
GANDiffFace, A New Framework That Provides Synthetic Datasets For More Realistic And Unbiased Face Recognition
3 main points
✔️ Propose a method to combine GAN and Diffusion Model to construct a realistic synthetic dataset with enhanced intra-class variability.
✔️ Constructed datasets based on the same person synthesized using two different methods (using GAN only and combining GAN and Diffusion). Tested its usefulness by comparing it to a real-world dataset.
✔️ Published dataset constructed with GANDiffFace.
GANDiffFace: Controllable Generation of Synthetic Datasets for Face Recognition with Realistic Variations
written by Pietro Melzi, Christian Rathgeb, Ruben Tolosana, Ruben Vera-Rodriguez, Dominik Lawatsch, Florian Domin, Maxim Schaubert
(Submitted on 31 May 2023)
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
First of all
In recent years, in the field of face recognition systems, large data sets have been released one after another, dramatically improving performance. However, privacy concerns have sometimes prevented the use of publicly available data sets. A solution to this problem is a dataset of synthetic facial images. Since the face image is generated from a non-existent person, there is no privacy issue. In addition, since the face images are automatically generated by computer, it is possible to acquire face images on a large scale, which is difficult to obtain for real people. However, these methods also have drawbacks, such as not being as realistic as real people and having a skewed racial distribution.
The paper presented here proposes a framework that combines GAN and Diffusion Model to create a new synthetic dataset called "GANDiffFace" to solve the problem of existing synthetic datasets. -like face images, and furthermore to include data from various ethnicities equally. It then uses a Diffusion Model to generate a variety of images of the same person with different accessories, poses, expressions, and backgrounds based on the GAN-generated images.
In addition, we compare the datasets constructed with GANDiffFace to datasets constructed with real face images (e.g., VGG2 and IJB-C) to verify their usefulness.
The figure below shows an overview of GANDiffFace, which combines GAN and Diffusion Model: for each person synthesized by the GAN-based module, a personalized Diffusion Model-based module generates a variety of images with realistic intra-class A variety of images with variability are generated, which are then filtered and added as the final dataset.
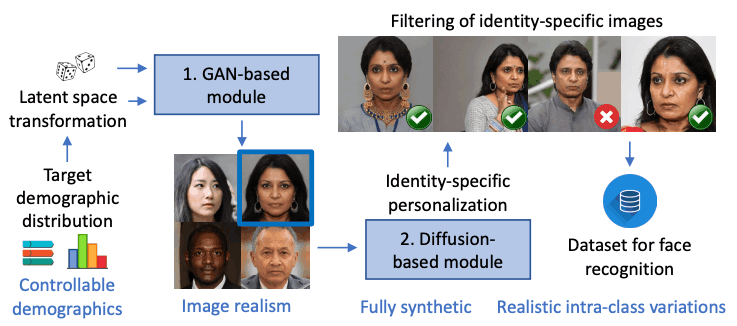
What is GANDiffFace?
The GANDiffFace framework is shown in the figure below.GANDiffFace consists of two modules: The first is a GAN-based model. The second is a Diffusion Model based model. The second is a Diffusion Model-based model, where DreamBooth is used to generate realistic intra-class variations (e.g., different facial expressions and poses of the same person).
