Face Recognition Models Vs. Humans! Is The Bias Of Face Recognition Models Greater Than That Of Humans?
3 main points
✔️ First paper to compare biases between humans and face recognition models
✔️ Face recognition models perform better than humans and have similar biases
✔️ Both facial recognition models and humans perform better on males and Caucasians, and humans perform better on people with similar attributes to themselves
Comparing Human and Machine Bias in Face Recognition
written by Samuel Dooley, Ryan Downing, George Wei, Nathan Shankar, Bradon Thymes, Gudrun Thorkelsdottir, Tiye Kurtz-Miott, Rachel Mattson, Olufemi Obiwumi, Valeriia Cherepanova, Micah Goldblum, John P Dickerson, Tom Goldstein
(Submitted on 15 Oct 2021 (v1), last revised 25 Oct 2021 (this version, v2))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computers and Society (cs.CY); Machine Learning (cs.LG)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
outline
Face recognition systems is a research area that has been the focus of attention for decades. And In the last few years. companies and governments have been actively introducing face recognition systems, and We are seeing more and more opportunities to see face recognition systems. For example, some systems can be introduced casually, such as image search systems that can search for images of specific people, controversial systems that can detect wanted criminals the controversial detection of wanted criminals in surveillance cameras, and so on. However, privacy and discriminatory treatment have been a concern and criticism around the world since it was introduced.
For example, In 2020, the death of George Floyd, an African-American man, in Minneapolis, Minnesota, by a police officer who held him down by the neck, sparked racial discrimination and criticism of the facial recognition systems used by police. Around the world, Facial recognition technology has been criticized for promoting racism and sexism, and major high-tech companies have been forced to shut down their systems. one after another announced that they would stop providing the technology or halt its development. Even today, the use of facial recognition systems in public and socially important applications, for example, in judicial and police agencies, is controversial.
Research on the bias of face recognition systems has been conducted in the past. However, there have been no reports from the perspective of whether the bias of face recognition systems is greater than that of humans, and the question has remained unanswered. It is well known that facial recognition systems outperform humans in terms of overall performance and processing speed, but the biases are still unknown.
If the bias of the face recognition system is much larger than that of humans, we need to be cautious about the introduction of the face recognition system. For example. If they are used in surveillance cameras, for example, the target person would be at a great disadvantage. Misidentification of a particular race or gender could lead to false arrests. However, if the bias is comparable to that of humans, it is not an ideal system, but it is a technology that can recognize faces faster and with higher accuracy than humans, so there may well be applications where it can be introduced. Also, by understanding the characteristics of bias in face recognition systems, we can consider how to handle them with care and how to interact with them successfully.
In this paper, we evaluate the biases between humans and face recognition systems that have not been clarified before. In this paper, to fairly evaluate the bias, we use the "InterRace" It is important to create a new dataset, and then create a human and face recognition model to evaluate the accuracy (Accuracy) and bias of two tasks, Identification (1:N) and Verification (1:1).
The "InterRace" dataset.
In this paper, we create a new dataset, InterRace, to accurately assess bias. The existing dataset is large and easy to use, but as shown in the figure below, it contained a lot of data that hindered the model training for face recognition because different people were labeled as the same person, it contained blurred images, and there were cases where multiple people appeared in one image. In addition, similar images were included in both Gallery and Test, which contained data that could lead to unjustifiably high accuracy during accuracy evaluation. Furthermore, the composition of labels for demographics in the dataset was highly skewed, making it difficult to accurately validate bias. In this paper, we created a new dataset, InterRace, by manually correcting and sorting the data using the large datasets LFW and CelebA, which are commonly used for training and evaluating face recognition models.

Each image is labeled with the following four things: date of birth, country of birth, gender, and skin color. country of birth, gender, and skin color. The date of birth, country of origin, and gender are labeled based on public comments from Wikipedia, magazines, and interviews, and are double-checked by multiple people. Skin tone is classified into six categories based on skin lightness using a standard called the Fitzpatrick Scale.
