
Twitterのbotユーザーを検出するためのグラフベースの大規模データセット、TwiBot-22が登場!
3つの要点
✔️ 既存のデータセットよりもはるかに優れたアノテーション品質を持つグラフベースのTwitter bot detectionベンチマークであるTwiBot-22を作成
✔️ TwiBot-22を含む9つのデータセットに対して、35個の代表的なベースラインモデルを用いて再実装・再評価を実施
✔️ 既存の全てのデータセットとベースラインモデルによる比較実験の結果、TwiBot-22が包括的な評価ベンチマークとして機能することを実証した
TwiBot-22: Towards Graph-Based Twitter Bot Detection
written by Shangbin Feng, Zhaoxuan Tan, Herun Wan, Ningnan Wang, Zilong Chen, Binchi Zhang, Qinghua Zheng, Wenqian Zhang, Zhenyu Lei, Shujie Yang, Xinshun Feng, Qingyue Zhang, Hongrui Wang, Yuhan Liu, Yuyang Bai, Heng Wang, Zijian Cai, Yanbo Wang, Lijing Zheng, Zihan Ma, Jundong Li, Minnan Luo
(Submitted on 9 Jun 2022 (v1), last revised 12 Feb 2023 (this version, v6))
Comments: NeurIPS 2022, Datasets and Benchmarks Track
Subjects: Social and Information Networks (cs.SI); Artificial Intelligence (cs.AI)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
AI-SCHOLARイベント
AI技術は日進月歩で進み、皆さんもAI技術に関して多くのブームから衰退までを見ていると思います.そんな中,昨今のブームといえば,GPTからの大規模言語モデルだと思います.そこで,今回はAI-SCHOLARのメンバーを集めて,GPTの総論から話題にも上がるセキュリティ周りなどの技術者・研究者目線でのイベントを実施いたします.

はじめに
Twitter bot detectionはTwitter内のbotアカウント(自動化されたユーザー)を検出するタスクであり、フェイクニュースの発見やオンライン上のコミュニケーションの安全性を維持するために注目されています。
最新の検出手法は一般にTwitterネットワークのグラフ構造を利用しており、これにより従来の手法では検知できなかった訓練データにない新たなTwitter botに対しても十分なパフォーマンスを発揮できるようになりました。
しかし、既存のTwitter bot detectionに用いられるデータセットのうち、グラフベースのデータセットは非常に少なく、既存の数少ないデータセットもデータ規模の制限や不完全なグラフ構造、低いアノテーション品質といった問題点を抱えており、このように大規模なグラフベースが存在しないことがグラフベースのbot detectionモデルの開発や評価の妨げになっていました。
本稿では、このような問題を解決するため、既存のデータセットよりもはるかに優れたアノテーション品質を持ち、Twitterネットワーク上の様々なグラフ構造を提供する、包括的なグラフベースのTwitter bot detectionのベンチマークであるTwiBot-22を提案した論文について解説します。
Twitter bot detection
フェイクニュースや選挙への干渉、陰謀論の拡散などに見られるようにTwitter botが社会に与える悪影響は年々その規模を拡大させており、こうした社会的な問題からTwitter botの悪影響を防ぐためのモデルが開発されてきました。
既存のTwitter bot detectionモデルは一般に特徴ベースであり、メタデータ・ユーザータイムライン・フォロー関係などのユーザー情報から数値特徴を抽出する手法が提案されていました。
その後、研究者達はテキストベースのアプローチも提案しており、単語埋め込みやRNN、事前学習済みの言語モデルなどのテキスト分析手法により、ツイートの内容を分析して悪意があるかを特定する手法が開発されました。
しかし、最新のTwitter botは本物のユーザーから通常のツイートをコピーし、その間に悪意のあるコンテンツを挟み込むことが多いため、こうしたテキストベースの手法の効果が薄くなっているという課題が挙げられていました。
