【ArtCoder】スタイル変換でアート風のQRコードを生成!?
3つの要点
✔️ Neural Style Transferを利用し、アート風のQRコードを生成
✔️ 三つの損失関数をもとにしたエンドツーエンドのQRコード生成手法を提案
✔️ 実際のアプリケーションでも読み取り可能である、ロバストなQRコード生成に成功
An End-to-end Method for Producing Scanning-robust Stylized QR Codes
written by Hao Su, Jianwei Niu, Xuefeng Liu, Qingfeng Li, Ji Wan, Mingliang Xu, Tao Ren
(Submitted on 16 Nov 2020)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
本記事では、Neural Style Transferを用いて、アート風のQRコードを生成する研究について紹介します。
提案手法(ArtCoder)では、一般的な画像スタイル変換のように、元となる画像(Content)とターゲット画像(Style)と設定したいメッセージから、以下のようなQRコードを生成することができます。

この画像をスマートフォンなどで実際に読み取ってみると、"Thank you for reviewing out paper."という文字列が表示されます。
提案手法(ArtCoder)
パイプライン
提案手法のパイプラインは以下の通りです。
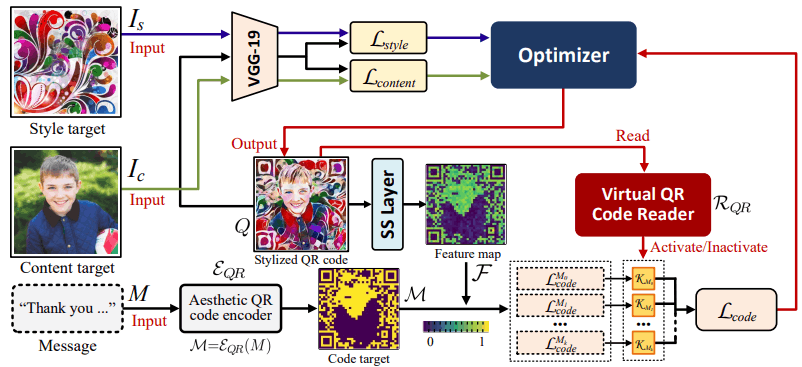
提案手法は、スタイル画像$I_s$、コンテンツ画像$I_c$、メッセージMから、QRコード$Q=\Psi(I_s,I_c,M)$を生成する関数$\Psi$としてモデル化されます。
このとき、$Q=\Psi(I_s,I_c,M)$の目的関数(損失関数)$L_{total}$は、三つの損失関数を組み合わせた以下の式で定義されます.
$L_{total}=\lambda_1L_{style}(I_s,Q)+\lambda_2L_{content}(I_c,Q)+\lambda_3L_code(M,Q)$
$\lambda_1,\lambda_2,\lambda_3$は三つの関数の重みを示すパラメータにあたります。
また、スタイル損失$L_{style}$、コンテンツ損失$L_{content}$、コード損失$L_{code}$は、それぞれQRコードのスタイル、コンテンツ、メッセージ内容を保持するために用いられます。以下、それぞれの損失について順番に見ていきましょう。
スタイル損失$L_{style}$・コンテンツ損失$L_{content}$について
スタイル損失$L_{style}$・コンテンツ損失$L_{content}$は、生成されるQRコードがスタイル・コンテンツ内容を保持するように用いられます。具体的には、スタイル変換に関する既存の研究(1,2)に従い、以下の式で定義されます。
$L_{style}(I_s,Q)=\frac{1}{C_sH_sW_s}||G[f_s(I_s)]-G[f_s(Q)]||^2_2$
$L_{content}(I_c,Q)=\frac{1}{C_sH_sW_s}||f_c(I_c)]-f_c(Q)||^2_2$
ここで、$G$はグラム行列、$f_s(,f_c)$は事前学習済みのVGG-19の$s(,c)$番目の層から抽出された特徴マップを示します。
コード損失$L_{code}$について
コード損失$L_{code}$は、QRコードリーダーのサンプリングプロセスをシミュレートするSS Layer(Sampling-Simulation layer)、バーチャルQRコードリーダーを利用して、生成されるQRコードの内容を制御するために用いられます。
・Sampling-Simulation layerについて
QRコードのデコードに用いられているGoole ZXingでは、QRコードリーダーは各モジュール(QRコード内の白黒のマス)の中心のピクセルをサンプリングしてデコードする仕組みになっています。
実際にQRコードリーダーでQRコードを読み取る場合、各モジュールの中心を原点とする座標$(i,j)$に存在するピクセルがサンプリングされる確率$g_{M_k(i,j)}$は、以下の式に従うと考えられます。
$g_{M_k(i,j)}=\frac{1}{2\pi\sigma^2}e^{-\frac{i^2+j^2}{2\sigma^2}}$
Sampling-Simulation layerでは前述した式を元に、生成されたQRコードを実際のQRコードリーダーが読み取る際のサンプリングプロセスをシミュレートし、QRコードを読み取る際のロバスト性を高めます。
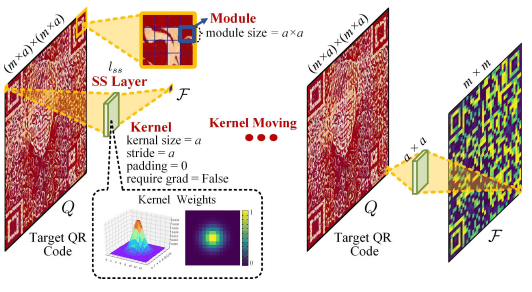