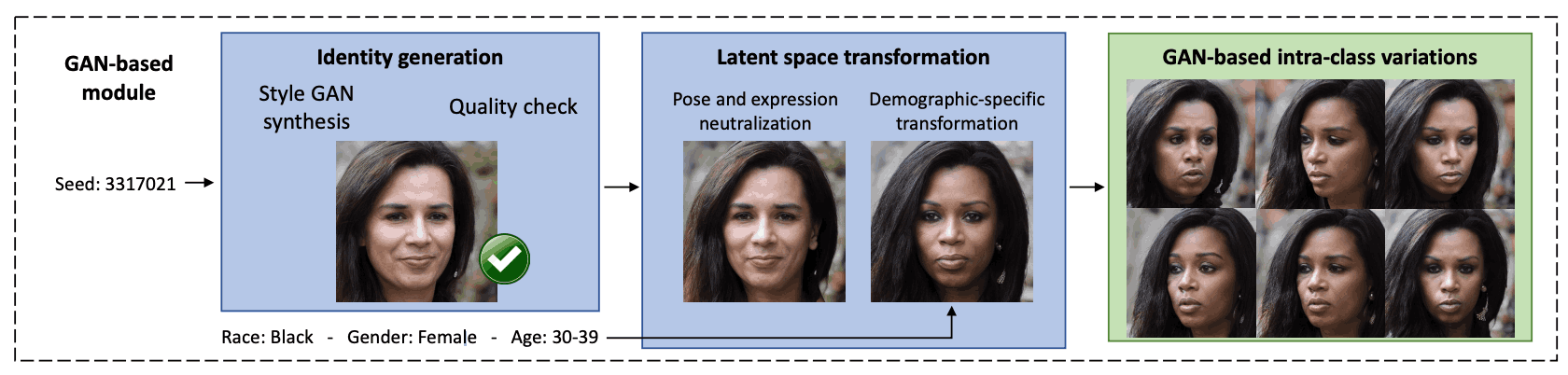
The first step in the GAN-based module is to generate human face images. Here, StyleGAN3 is used to generate 256,000 composite images. These images are labeled with the FairFace classifier with respect to demographic attributes such as race, gender, and age. However, as shown in the figure below, the random set of images generated by StyleGAN3 is biased, so images of poor quality and images of young subjects are excluded. A system called MagFace is used to assess quality, and the lowest quality 10% of images are removed.
Next, a support vector machine (SVM) is trained to find normal vectors to edit different attributes to interpret the potential facial expressions learned by StyleGAN. This allows the user to modify facial expressions such as smile or surprise, as well as attributes such as race and gender. The synthetic dataset is labeled based on these attributes and then the SVM is used to define the direction of the latent vectors to change the attributes.
Finally, the latent vector is transformed to change the attributes of the face image. This is done by making changes to the latent vectors that represent the image, for example, adding specific facial expressions or lighting conditions, or changing attributes such as gender or age. To make the change, we simply apply the transformation to the latent vector.
Combining these operations produces many different person images that are ultimately representative of the target demographic group, while at the same time yielding intra-class variation in face images (different image variations of the same person).
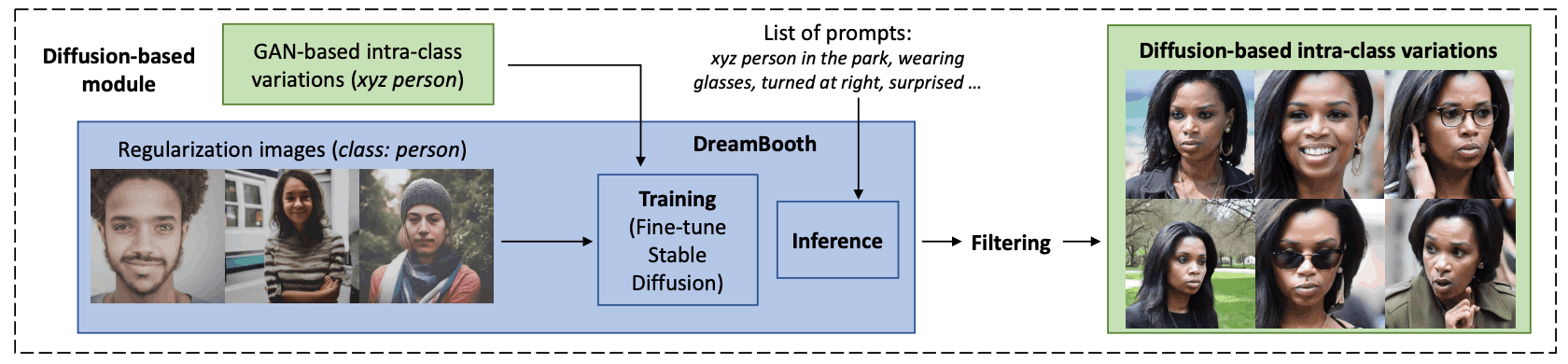
The text is then processed in a Diffusion Model-based module that generates images based on the text. This module is divided into three steps
The first is learning. Here, we use images generated by a GAN-based module to fine-tune Stable Diffusion, which generates images from text. Next, a technique called DreamBooth is applied to tie a unique identifier (Token xyz) to a specific synthesized person. When using this model, text prompts such as "xyz person" are used to identify the synthesized person. Ensure that the model retains the characteristics associated with that particular person while leveraging information learned in the past.
