20 Times Larger Than Before! Webface260M, A Very Large Public Dataset For Face Recognition
3 main points
✔️ Build a very large public dataset with up to 20 times the number of persons and up to 10 times the number of images compared to MS1M and MegaFace2
✔️ Proposes a new evaluation protocol that takes into account inference time, which is critical in practical face recognition
✔️ Achieved high performance with SOTA in IJB-C and 3rd place in NIST-FRVT
WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition
written by Zheng Zhu, Guan Huang, Jiankang Deng, Yun Ye, Junjie Huang, Xinze Chen, Jiagang Zhu, Tian Yang, Jiwen Lu, Dalong Du, Jie Zhou
(Submitted on 6 Mar 2021)
Comments: Accepted by CVPR2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
Outline
Up to now, in the field of face recognition, as in other fields, research on networks and loss to improve accuracy has been the mainstream. However, on the other hand, there is a lack of large-scale data sets. Especially, there is a lack of a Public dataset.
Some companies that have private large-scale data can conduct research using large-scale data, while academics that do not have data are currently conducting research and development with limited public data.
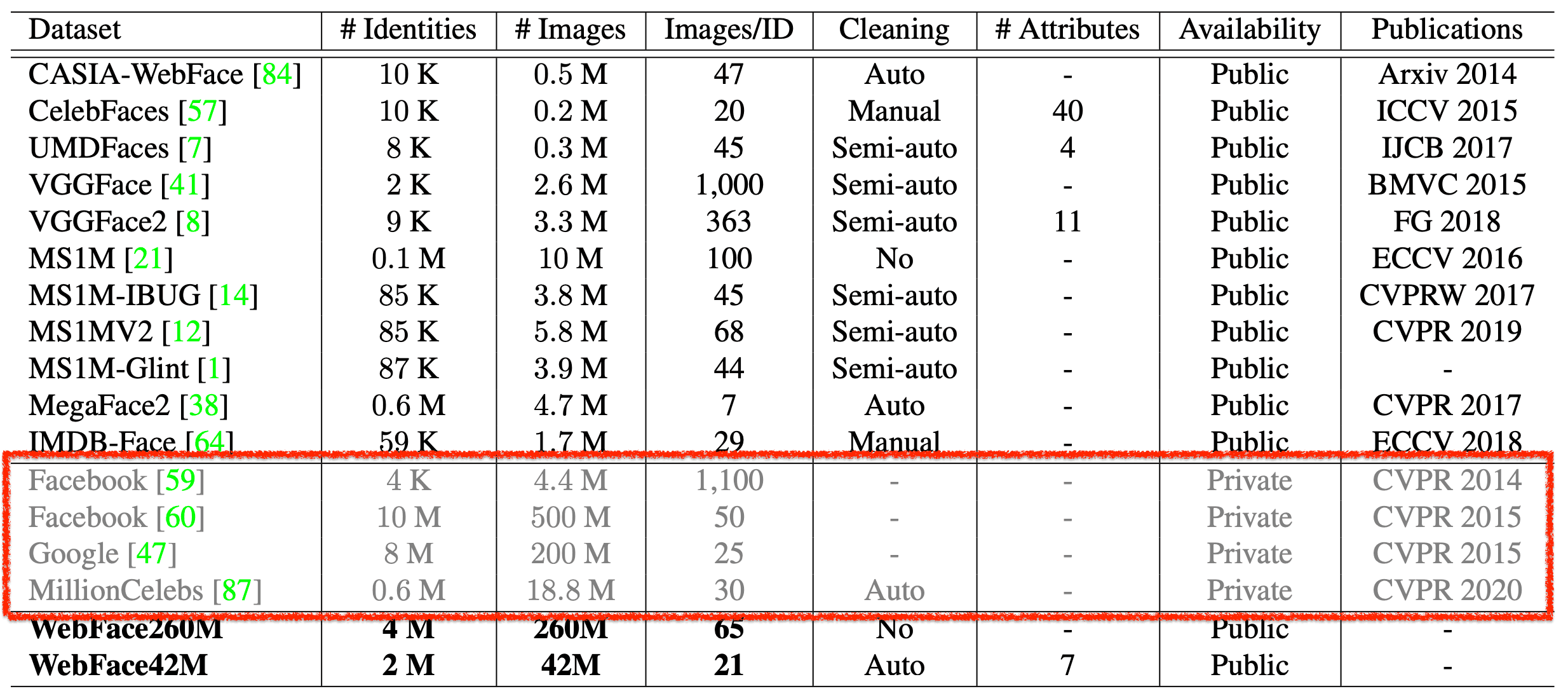
Naturally, the more training data a face recognition model has, the higher its performance will be, but since the Public data is small, the accuracy of the model is saturated. Therefore, in this paper, we provide two new large Public datasets, "WebFace260M" and "WebFace42M".
