot ||x_{p,q}||_2}, \forall p,q \in {\cal N}(i,j)$$
上式は中心ピクセルとの類似度とカーネル内の勾配強度を表します。テクスチャは構造の空間分布を表すので、勾配強度に直結します。単一のカーネル層を$K$とし、$L$層の精製ネットワークを構築しました。
Surface Residualの一致性の学習
本手法ではパッチワイズのクラスタリングを行います。少量パッチの残差を学習し、対応する多重時間のパッチ残差との一致性を強要します。いくつかのクロップ$c_i$に対して特徴量ベクトル$z_i^{1\times D}$, $\Upsilon$個の学習済クラスタ中心$Q=\{q_0,q_1,\cdots,q_{\Upsilon-1}\}$が与えられた時、$z_i$とクラスタ中心$q_v$の残差は$r_{i,v}^{1\times D}=z_i-q_v$となります。これを全てのクラスタで繰り返し、重み付き平均を取ることで、最終的な残差ベクトルは次のようにして得られます。
$$r_i = \frac{1}{\Upsilon}\sum_{v=0}^{\Upsilon-1}\theta_{i,v}r_{i,v}$$
ここで$\theta_v$は学習済クラスタ重みです。これを用いることでクラスタ間の親和性を考慮することができます。
実験
事前学習
自己教師学習するために、都市化されていない地域における、オルソ補正された、大気処理済のSentinel-2データを用いました。最終的に$27$地域の計$1217 km^2$の領域が集められ、$14857$個の$1096\times 1096$タイルを得ました。
変化検知
データセットとしてOnera Satellite Change Detection(OSCD)を用いました。また、事前学習モデルのみの自己教師学習モデルと、その後教師データでファイン・チューニングした教師ありモデルの二通りで評価しました。変化箇所は、前後画像の残差特徴量のユークリッド距離が閾値を超えた場合としました。結果は下表のようになりました。自己教師と教師ありの両方において、F1スコアはSOTAを記録しました。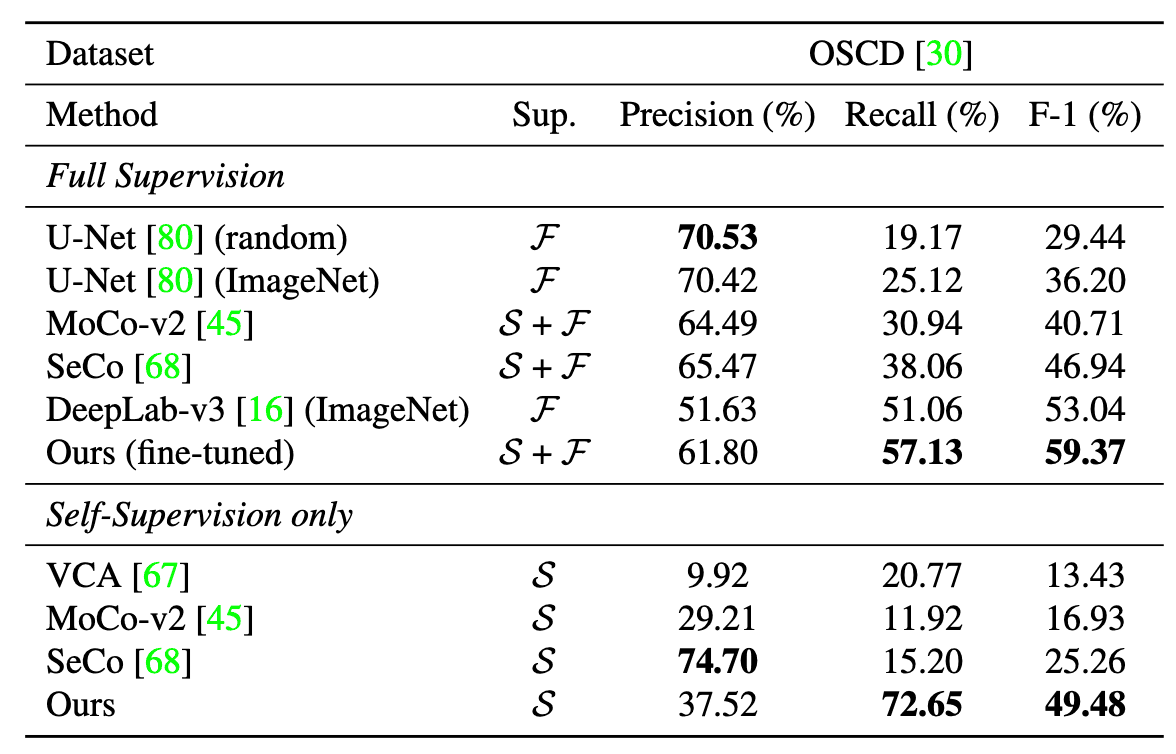
土地被膜分類
データセットとして、19クラスの土地被膜ラベルを持つBigEarthNetデータセットを用いました。結果は下表のようになりました。本手法は、平均精度のSOTAを記録しました。

セグメンテーション
データセットとして、建物セグメンテーションのSpaceNetを用いました。結果は下表のようになりました。本手法は、平均IoUのSOTAを記録しました。

結果
本手法を導入することによって、下流タスクに対して収束が早く、より高い精度を達成し、テクスチャとマテリアルが重要な特徴量であることが分かりました。また、マテリアルとテクスチャを表現できているか定性的に評価するために、visual word map(ピクセルワイズのクラスタリング)を比較しました。結果は下図のようになりました。Textonsではピクセル値を評価するため、テクスチャの微小変化に対しても敏感になり、同じクラスが複数のクラスタに分かれています。Patch-wise Backboneでは、低レベル特徴量の情報を失い、複数クラスを単一のクラスタにしています。一方で本手法は、非常に入力画像に近い分類をしています。

まとめ
本論文では、MATTERと呼ばれる、テクスチャとマテリアルを学ぶ自己教師学習手法を提案しました。MATTERは、表面変化に強い相関を持つ特徴量を学習し、リモート・センシングタスクへの事前学習にも応用することができました。





この記事に関するカテゴリー