The second is inference (image generation): after being fine-tuned in DreamBooth, the Stable Diffusion model generates images of specific composite figures in different situations based on indicated prompts. Prompts such as "xyz person in scarf" or "close-up of xyz person on beach" are used to generate composite images with realistic within-class variation. Negative prompts can also be specified to avoid generating unwanted images.
The third is filtering (image selection). Here, face detection is performed and images with no face detected are excluded. To retain information about a particular person, features are extracted from the combined image and checked to see if they are similar to images previously used for fine tuning. Images that are not sufficiently similar are excluded. To preserve gender, the remaining images are labeled based on gender, and those that differ in gender from the images generated by the GAN are excluded.
Through these processes, we are able to create composite images that recreate the person in a variety of contexts while preserving specific person information.
Analysis of synthetic datasets with GANDiffFace
Here we analyze the distribution of facial similarity scores from four different versions of a synthetic dataset built with GANDiffFace to see how it compares to existing datasets used in face recognition. We are trying to determine how similar this dataset is to actual datasets and other synthetic image datasets to see if this dataset can actually be used for face recognition.
The actual datasets used are VGGFace2 and IJB-C, both commonly used for face recognition; VGGFace2 contains images of about 9,000 people collected from the web, with a variety of labels including pose, age, lighting, ethnicity, and occupation; IJB-C contains about 3,000 people, with a focus on images with partially hidden faces and a diversity of ethnicities and occupations. To ensure a fair comparison between the actual images and the composite dataset, actual images below a certain quality were excluded. This quality criterion is the same as that used in GANDiffFace to eliminate the lowest quality images when generating specific persons. Note that the focus is on creating a dataset consisting of high quality images, and the evaluation of datasets consisting of low quality images is outside the scope of this study. SFace and DigiFace-1M were used as other synthetic image datasets.