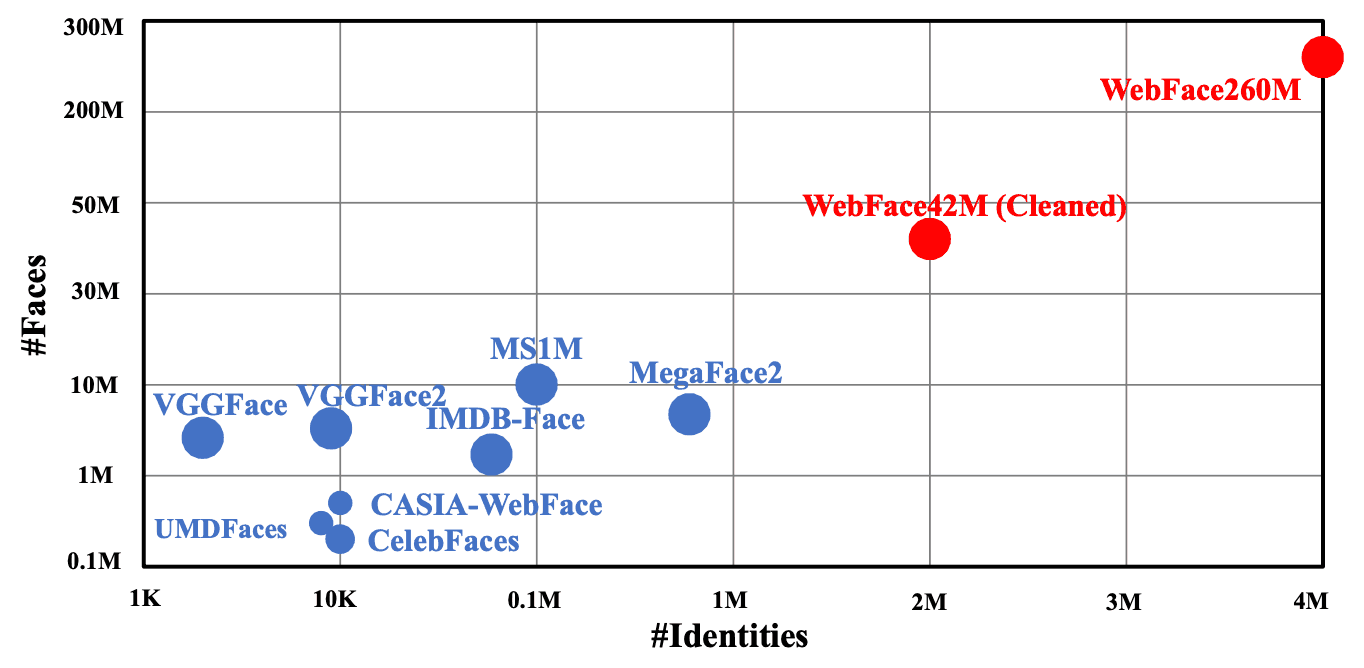
These datasets are up to 20 times larger in terms of the number of people and up to 10 times larger in terms of the number of images than the previously mainstream large datasets, MS1M and MegaFace2.
In addition, in preparing a large dataset, it is not only difficult to collect the subjects, but also difficult to clean the data as the size of the data increases. Therefore, in this paper In this paper, we propose a method to achieve automatic data cleaning by using a pipeline called CAST.
In addition, most of the previous datasets focus on accuracy improvement, but for face recognition, recognition speed is also very important for practical use. Therefore, in this dataset, we also propose a protocol called FRUITS which takes speed into account.
The model trained on WebFace achieves SOTA with a 40% reduction in error rate on the IJB-C dataset and ranks third among 430 models in NIST-FRVT. This result eliminates the data gap between academia and the private sector, and both more and more. We believe that this will be a good opportunity to advance the research of face recognition.
What is the WebFace 260M/42M ultra-large data set?
