
YLFW, A New Large-scale Dataset Aimed At Facial Recognition Technology For Child Protection
3 main points
✔️ provided new datasets and benchmarks aimed at improving the accuracy of children's face recognition.
✔️ The new dataset and benchmark evaluated existing face recognition algorithms and revealed their limitations.
✔️ A new dataset and benchmark trained and evaluated a face recognition algorithm and improved its performance.
Young Labeled Faces in the Wild (YLFW): A Dataset for Children Faces Recognition
written by Iurii Medvedev, Farhad Shadmand, Nuno Gonçalves
(Submitted on 13 Jan 2023)
Subjects: Computer Vision and Pattern Recognition (cs.CV)
Comments: Published on arxiv.
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
summary
With the development of deep learning over the past decade, facial recognition has become highly accurate and is used in a variety of situations, including criminal investigations, immigration control, and opening bank accounts. However, many challenges still remain. Examples include twin identification and age/gender/race bias. Of particular importance is facial recognition of children.
There is an urgent need to find and protect missing or abducted children. For example, many countries report large numbers of missing children in their annual reports. The British police recorded 50,000 missing persons between 2020 and 2021. In the United States, approximately 340,000 children were reported missing in 2021. In the same year, the Canadian government reported approximately 28,000 children missing. Japan is no exception. According to the National Police Agency, approximately 1,000 children (under the age of 9) are reported missing each year, although this number is lower than in other countries. Furthermore, there are some special circumstances in Japan: removal of children without their consent due to marital discord has become a social problem, and there are cases where children are taken away from their parents and become missing persons. In the case of international marriages, there are cases where children are taken abroad and never found again. Although there are no exact statistics, it is believed that there are a significant number of missing persons.
Facial recognition technology is critical to finding and protecting these missing children. For example, in China, a family was able to find and reunite with their kidnapped son using facial recognition technology after more than 30 years of searching for him. Police found him by merging his childhood mugshot with that of his adult self and identifying it in a database ( Kidnapped child reunited with parents after 32 years, facial recognition technology helps, CNN).
In addition, according to UNICEF, approximately 4.4 million children experienced violence in 129 countries in 2021 (gender disaggregated data is available for 2.3 million of these, 53% of whom were female). This figure is an 80% increase over 2017. An even more pressing problem is the involvement of children in criminal activity, not only as victims but also as perpetrators. For example, there is evidence all over the world that children are involved in drugs and drug trafficking. Facial recognition technology is also important here. For example, the facial recognition system deployed by the Buenos Aires city government uses the identity information of registered children. The city operates a system that uses facial recognition technology to monitor the city and track specific individuals.
Thus, face recognition for children is considered an important technology worldwide to protect children's human and rights. However, the facial data sets that have been used to construct facial recognition models are biased toward adults, and accuracy tends to be low for facial recognition of children, whose faces are young and whose faces change significantly over time. Although there have been no datasets available, many of them are private and small in scale, and there are no standardized datasets yet. The table below lists the child face datasets reported to date.