First, for the actual and synthetic datasets, we randomly select 10 images and compute similarity using ArcFace for image pairs of the same person (matching) and image pairs of different persons (non-matching). Next, using the score distribution of the actual dataset as a reference, we measure the differences between the score distributions of the actual and synthetic datasets with Kullback-Leibler (KL) divergence.
The similarity score distribution is shown in the figure below.
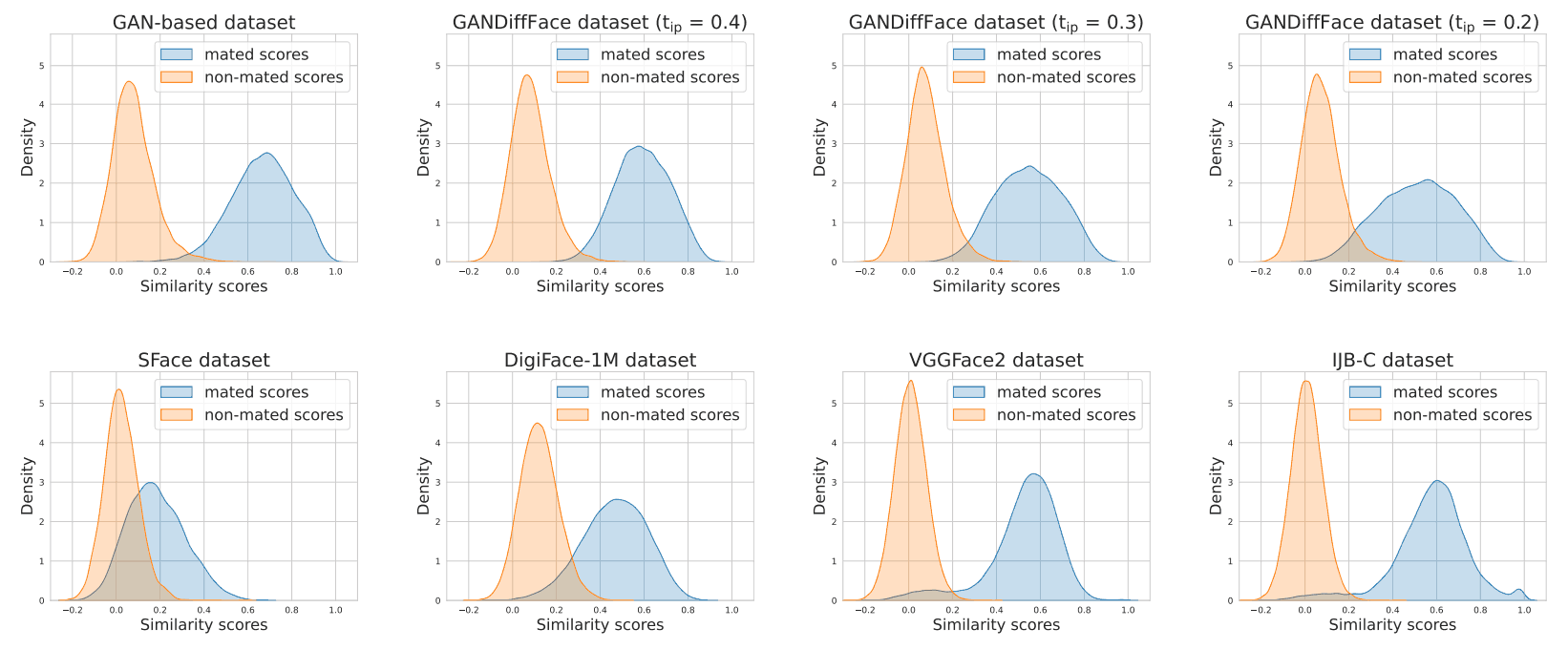
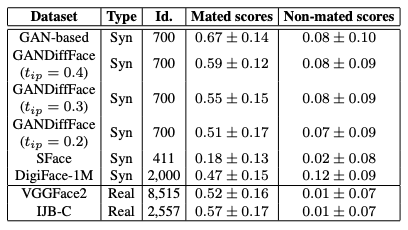
The number of persons (Id) and the mean of the score distribution of matching/non-matching scores (scores) in the actual and synthetic datasets are shown in the table below. From this table, we can see that the mean of the score distribution for matching in the dataset goes down when using the Diffusion model and approaches the mean of the actual dataset. We also see that the synthetic dataset has a distribution more skewed toward positive values than the actual dataset. This is indicative of the difficulty in reproducing realistic variation between classes.
The KL divergence values between the distribution of each dataset and the actual datasets provided by VGGFace2 and IJB-C are shown in the table below.
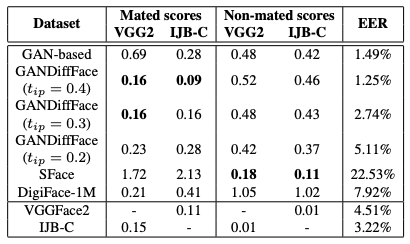
From this table we can see that the synthetic datasets SFace and DigiFace-1M have a worse similarity distribution than GANDiffFace, with an EER about twice that of the real dataset. This is indicative of their failure to reproduce realistic within-class and between-class variation.
Summary
This paper proposes a new framework, GANDiffFace, for building synthetic datasets for face recognition. By connecting Generative Adversarial Networks (GANs) and Diffusion Models (Diffusion Models), we are able to synthesize more realistic and diverse images of people. the first module, GAN, uses StyleGAN3 to generate realistic face images and 70 different demographic statistical groups can be equally represented. The second module, Diffusion Model, uses DreamBooth to tailor a model called Stable Diffusion that is specific to individual people, creating a dataset with intra-class variation that is closer to reality.
On the other hand, however, there are some challenges. In particular, tailoring the model to individual persons requires a lot of computational work. Therefore, while it is theoretically possible to build a large data set, the data in this paper is limited to 700 people. In addition, human-visible artifacts (unnatural parts of the image or errors) may appear in the generated images, especially in parts of the human body such as the hands.
With the breakthroughs in generative AI, research on such synthetic image-based datasets will continue to gain momentum.



Categories related to this article






