
ChatGPTは大学のコンピュータサイエンス学科の試験に合格できるのか!?
3つの要点
✔️ コンピュータサイエンス分野におけるChatGPTの性能を評価するために、実際の大学の試験をChatGPTに解答させるブラインドテストを実施
✔️ 学生平均が23.9点の中、ChatGPT-3.5で20.5点、ChatGPT-4で24点という高得点を記録
✔️ 試験の採点結果より、ChatGPT-3.5とChatGPT-4の性能の比較とその限界を分析
ChatGPT Participates in a Computer Science Exam
written by Sebastian Bordt, Ulrike von Luxburg
(Submitted on 22 Mar 2023)
Comments: Published on arxiv.
Subjects: Computation and Language(cs.CL); Computers and Society(cs.CY)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
現在、大規模言語モデルは様々な多数において目覚ましい成果をあげており、コーディングなどの特定のタスクや高度な数学の問題を解くなどの多様な問題解決能力を持っていることが報告されています。
しかし、こうした言語モデルの能力が飛躍的に向上している一方で、これらのモデルを評価するための新しいベンチマークの開発に焦点を当てた研究は行われてきておらず、加えて大学試験におけるChatGPTの性能に関する体系的な検証がほとんどありませんでした。
本稿では、大規模言語モデルを評価する新しいベンチマークの開発に焦点を当て、実際の大学の期末試験で出題された問題をChatGPTに解答させ、その結果の分析を行うことでコンピュータサイエンス分野における大規模言語モデルの性能の限界について検証した論文について解説します。
Experimental Design
本論文では、コンピュータサイエンス分野における大規模言語モデルの能力を測定するために、ドイツのテュービンゲン大学(University of Tubingen)のコンピュータサイエンス学部の学生が履修する授業である"Algorithms and Data Strucutures(アルゴリズムとデータ構造)"の期末試験の問題をChatGPTに解答させました。
この試験では、ソートアルゴリズム・動的プログラミング・グラフトラバーサル(グラフ内の各頂点にアクセスするプロセス)などのトピックが扱われ、選択問題・証明問題・グラフ描画問題・コーディングテストなどの様々な種類の問題が含まれています。
また、本試験は200人の学生が受験し、受験生は試験用紙に手書きで解答を書いたものを提出し、それをティーチングアシスタントが採点するという流れになっています。
これらの試験は1つのlatexファイルにまとめられており、試験中の図もテキストのみからなるlatexコードによって生成されているため、下図のように問題文をテキストとしてChatGPTに入力し、その出力コードを数式として解答用紙に手書きすることで回答を行い、選択問題に関してはモデルにどの選択肢が最も適切かを明示的に指示しました。

同じように、グラフを描画する問題ではChatGPTにlatexのグラフ作成用ライブラリであるtikz-graphを用いたlatexコマンドを出力させ、それを回答用紙に手書きすることで対応しました。

加えて、プロンプトの内容がChatGPTの出力に大きな影響を与えることが知られているため、下図のようにできるだけシンプルに問題を入力するようにし、出力のパフォーマンスを高める可能性のあるchain of thought promptingなどのプロンプトエンジニアリングは一切行いませんでした。

その後、ChatGPTの出力によって作成された解答用紙を200人の学生の解答用紙とともに提出し、通常の試験と同じようにティーチングアシスタントにより採点が行われました。
また、既存の大規模言語モデルに関する研究ではモデルの解答に対する採点においてバイアスが含まれている可能性があることが議論されていました。
このような問題に対処するために本研究はブラインドテストの形式で行われており、バイアスの含まれないより正確な採点結果を得るため、ティーチングアシスタントには本研究のことをあらかじめ伝えられていない状態で採点してもらいました。
Results
採点結果は下図のようになりました。
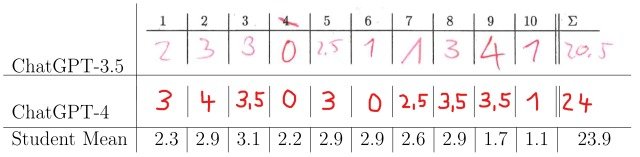
図は本試験に参加した200人の学生の平均点数とChatGPT-3.5およびChatGPT-4による解答の点数を表しています。
実験結果より、ChatGPTの両モデルにおいて合格点を超える点数を出しており(40点満点中20点以上で合格)、ChatGPT-4においては学生の平均点数を超える性能を出していることが確認できました。
解答結果の分析
次に、ChatGPT-3.5の解答結果に対する分析を行いました。
ChatGPT-3.5の解答で特に顕著だったのは下図に示すように証明問題に対する解答に対する正答率が非常に高かったことであり、実際にモデルがこうした証明方法を「理解して解いている」ような印象を与える解答を出力していたことでした。