こうした背景とグラフニューラルネットワークの出現により、近年はグラフベースのTwitter bot detectionモデルの開発に焦点が当てられており、これらの手法はユーザーをノード、フォロー関係をエッジとして解釈する事で、GCNやR-GCN、RGTなどの手法をグラフベースのbot detectionに利用することを可能にしています。
これらのグラフベースの手法は既存の手法と比べて新規のTwitter botを検出できるなど、様々な課題に対処するのに優れていますが、既存のデータセットによって十分にサポートされておらず、具体的には下図のように、(a)限られたデータセット構造、(b)不完全なグラフ構造、(c)低いアノテーション品質の3つの問題に悩まされていました。
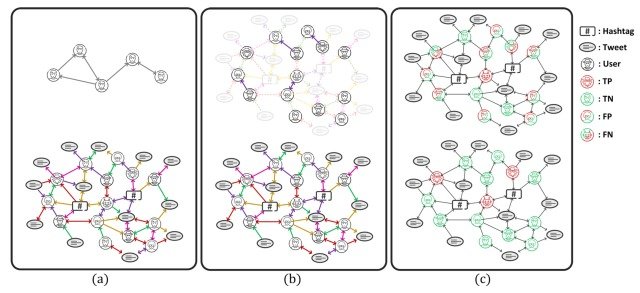
これらの問題を解決するために、本論文ではグラフベースの大規模データセットであるTwiBot-22を提案しました。
TwiBot-22
既存のデータセットに共通する問題として、現実のTwitterでは多様なユーザーとbotが同時に存在するのに対し、データセットには数種類のbotしか含まれていない点が挙げられていました。
こうした問題点を解決するために、TwiBot-22ではユーザー収集に幅優先探索(breadth-first search)を採用しており、これにより得られたユーザーを多様性を考慮したサンプリングで補強することで、様々なタイプのユーザーとbotを含むことを可能にしています。
これにより、TwiBot-22は92,932,326個のノード(ユーザー)と170,185,937個のエッジ(フォロー関係)を含む、既存の最大規模のデータセットの5倍の大きさのデータセットになっています。
その後、TwiBot-22からランダムに選んだ1000人のユーザーに対して、bot detectionの専門家にアノテーションを付与してもらい、それにより得られたデータを使用した自動アノテーションモデルにより、全てのデータに対してアノテーションを行いました。
TwiBot-22と既存のデータセットの比較を下図に示します。
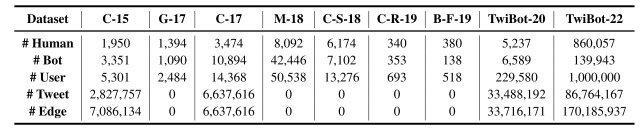
このように、TwiBot-22は既存のデータセットと比較して非常に大規模で多様なユーザーとbotから構成されていることが分かります。
Experiments
本論文では、TwiBot-22を含む上の表で比較されている9つのデータセットに対して、35個のベースライン手法を再実装し、下図に示すように比較実験を行いました。
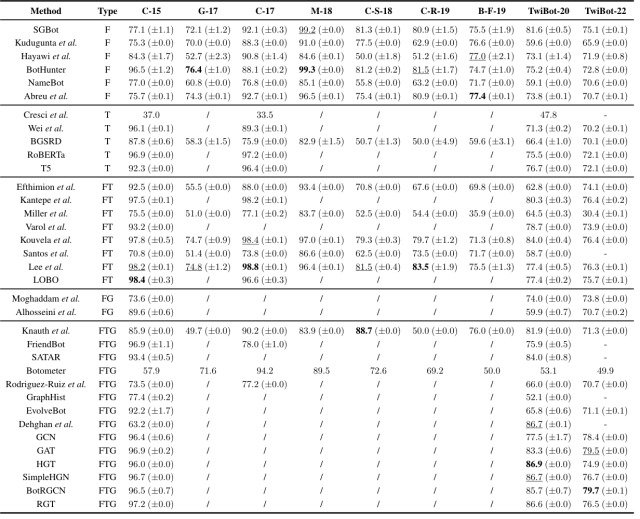
この比較実験の発見をまとめると以下のようになります。
- グラフベースのアプローチは一般的に特徴ベースやテキストベースの手法よりも効果的であり、実際にTwiBot-20とTwiBot-22に対する上位5つのモデルは全てのグラフベースの手法になっている
- 既存のデータセットのほとんどはグラフベースのアプローチをサポートするためのTwitterユーザーのグラフ構造を含んでいないが、TwiBot-22は全てのベースライン手法をサポートし、包括的な評価ベンチマークとして機能している
- TwiBot-22に対する精度は、全てのベースライン手法でTwiBot-20よりも平均して4.8%も低く、Twitter bot detectionは更なる研究が必要なタスクであることが示された
特に3つ目の発見に関してはTwitter botが常に技術的な改善によって検出を回避している事が原因であるため、筆者は、これらを検出するためにbot detectionモデルも常に改善し続ける必要があると指摘しています。
まとめ
いかがだったでしょうか。今回は、グラフベースのTwitter bot detectionのための新たな大規模データセットであるTwiBot-22を提案した論文について紹介しました。
TwiBot-22を含んだ包括的な比較実験により、本データセットは評価ベンチマークとして有効であることが実証されましたが、Twitter bot detectionタスクにおいて以下の問題点が未解決のままになっています。
- botクラスターをどのように特定するか?(新しいTwitter botはグループで行動し、協調し合いながらクラスターを形成することが確認されている)
- 検出精度を上げるためにマルチモーダルなユーザー特徴をどのように取り入れるか?
- モデルの汎化能力をどのように評価するか?
筆者は、TwiBot-22を基にこれらの問題点を解決することに注力すると述べており、今後の動向に注目が集まります。
今回紹介したデータセットやベースラインモデルのアーキテクチャの詳細は本論文に載っていますので、興味がある方は参照してみてください。




この記事に関するカテゴリー