The two large datasets provided in this project are WebFace260M and WebFace42M. WebFace260M is generated by a large-scale WebFace with noise collected on the web, and then WebFace42M is obtained by automatic cleaning with a pipeline called CAST.
To build the WebFace260M, we first obtain a list of 4M people from MS1M (composed of Freebase) and IMDB. We then used Google image search to retrieve the images. At the time of image retrieval, 10% of the target persons get 200 images each, 20% of the target persons get 100 images each, 30% of the target persons get 50 images each, 40% of the target persons get 25 images each... In total, 260M images are acquired.
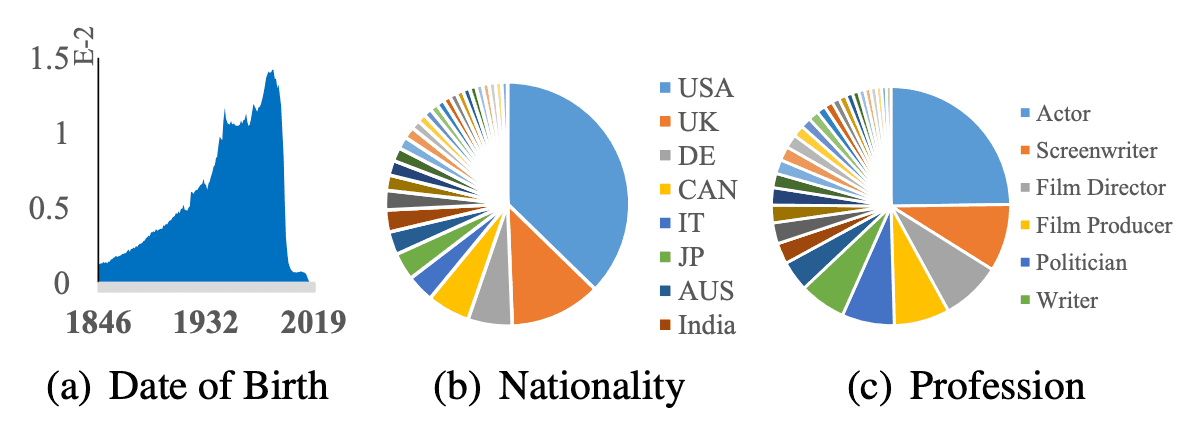
The statistics on the attribute data of the dataset are shown in the figure below. The dataset consists of more than 500 different occupations in more than 200 different countries/regions born after 1846, which guarantees the diversity of the dataset as training data.