The final dataset consists of a total of 7,447 images and contains 2,545 IDs. It is composed of Light skin tone ( Fitzpatrick: I-III), with 1,744 individuals with light skin tones (Fitzpatrick: I-III) and dark skin tone ( Fitzpatrick: IV-VI) with darker skin tones ( IV-VI) were 1,744 801, and comprised 1,660 males and 885 females. For the performance evaluation, subgroups were created from this dataset with a balance of attributes.
experiment
To compare and evaluate face recognition and human recognition performance and bias, we experiment with identification(1:N) and verification (1:1).In Verification, for each Source image, one image of the same person and eight images of people with the same gender and skin tone are displayed, for a total of nine images. In Verification (1:1 ), one image of the same person and one image of the same person with the same gender and skin color are displayed for one Source image, and whether the two displayed images are of the same person or not is evaluated. The two images are evaluated to see if they are the same person or not.

In the creation of questions, for each Identification and verification task, 78 people are selected for 12 different genders (2 ways) and skin colors (6 ways ), and 936 questions are prepared for each task. We also removed images from this list that could identify the person by the context around the face (background, clothing, etc.), and finallyprepared901 questions for Identificationand905 questions for Verification.
The survey on humans is crowdsourced, and each user is asked to answer36Identificatio questions and72 Verification questions in about 10 minutes. The questions are randomly selected from the the901Ident ification and905Ver ification questions prepared in advance, and three Identification questions and six Verification questions are asked for each attribute information (12 ways) to avoid bias in the attribute information. In each task, the first five questions are
In each task, the questions to check attention are asked immediately after the first five questions and immediately before the last five questions. ), and a question with an identical image pair (the same image ). Respondents who failed to answer this question correctly were excluded from the analysis as they were not taking the question seriously. Respondents who answered the attention-checking questions correctly, but with an extremely short survey time of fewer than four minutes, were also excluded from the analysis, as they were not considered to be taking the questions seriously. In addition, the first three questions of each task answered by each respondent were also excluded from the analysis, as it may take time for respondents to adjust to the question format. Some 545respondents were 18 years of age or older and residents of the United States.
The Academic and Commercial (API) models were used in the survey for the face recognition model. Unlike humans, the face recognition models do not suffer from fatigue-induced concentration problems and therefore answered all901Identificationquestions and all 905Verificationquestions.
The Academic model used ResNet-18, ResNet-50, the MobileFaceNet, NN (CosFace), and NN (ArcFace) trained on CelebA (9,277 images).Note that there is no overlap with the InterRace IDs used in the validation. The Commercial model (API) uses AWS Rekognition, Microsoft Azure, and Megvii Face++, but AWS Rekognition and Microsoft Azure evaluate Identification (1:N) and Verification (1:1), while Megvii Face++ only evaluates Verification (1:1).
experimental results
The results of the assessment are shown in the following two tables: first, The human performance evaluation. logistic regression results. It shows that there is a bias against the gender and skin type of the subjects (logistic regression), even when the respondent's demographic information is restricted. The second is the face recognition model. for the performance evaluation of the face recognition model. logistic regression results for the performance evaluation of the face recognition model. when the respondent's attribute information is not restricted. bias for the gender and skin type of the subjects (logistic regression). The subject's demographic information for the question is represented by q (qgender and qskin type) and respondent demographic information is represented by r (rgender and rskin type).