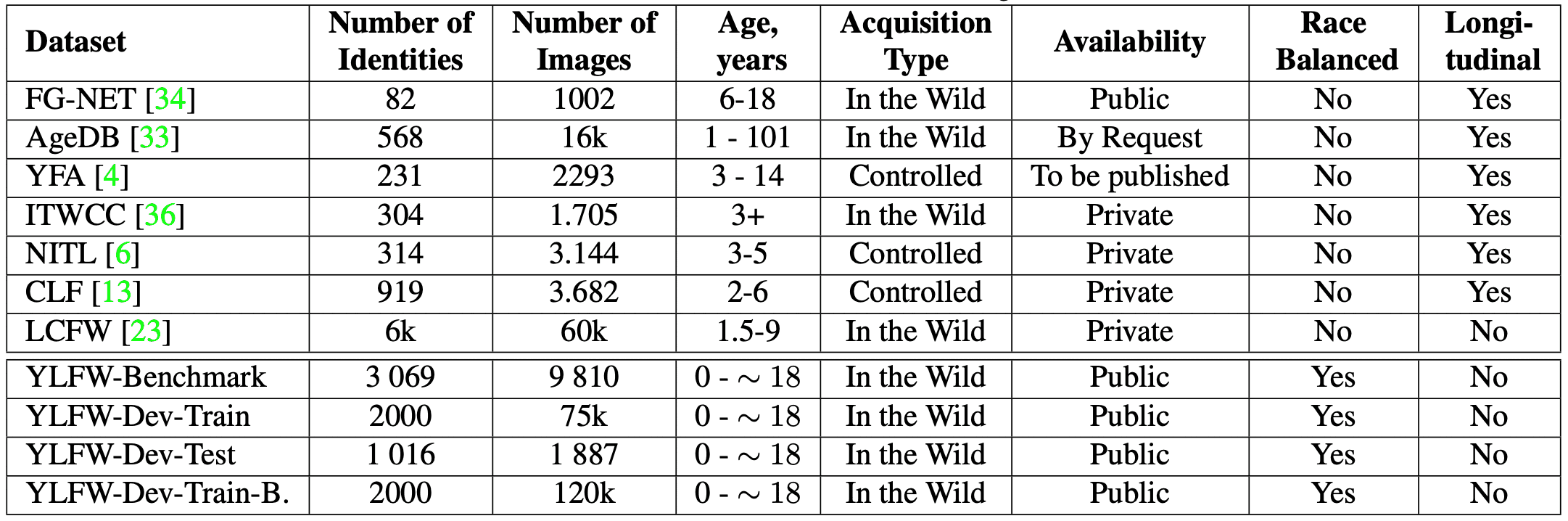
Therefore, the paper presented here provides the "YLFW" standard dataset for child face recognition. YLFW is the first standard dataset for child face recognition and the largest dataset for developing child face recognition models. This dataset is created in the same way as other well-known face datasets such as LFW, CALFW, CPLFW, XQLFW, and AgeDB. We also provide training and testing datasets for tuning face recognition models for children's face images.
Overview of YLFW Dataset
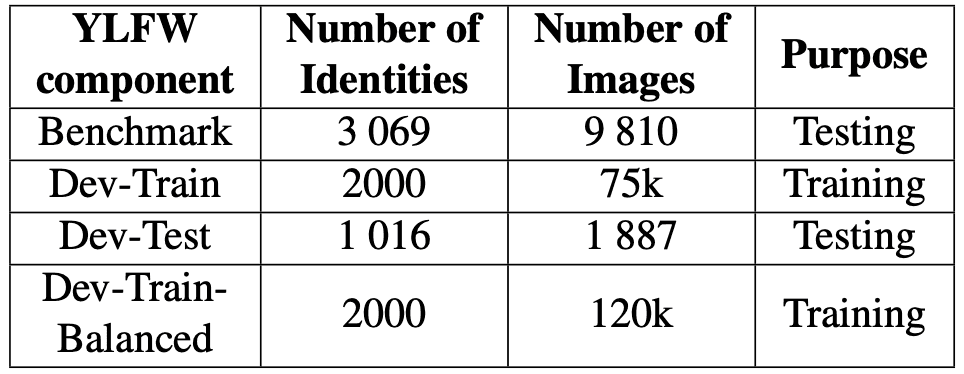
YLFW consists of two sets, "YLFW-Benchmark" and "YLFW-Dev". First, "YLFW-Benchmark" is a dataset for evaluating the performance of the child face recognition algorithm, consisting of about 10,000 images and about 3,000 IDs (individual face entities). The dataset employs a validation protocol in which one query image is compared to one gallery image. The protocol provides approximately 3,000 matching pairs (different images of the same person) and approximately 3,000 non-matching pairs (images of different persons).
Next, let's talk about "YLFW-Dev". This is a dataset for building face recognition models adapted to children's faces and is divided into two sets, YLFW-Dev-Train and YLFW-Dev-Test. YLFW-Dev-Train is a training dataset with about 75,000 images and about 2,000 IDs. dataset with about 75,000 images and about 2,000 IDs. YLFW-Dev-Test, on the other hand, is a test dataset with approximately 1,900 images and 1,000 IDs. That is, IDs used in the training dataset are not included in the testing dataset. YLFW-Dev-Test is also used to perform benchmark testing (performance evaluation) when YLFW-Dev-Train is used as the training dataset.