Next, we use CAST, described below, to automatically remove the noise. The resulting WebFace42M is constructed from 2M persons and 42M images. This dataset contains at least 3 images for each person and an average of 21 images.
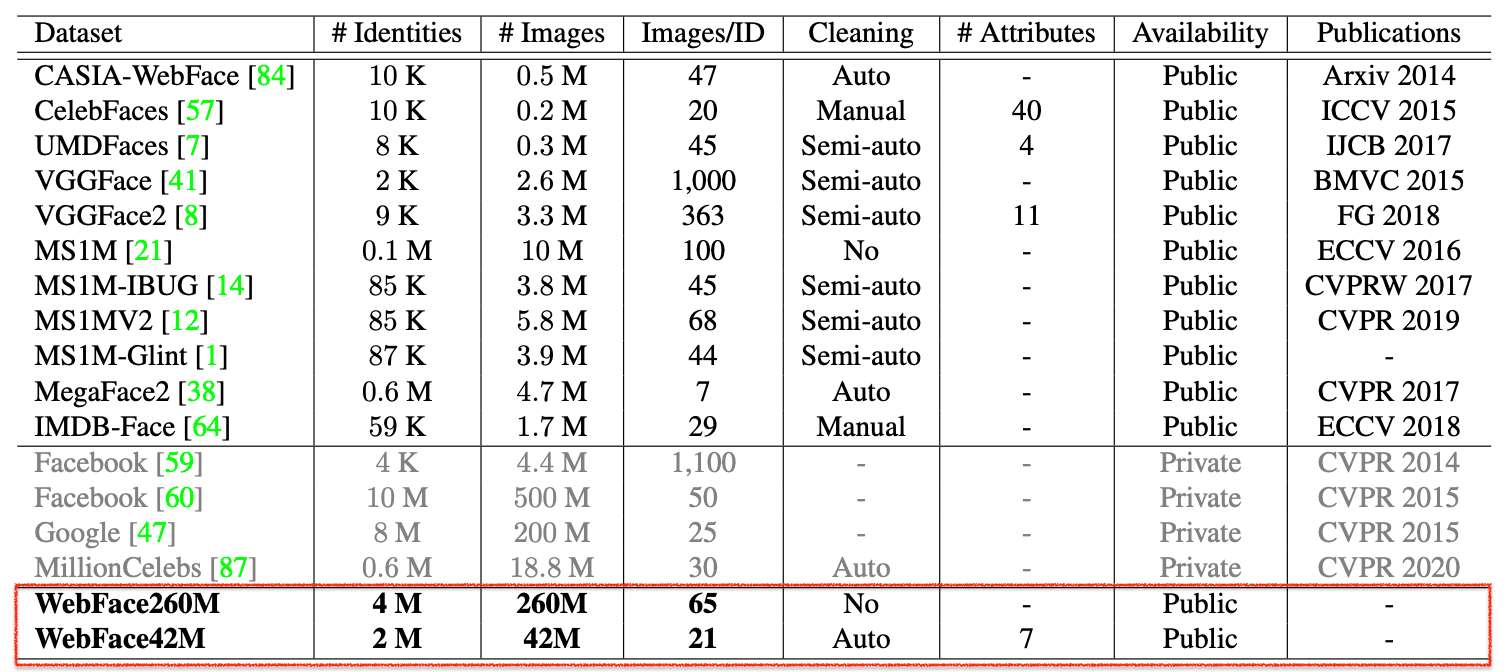
As mentioned at the beginning of this article, WebFace42M has 3 times more IDs and 10 times more images than the previous mainstream MS1M, while MegaFace2 has 20 times more IDs and 4 times more images. The percentage of noise is also less than 10% for WebFace42M compared to about 50% for MS1M and about 30% for MegaFace2 (results from sampling).
We also provide seven facial attribute labels, including pose, age, race, gender, hat, glass, and mask. In particular, face orientation, age, and race comprise the percentages shown in the figure below.
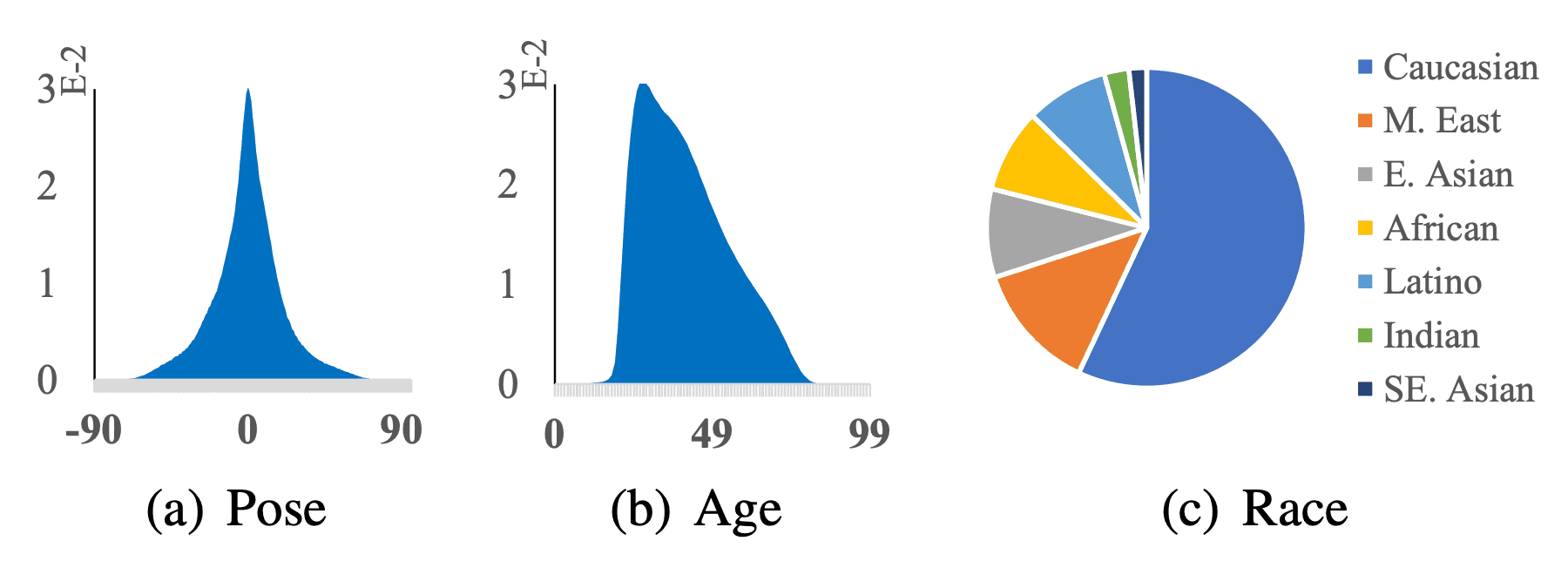
What is the automatic cleaning "CAST"?
