
Research Paper On Speeding Up Deep Learning Inference - Technical Details Of The Speeding-up Method Of "SoftNeuro", Which Is Now Available For Free Trial - Explained.
3 main points
✔️ Proposes SoftNeuro, a fast inference framework for deep learning models
✔️ Automatically optimize inference speed on any platform including edge devices
✔️ Ease of deployment with C/Python API, CLI tools, and model import functions
SoftNeuro: Fast Deep Inference using Multi-platform Optimization
written by Masaki Hilaga, Yasuhiro Kuroda, Hitoshi Matsuo, Tatsuya Kawaguchi, Gabriel Ogawa, Hiroshi Miyake, Yusuke Kozawa
(Submitted on 12 Oct 2021)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
About Us
Morpho is a research and development-based company in imaging technology. Morpho will contribute to various fields of society by optimizing the practical application of "Imaging AI", which is a fusion of digital image processing technology cultivated up to now and cutting-edge artificial intelligence (AI) / deep learning.
first of all
Deep learning has been put to practical use in fields such as image processing and natural language processing. As the scope of its application expands, inferences are being made not only on servers as in the past but also in diverse environments such as smartphones and edge devices. Furthermore, even for a single device, the inference is performed in a heterogeneous environment using multiple hardware such as CPU, GPU, DSP, and TPU. In this research, we propose Dynamic Programming for Routine Selection (DPRS), a method to efficiently and automatically optimize inference in such diverse environments, and SoftNeuro, a framework to realize fast inference using DPRS.
Optimization of deep learning model inference
In a deep learning model, a graph structure is used to describe how operations are performed on input data. There are various patterns in how to specifically implement each layer, which is a node of the graph structure. For example, there are multiple choices for implementing convolutional layers at different levels, such as
- Algorithms (Direct, Winograd, Sparse, etc.)
- Parameters (tile size, parallelism, etc.)
- Devices (Intel/ARM CPU, GPU, DSP, TPU, etc.)
- Data types (float32, float16, quantized qint8, etc.)
- Data layout (channels-last, channels-first, etc.)
The combination of these choices gives a single implementation. We called such individual implementations "routines", and distinguished them from "layers", a concept representing operations. By doing so, optimization of deep learning model inference can be formulated as "the problem of minimizing the overall processing time by selecting appropriate routines for each layer". Alternatively, the set of routines selected for each layer is called a "routine path", which can be rephrased as "the problem of finding the fastest routine path". (There are also optimization methods such as Halide and TVM that decompose model inference into scheduling, but these are known to be very expensive to optimize due to the huge search space.)
Profiling and Tuning
The processing time of a routine varies depending on the execution environment and the characteristics of the input. SoftNeuro measures the processing time of the routines available for each layer in the execution environment (profiling) in advance and optimizes (tunes) the inference based on this information. At first glance, it may seem that selecting the fastest routine for each layer and constructing a routine path will optimize the overall performance, but this is not necessarily the case. For example, if a routine that uses a CPU is connected to a routine that uses a Cuda, the data will usually need to be transferred to the GPU before the second computation. If you do not account for this transfer time, you run the risk of choosing an inefficient routine path that may involve multiple transfers. SoftNeuro inserts an adapt routine into the routine path that handles the harmonization between such routines. The time required for the adapt routines is also measured during the profiling process, to ensure that the tuning takes the harmonization process into account.
Tuning algorithm: DPRS
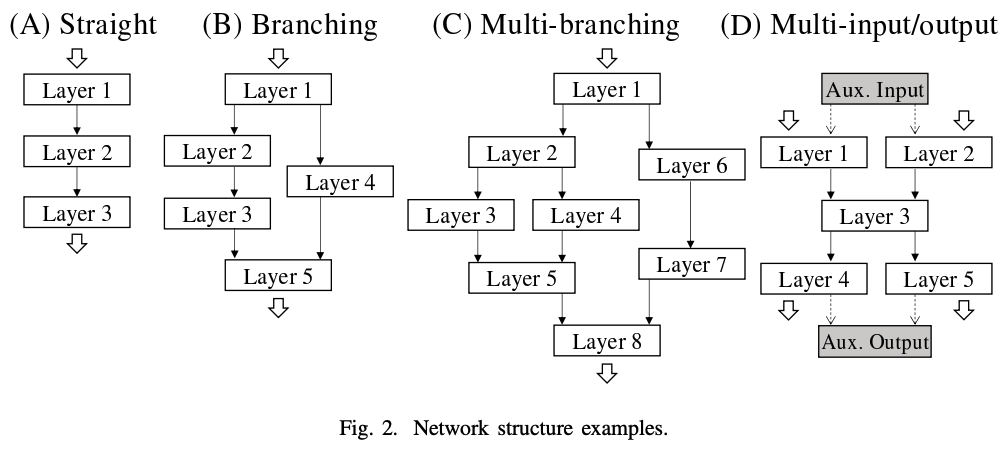
The process of searching for the fastest routine path based on the measurement information obtained from profiling is called tuning. The method of searching all possible routine paths is not feasible due to combinatorial explosion. Therefore, we proposed an efficient search method, DPRS, using dynamic programming. In the paper, the behavior of the algorithm is described step by step in terms of (a) serial networks, (b) branching networks, (c) nested branching networks, and (d) multiple-input and multiple-output networks.