In addition, a dataset called YLFW-Dev-Train-Balanced is also available to balance each race in the dataset. This is created by randomly adding images of a small number of races to the original YLFW-Dev-Train data. The images to be added are augmented by horizontal flipping (flipping the image left to right), adjusting brightness and contrast, rotating the image, and injecting noise. The table below outlines the dataset created.
Performance evaluation by YLFW-Benchmark
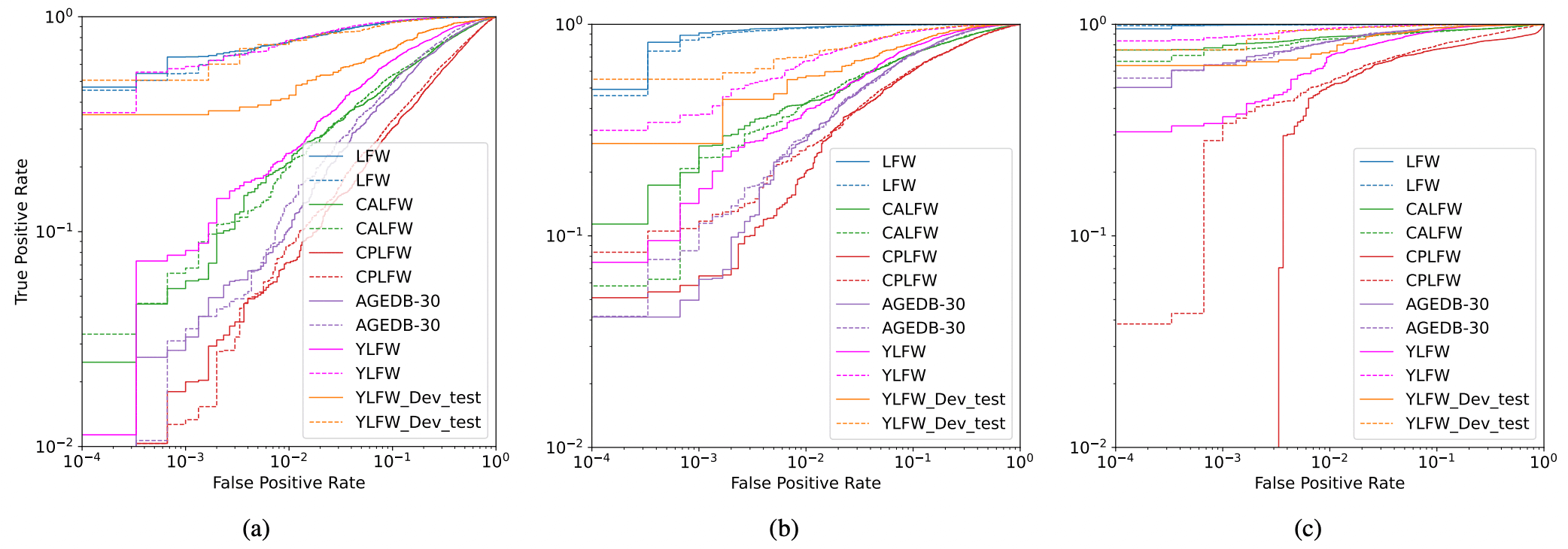
YLFW-Benchmark is used to evaluate how well state-of-the-art (state-of-the-art, SOTA) face recognition models perform in face recognition of children. We use the ResNet-50 face recognition model trained on the MS1MV2 dataset as the state-of-the-art (state-of-the-art, SOTA) face recognition model; we experiment with applying ArcFace, MagFace, and AdaFace. The results are shown in the figure below and in the table below. Note that race is abbreviated as follows: Afr. - African, As. - Asian, Cau. - Caucasian, Ind. - Indian.