The data collected on the web as it is contains a lot of noise data. Therefore, it is necessary to clean the data to build a high-quality dataset. Building a model with training data that contains a lot of noise will degrade the performance. MS1M, which is used as the source for WebFace260M, is said to have a noise fraction of 50%, as mentioned above.
A variety of methods have been used to clean the data sets that have been constructed. In VGGFace, VGGFace2, and IMDB-Face, cleaning is done manually or semi-automatically, but the percentage of human labor is high and very costly. This makes it very difficult to build large data sets. Also, MegaFace2 applies automatic cleaning, but the process is complex and even when applied, it is said to contain much more than 30% noise.
Other unsupervised methods and supervised graph-based methods for clustering facial information have also been studied, but All of these assume that the entire dataset is somewhat elaborate and is therefore not suitable for WebFace260M, which is very noisy.
On the other hand, a standard approach to semi-supervised learning, Self-Traning, has recently been studied to significantly improve the performance of image classification.
In this paper, we introduce CAST ( Cleaning Automatically by Self-Training), as shown in the figure below. However, unlike close-set ImageNet classification, it is not practical to directly generate pseudo-labels in open-set face recognition. Taking this point into account, we introduce Self-Traning (CAST) pipeline is designed for this purpose.
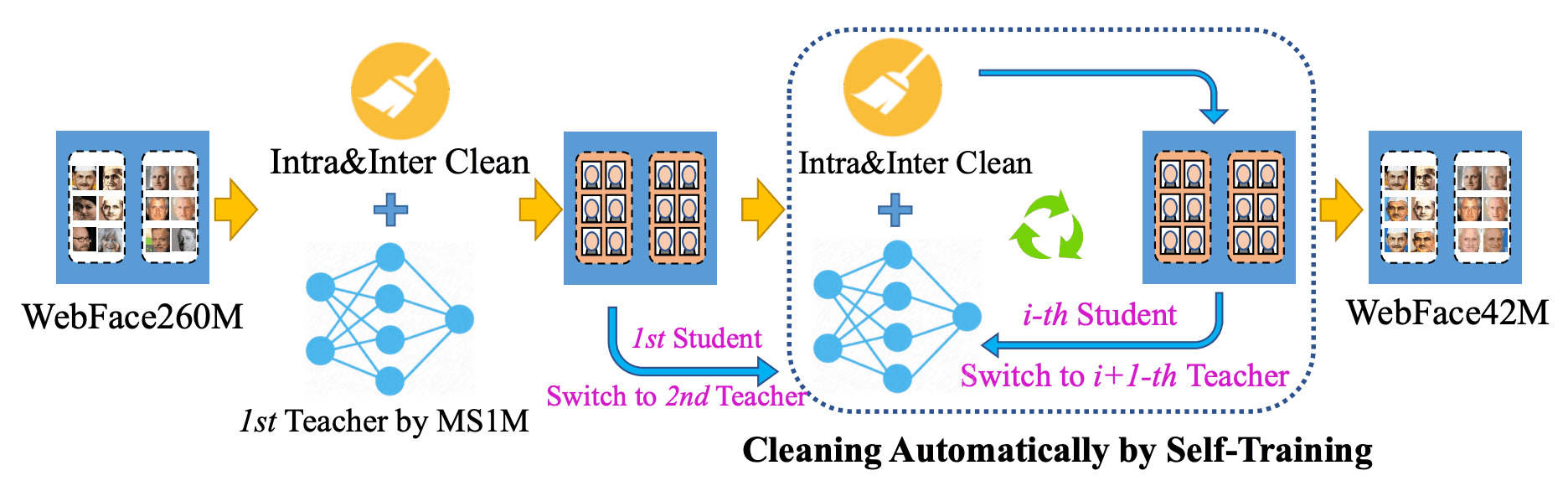
In CAST, we first use the Public dataset MS1MV2 to train a teacher model (ResNet100/ArcFace) to clean 260M images within/across classes. Next, we train a student model (also ResNet-100/ArcFace) on this cleaned dataset and clean it within/across classes. After this, We then switch back and forth between the student model and the teacher model until we have a high-quality 42M image.