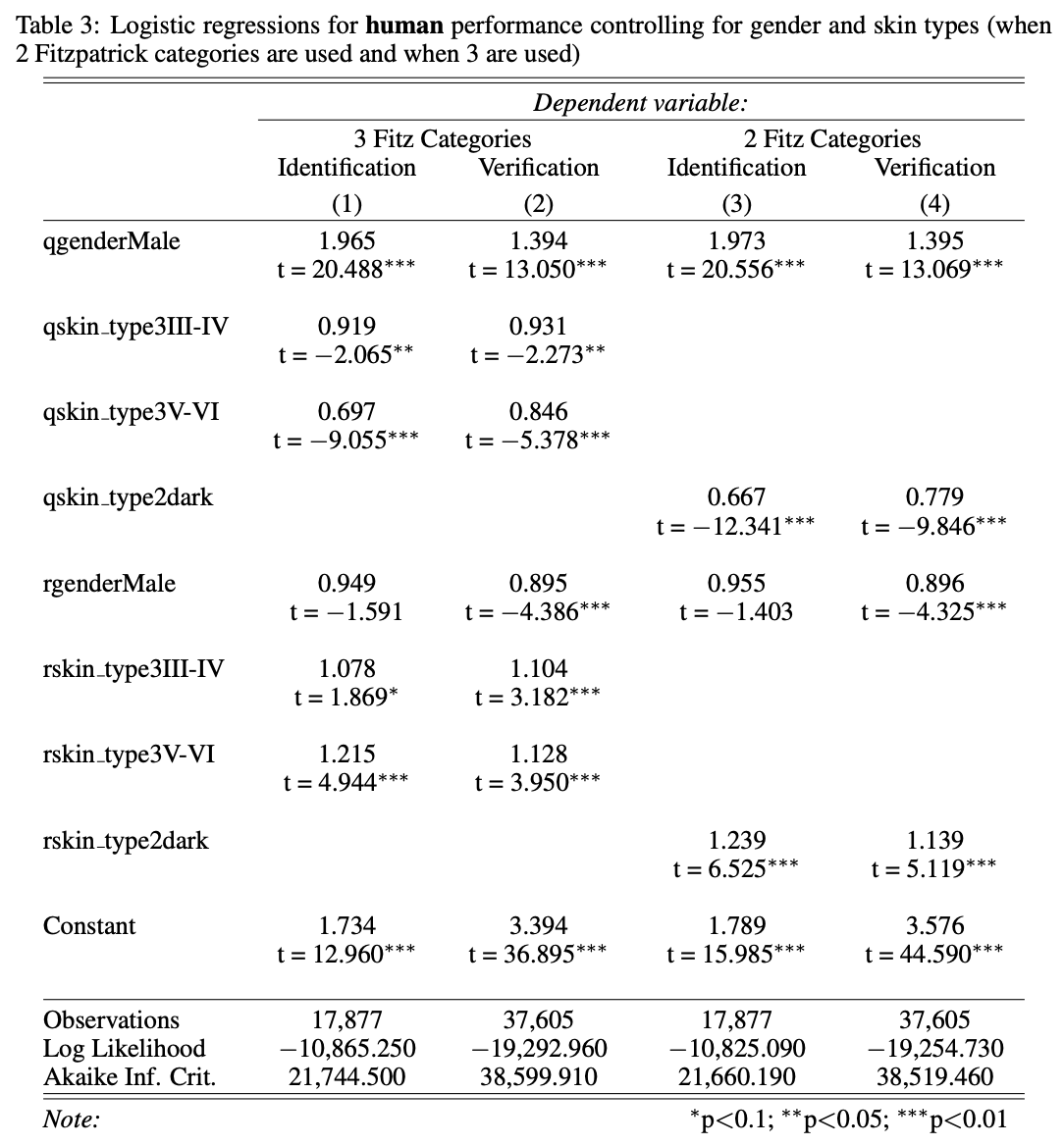

From the above, the results of the evaluation show that
- Male users get better results for both human and face recognition models.
- For both human and facial recognition models, the results are better for Caucasians.
- Humans perform better against people with demographic attributes that are similar to their own.
- The commercial model (API) has very high face recognition accuracy and no significant performance differences by race or gender.
Overall, face recognition models have higher accuracy (Accuracy) than humans, and t-test and logistic regression results show that they have the same level of statistical bias as humans.
However, it is important to note that the respondents in this paper are only crowdsourced people. Since they are not experts in face recognition, we cannot necessarily conclude that their face recognition models are better than or comparable to humans. It is only important to note that these are results from non-experts/generic people in the US. Also, the face recognition model is limited to the model chosen by the authors of this paper, so we do not know whether other face recognition models will yield similar results. These points should be noted.
Nevertheless, the face recognition models perform better and have the same level of bias compared to non-experts/non-humans, so there is a lot of merit in their implementation. Although further research is needed on their use by the judiciary and police. The results are useful enough to understand the advantages and disadvantages of face recognition models.



Categories related to this article