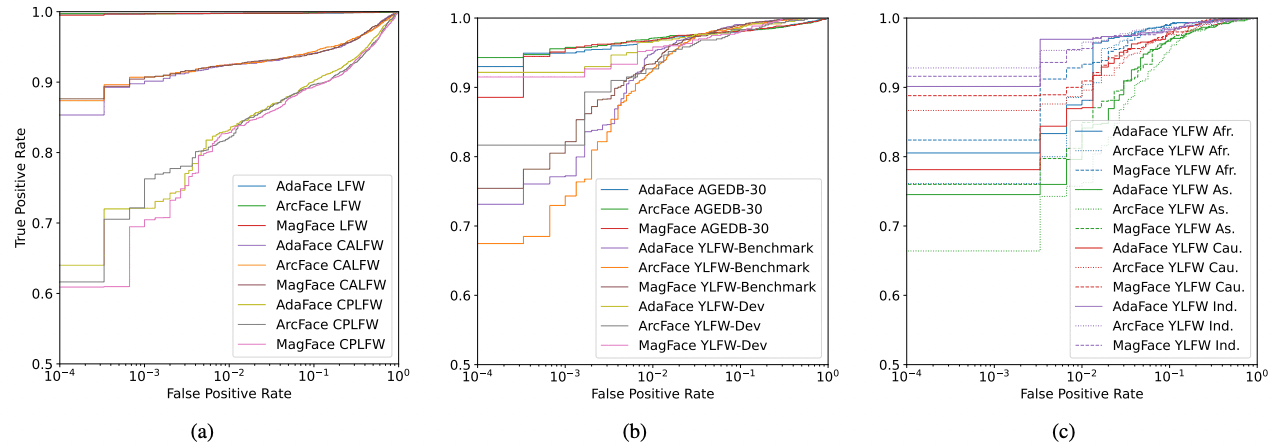
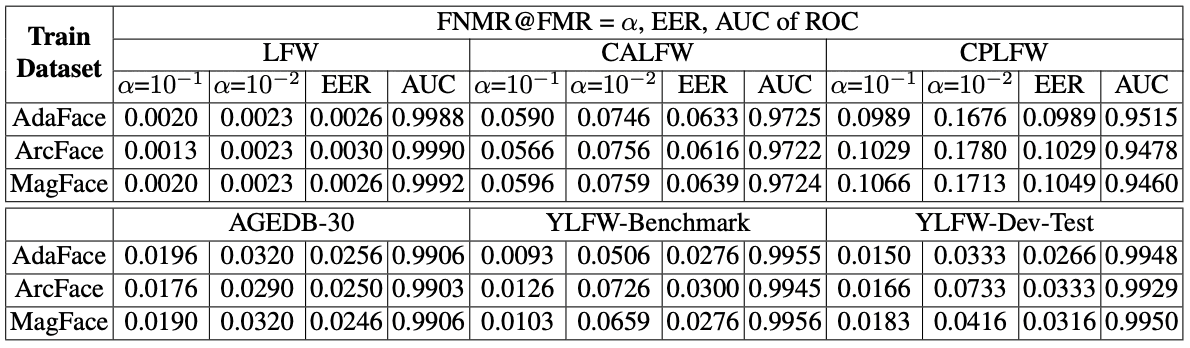
The results of YLFW-Benchmark show that it is a benchmark of the same difficulty level as CALFW and CPLFW. The YLFW-Dev-Test results also show that when the FMR is high, i.e., when the probability of false face recognition is high, the difficulty level is similar to YLFW-Benchmark, but when the FMR is low, this difficulty level is slightly lower.