After CAST, if the cosine similarity is greater than 0.95, the subjects are considered to be identical and duplicates are removed. In addition, the center of each subject's features are compared to key benchmarks (e.g., LFW, FaceScrub, IJB-C) and the proposed test set to be built in this paper, described below, and removed as duplicates if the cosine similarity is greater than 0.70.
The higher the number of CAST iterations, the clearer it becomes, and the lower the number of IDs and images, the more these duplicates are removed, and finally, we get a WebFace42M of 2,059,906 IDs and 42,474,558 images.
What is the FRUITS protocol?
FRUITS (Face Recognition Under Inference Time conStraint) is a protocol to evaluate the performance at a specific inference time depending on the use case in practical applications.
Although various performance evaluation protocols have been proposed, such as FRUITS (Face Recognition Under Inference Time conStraint), there have been few models that consider inference time. However, this perspective is important, especially when using lightweight models such as those used at the edge.
The Lightweight face recognition challenge has been proposed for the same purpose. However, it does not take into account the preprocessing required for face recognition, such as Face Detection and Face Alignment, and thus its performance evaluation is somewhat limited when considering practical use. The FRUITS proposed in this paper evaluates a series of processes of face recognition including Face Detection and Face Alignment.
NIST-FRVT has a similar protocol for performance evaluation, but it is difficult to apply for it because of its requirements. In this paper, we propose a new protocol that can be easily evaluated using public data.
In this FRUITS protocol, we have prepared three conditions.
- FRUITS-100
This is a performance evaluation of a series of face recognition processes, including Face Detection, Face Alignment, Feature Embedding, and Matching, within 100 ms. It is mainly intended for benchmarking face recognition systems implemented in mobile devices. - FRUITS-500
This is a performance evaluation of a series of face recognition processes within 500ms.
It is assumed to be a benchmark for a face recognition system implemented in a local surveillance camera. - FRUITS-1000
This is a performance evaluation of a series of face recognition processes within 1000ms.
It is intended as a benchmark for face recognition systems used in the cloud.
These inference times are Intel Xeon CPU E5-2630-v4@2.20GHzによって計測されます.
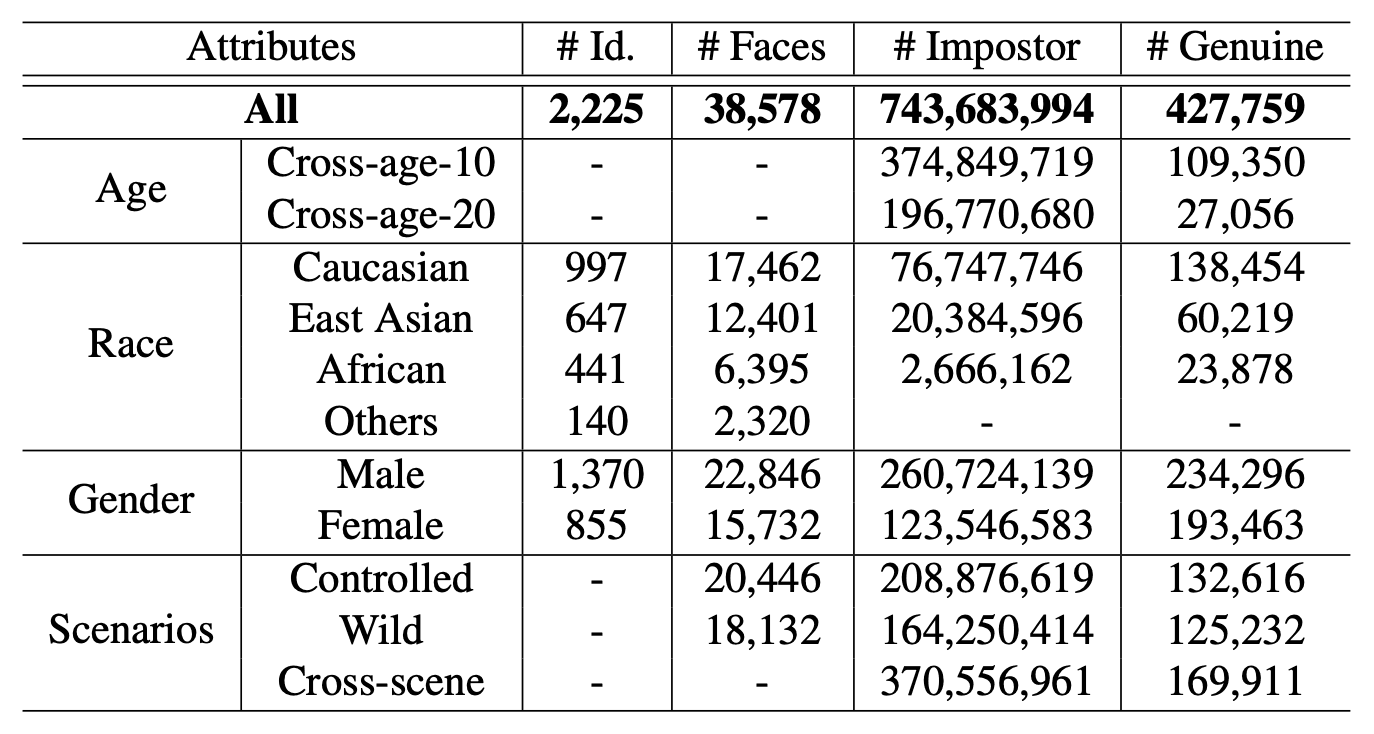
FRUITS provides a carefully selected set of more elaborate test sets with noise removed. The annotator manually selects high-quality images while balancing the attribute information. Finally, the statistics of the test set are shown in the table below. The total number of people is 2,225 and the total number of images is 38,578.