具体的には、QRコード内のモジュール$m☓m$(それぞれ$a☓a$ピクセル)について、カーネルサイズ$a$、ストライド$a$、パディング0の畳み込み演算を行い、$m☓m$の特徴マップ$F=l_ss(Q)$を出力します。
この特徴マップ$F=l_ss(Q)$と$g_{M_k(i,j)}$を元に、モジュール$M_k$に対応するビット$F_{M_k}$は以下の式で与えられます。
$F_{M_k}=\sum_{(i,j) \in M_k} g_{M_k(i,j)} \cdot Q_{M_k(i,j)}$
$F_{M_k}$は、実際にQRコードリーダーでQRコードを読み取った際、各モジュールが0または1のどちらとしてデコードされるかをシミュレートしているとみなされます。
・コード損失$L_{code}$
コード損失$L_{code}$は、QRコード$Q$の各モジュール$M_k \in Q$に対応するサブコード損失$L^{M_k}_{code}$の和として求められます。
$L_{code}=\sum_{M_k in Q}L^{M_k}_{code}$
ここで$L^{M_k}_{code}$は、以下の式で与えられます。
$L^{M_k}_{code}=K_{M_k} \cdot ||\textit{M}_{M_k}-F_{M_k}||$
ここで$\textit{M}$は、目標となるQRコードを示す$m×m$の行列であり、各モジュールが0か1のどちらであるべきかを示します。また、$K$は以下に説明する競争メカニズムで計算される活性化マップとなります。
競争メカニズム(Competition mechanism)
競争メカニズムは、活性化マップ$K$を制御することで、生成されるQRコードの視覚的クオリティ($L_style,L_content$)か、またはQRコードをQRコードリーダーで正確に読み取れるか($L_code$)のどちらを優先して最適化するかを決定します。
この競争メカニズムのパイプラインは以下の図の通りです。
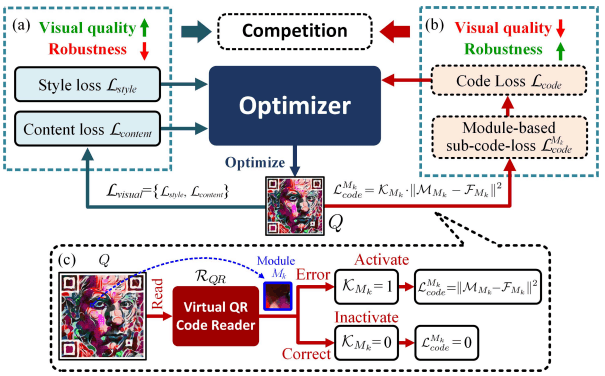
具体的には活性化マップ$K$は、仮想QRコードリーダー$R_{QR}$によってQRコード$Q$を読み取った際、モジュール$M_k$が正しければ0、間違っていれば1となります。
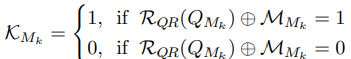
このような競争メカニズムを採用することで、間違ったモジュールについては$L_{code}$を、正しいモジュールについては$L_{style},L_{content}$を優先して最適化することで、画像のクオリティとQRコード読み取り時のロバスト性の両方を適切に保持します。
仮想QRコードリーダー$R_{QR}$について
通常のQRコードリーダーがQRコード$Q$を読み取る際、QRコード$Q$はグレースケールに変換され、各モジュールの値に応じて以下のように二値化が行われます。
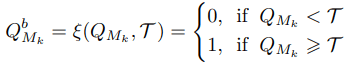
ここで、$T$はモジュールが黒か白かを判断する際の閾値にあたります。
一方仮想QRコードリーダーでQRコード$Q$を読み取る際、各モジュール$M_k$について以下のように二値化を行います。
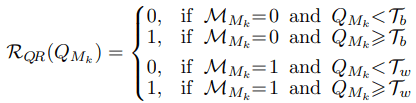
ここで、$T_b,T_w$はそれぞれ、モジュールが黒か白かを判断する際の閾値(モジュール$M_k$が黒($\textit{M}_{M_k}=0$の場合の閾値は$T_b$、逆の場合の閾値は$T_w$))にあたります。
つまり、各モジュールの理想的な値($\textit{M}_{M_k}$)に応じて異なる閾値を利用することで、実際のQRコード読み取り時よりも厳しく各モジュールの値の判別を行います。
このとき、QRコード読み取り時のロバスト性を示すパラメータとして、$\eta=\frac{|T-T_b|}{T}=\frac{|T_w-T|}{(255-T)}$を導入します。このパラメータ$\eta$を設定することで、画像のクオリティとQRコード読み取り時のロバスト性のトレードオフを行うことができます。
以上の内容に基づき、前掲したパイプラインに従って損失関数の最適化を行い、生成されるQRコードを反復的に更新します。
実験結果
実験設定
実験の際に用いるデータセットについて、コンテンツ画像データセットは512x512の画像100枚(肖像画、漫画、風景、動物、ロゴなど)、スタイル画像データセットは30枚の様々なスタイルを表す画像からなっています。
実験はNVIDIA Tesla V100 GPUで行われ、ハイパーパラメータは$\lambda_1=10^15、\lambda_2=10^7、\lambda_3=10^20、学習率0.001、ロバストパラメータ\eta=0.6$に設定されています。また、QRコード生成時の反復回数は$10^4$です。
生成されるQRコードの質について
・既存手法との比較
はじめに、既存のNST(Neural Style Transfer)技術またはQRコード生成手法との比較結果は以下の通りです。