In the case of a serial network, the fastest routine path to layer i can be obtained from three sources: (1) the fastest routine path to layer i-1, (2) the routine processing time at layer i, and (3) the processing time of the adapt routine. By using such an asymptotic formula, the overall optimal routine path is obtained. In the case of a branching network, the optimal overall routine path can be obtained by dividing the dynamic programming for each routine at the branch point. However, in the case of nested branches, it is not necessary to divide the dynamic programming for each routine at every branch point, and the variables are integrated at the confluence point to eliminate unnecessary calculations. Finally, a multiple-input/output network can be transformed into a single-input/output network by adding auxiliary input/output layers. In the paper, pseudocode generalizing these is given. The computational complexity of DPRS is O(number of layers × number of routines) for a serial network, which shows that it is feasible.
Results and business applications
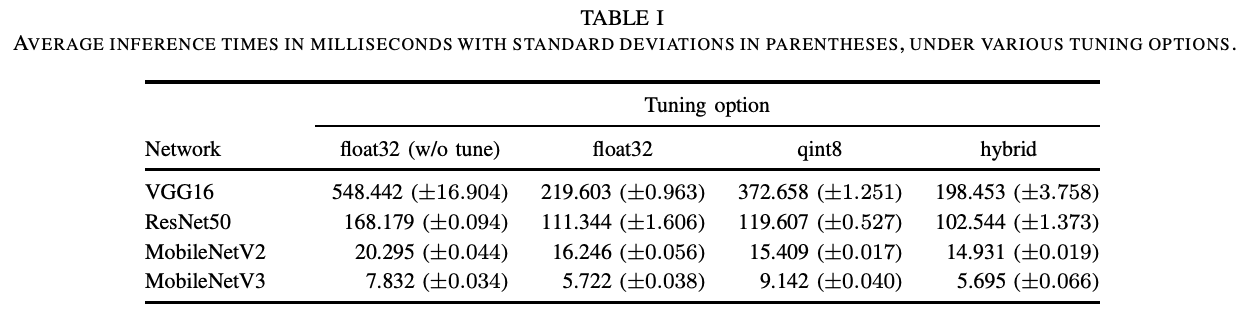
We have developed SoftNeuro, a multi-platform inference framework with auto-optimization by DPRS. In the following, we show experimental results on the inference speed of SoftNeuro. First, to examine the effect of auto-optimization, we summarized the processing times of VGG16, ResNet50, and MobileNetV2/V3 on a Snapdragon 835. For this experiment, we used the CPU, and compared inference with float32, inference with 8-bit quantization, and auto-optimization using both. In this case, the DPRS takes into account the adapt routines that perform the type conversion. As expected, the auto-optimization with both was found to be the fastest.
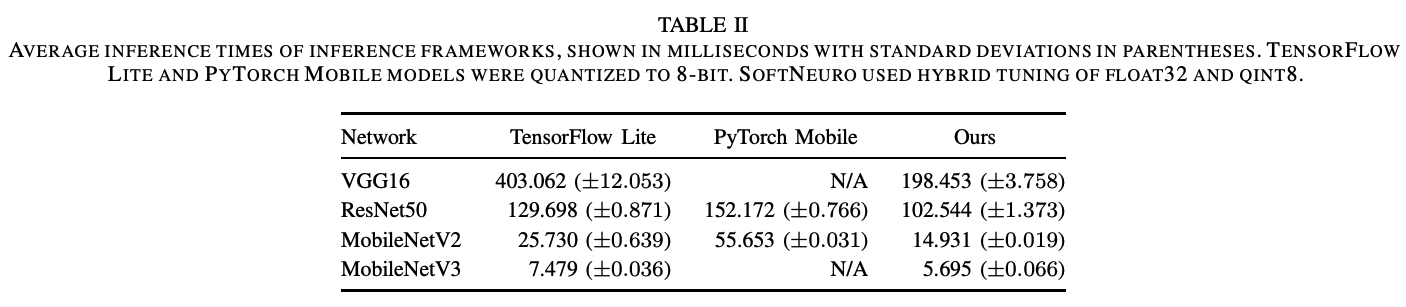
Here is a comparison of the time taken to infer the same four models with the mobile inference engines TensorFlow Lite and PyTorch Mobile. Compared to existing methods, VGG16 was approximately 2.0 times faster, and SoftNeuro showed the fastest inference speed for the other models.
SoftNeuro has routines optimized for Intel/ARM CPUs, GPUs, and DSPs at key layers, and can be used on a variety of platforms including edge devices as well as servers. The C/Python API and CLI tools make it easy to use in a wide range of development environments, and the ability to import models from learning frameworks PyTorch, TensorFlow, and Keras make it easy to implement. In terms of business applications, it has been used as the internal engine of a smartphone product that uses deep learning models and has recently been adopted as a standalone product.
consideration
In this study, the
- Separation of the concepts of layers and routines
- Two-stage optimization: profiling and tuning
- DPRS, an algorithm for optimizing routine paths on graph structures
- Development of SoftNeuro, a multi-platform inference framework with DPRS
In the future, we plan to extend DPRS to solve optimization problems with guaranteed accuracy and limited memory usage. In the future, we plan to extend DPRS to solve optimization problems with guaranteed accuracy and limited memory usage.
notice
We are now offering a free trial campaign of SoftNeuro non-commercial license for companies, academia, and the general public. For more information, please visit the dedicated website. Please look forward to the continued evolution of SoftNeuro!
Author information of this paper
Hiroshi Miyake, Researcher, CTO Office, Morpho Inc.



Categories related to this article