図の動的計画法に関する問題は学生の中でも正答率が非常に悪く、こうした問題に対してChatGPTが良い性能を発揮することは大きな発見であると言えます。
一方で、下図のような標準的なアルゴリズムの動作を説明するようなグラフ描画問題に対しては、ChatGPT-3.5はほとんど解くことが出来ませんでした。
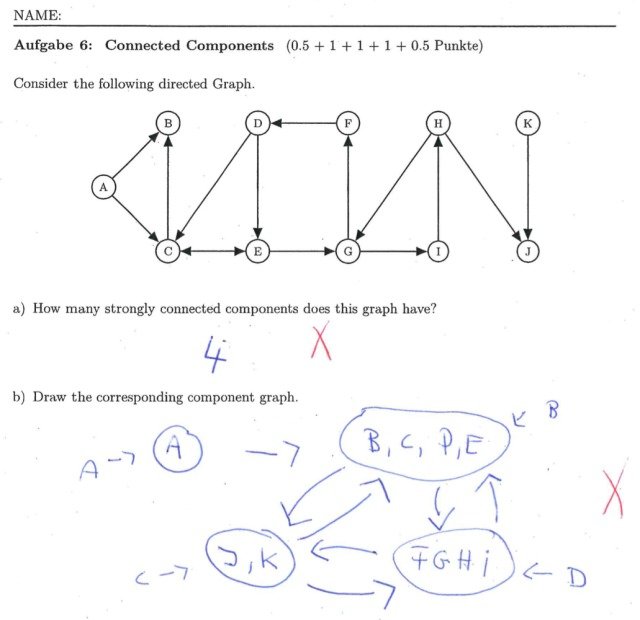
こうしたアルゴリズムに関する問題は、今回の試験の中では最も簡単な演習の1つであるにもかかわらず、ループの多いグラフを生成してしまったりと正答率が低くなってしまうことが確認されました。
一方で、ChatGPT-4においてはこのようなグラフ描画問題に対しても適切に解答することが出来ており、学生間の正答率が悪かった難易度の高い選択問題に対しても適切な正解を選ぶことが出来ていました。
このような結果から、ChatGPT-4がChatGPT-3.5に対して大幅な改善を遂げていることが確認できました。
まとめ
いかがだったでしょうか。今回は、大規模言語モデルを評価する新しいベンチマークの開発に焦点を当て、実際の大学の期末試験で出題された問題をChatGPTに解答させ、その結果の分析を行うことでコンピュータサイエンス分野における大規模言語モデルの性能の限界について検証した論文について解説しました。
本実験では、ChatGPT-3.5、ChatGPT-4ともに試験合格点を超える点数を出し、ChatGPT-4においては試験に参加した200人の学生の平均得点を超える結果となりました。
しかし、インターネット上には本試験で扱われたトピック(ソートアルゴリズム・動的プログラミング・グラフトラバーサル等)に関する情報および本試験の解答例を含む多くの教材が掲載されており、ChatGPTのトレーニングデータにはこうした練習問題や解答例が多分に含まれている可能性が考えられます。
そのため、本実験結果はChatGPTがコンピュータサイエンスを理解していると結論づけるのには不十分であると言えるため、こうした大規模言語モデルの性能を検証するためには、この先より多くの研究が必要になるでしょう。
今回の実験でChatGPTに用いられたプロンプトや試験の採点結果の詳細は本論文に載っていますので、興味がある方は参照してみてください。




この記事に関するカテゴリー