Performance evaluation using YLFW-Dev
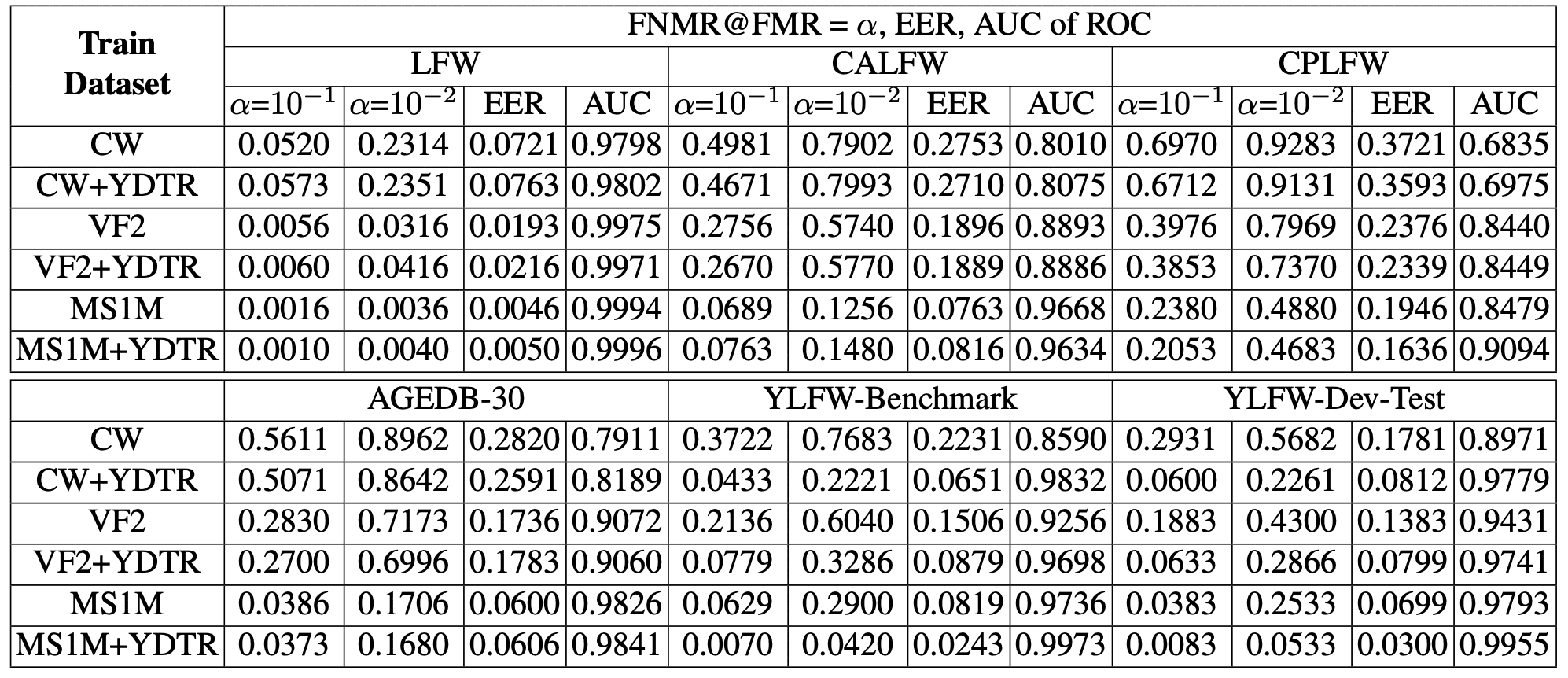
Here we describe an experiment using YLFW-Dev, which is intended to assist in the development of face recognition models for children by providing both training and test data. ResNet-50 is also used in this experiment, and ArcFace is used for the loss function. The results in the figure below and the table below show that using YLFW-Dev-Train-Balanced data for the training data clearly improves performance. Note that the table below uses the following abbreviations: CW - CASIA-Webface, VF2 - VGGFace2, MS1M - MS1MV2, YDTR- YLFW-Dev-Train-Balanced.
summary
In this paper, we propose a new face dataset, YLFW, dedicated to face recognition in children. The dataset consists of two parts, YLFW-Benchmark and YLFW-Dev, each addressing a different aspect of young adult face recognition research. This dataset is the first standardized benchmark specifically for children's face recognition and is also the largest dataset. Furthermore, experiments with YLFW have shown that current face recognition does not perform well enough for children's faces. We also showed that this dataset can be used to improve the accuracy of face recognition for young people.
It is said that many parents and children are currently separated in the Ukrainian war as well. It is hoped that this research will lead to more research on facial recognition for the protection of children, and that facial recognition/authentication will help solve incidents and crimes involving children as soon as possible.



Categories related to this article