Oursとその他を比較してみると、生成結果は既存のNSTの例と比べて質の低下は少なく、また既存のアート風QRコード生成手法と比べ、大量の点のようなノイズが生じることもありません。
・重みパラメータ$\lambda$について
重みパラメータのうち、コンテンツ損失にかかる$\lambda_2$を変化させた場合の結果は以下の通りです。

図の通り、重みパラメータを変化させることで、生成される画像を制御できることがわかります。
QRコード読み取りのロバスト性について
以下の実験では、生成されたQRコードが実際のアプリケーションで読み取ることができるかのロバスト性について検証を行います。
ロバスト性についての定性的な分析
以下の画像では、実際に生成されたQRコードの一部を拡大した場合について示されています。

どの生成画像についても、二値化された後の各モジュールの中心付近(Binary resultsの青丸・赤丸)を見てみると、各モジュールについて白・黒の領域がしっかり分かれており、サンプリング後の結果は理想的な結果と同じになっていることがわかります。
そのため、生成されたQRコードは、一般的なQRコードリーダーによってロバストに読み取ることが可能です。
・ロバスト性を示すパラメータ$\eta$について
ロバスト性を示すパラメータ$\eta$を変化させた場合の結果は以下の通りです。

図のうち、(a)は生成画像、(b)はその一部の拡大、(c)はエラーモジュール、(d)は各損失の大きさを示しています。
総じて、$\eta$を大きくするとコード損失が大きくなり、ロバスト性は向上しますが画質は低下します。逆に$\eta$を小さくするとコード損失が早期に0に収束し、画質は向上しますがロバスト性が低下することがわかります。
読み取りの成功確率について
生成された画像について、3cm×3cm、5cm×5cm、7cm×7cmの三つのサイズで画面に表示し、距離20cmでスキャンを行った場合の結果は以下の通りです。

この表では、各モバイル機器を用いて30個のQRコードについて50回スキャンを行った場合の成功回数の平均値を示しています(3秒以内にデコードに成功した場合を成功したとみなします)。
総じて、最低でも96%の成功率を示しており、提案手法は実際のアプリケーションでも十分に有効なロバスト性を有していることがわかります。(スキャン失敗時も、3秒以上の時間を要しましたが読み取りには成功したようです。)
・読み取り時の距離と角度の影響について
距離と角度を変更した場合の既存手法との比較・$\eta$変更時の結果は以下の図のようになります。

比較の結果、$\eta>0.6$の場合、提案手法のロバスト性は既存手法と同等か少し劣る程度であり、実際に利用するのに十分なロバスト性を備えているといえます。
まとめ
本記事では、Neural Style Transferを用いて、アート風のQRコードを生成する研究について紹介しました。提案手法(ArtCoder)は、実世界のアプリケーションでも読み取ることができる優れた品質とロバスト性を備えたQRコードを生成することが可能です。
現時点ではまだ生成速度に難があり(平均で384.2秒)、導入へのハードルはまだ高いと言えますが、今後の研究で生成速度が十分に改善されれば、アート風の目を引くQRコードに実社会で遭遇する日が来るかもしれません!






この記事に関するカテゴリー