The performance evaluation is based on this FRUITS protocol and the test set described below to evaluate the performance of 1:1 verification. We use False Match Rate (FMR) and FalseNon-Match Rate (FNMR). A lower FNMR with the same FMR indicates better performance.
experiment
Influence of training data set
In order to investigate the impact of new training data, we apply the main loss functions (ConFace/ArcFace/CurricularFace) based on using ResNet-100 and perform comparative validation using the Public test set. The table below shows the model trained on various training datasets (Data) and tested on various test datasets (Pairs / RFW / RFW Mega/IJB-C/Ours).
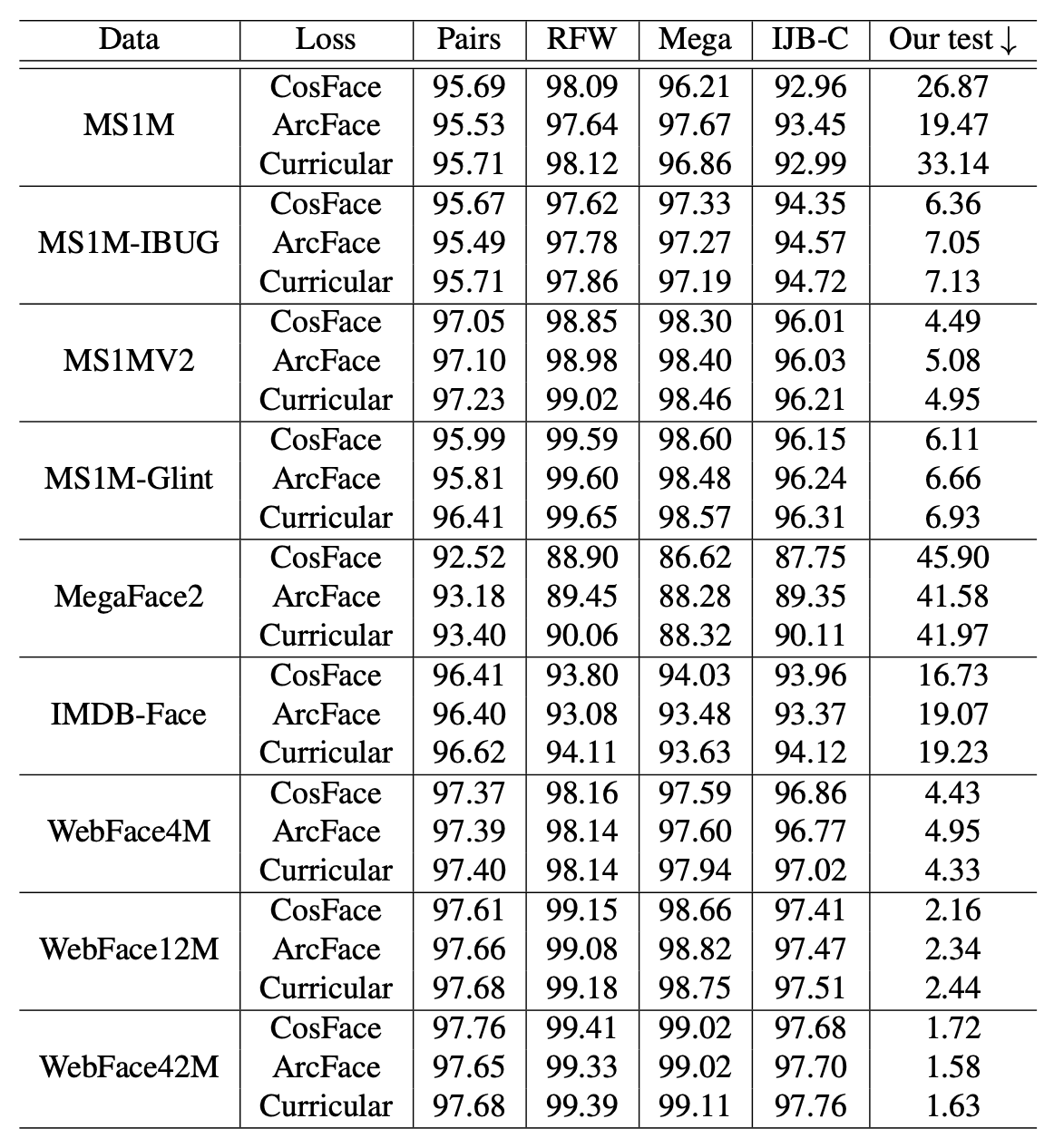
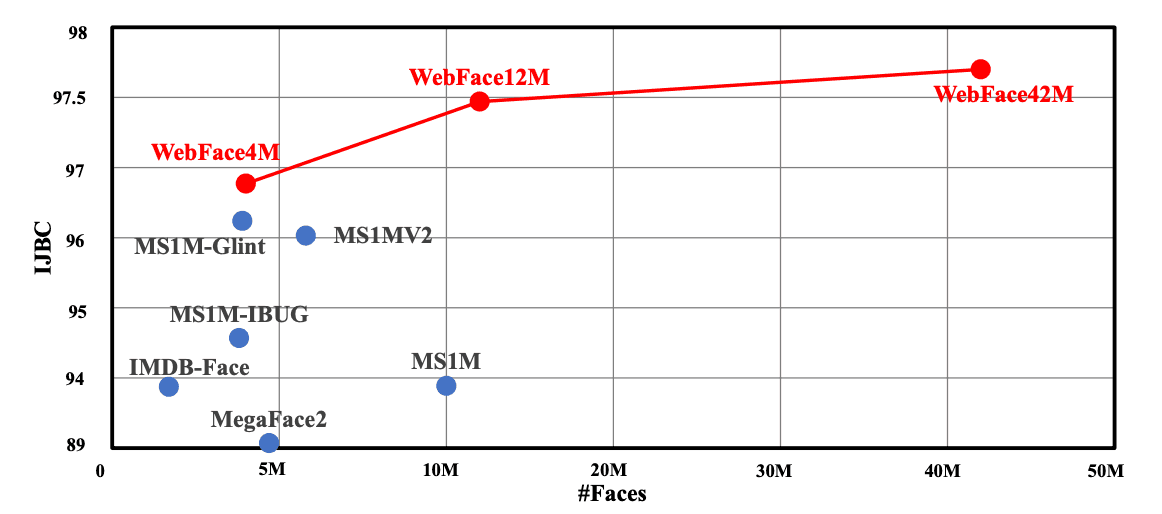
We can see that the models trained with WebFace42M show the highest performance. In particular, compared to the MS1MV2 training data with IJB-C as the test data, the TAR (True Accept Rate) at FAR (False Accept Rate) = 1x10-4 is improved from 96.03% to 97.70%, and the error rate is reduced by 40%.
Also in WebFace, comparing 4M, 12M, and 42M, we can see that the performance improves as the number of data increases.
Results from the FRUITS protocol
We evaluate the performance with the FRUITS protocol. The table below shows the list of baselines prepared for this project. It shows various face recognition systems, including modules up to Face Detection (Det), Face Alignment (Align), and Face Embedding, and their inference speed (Time).
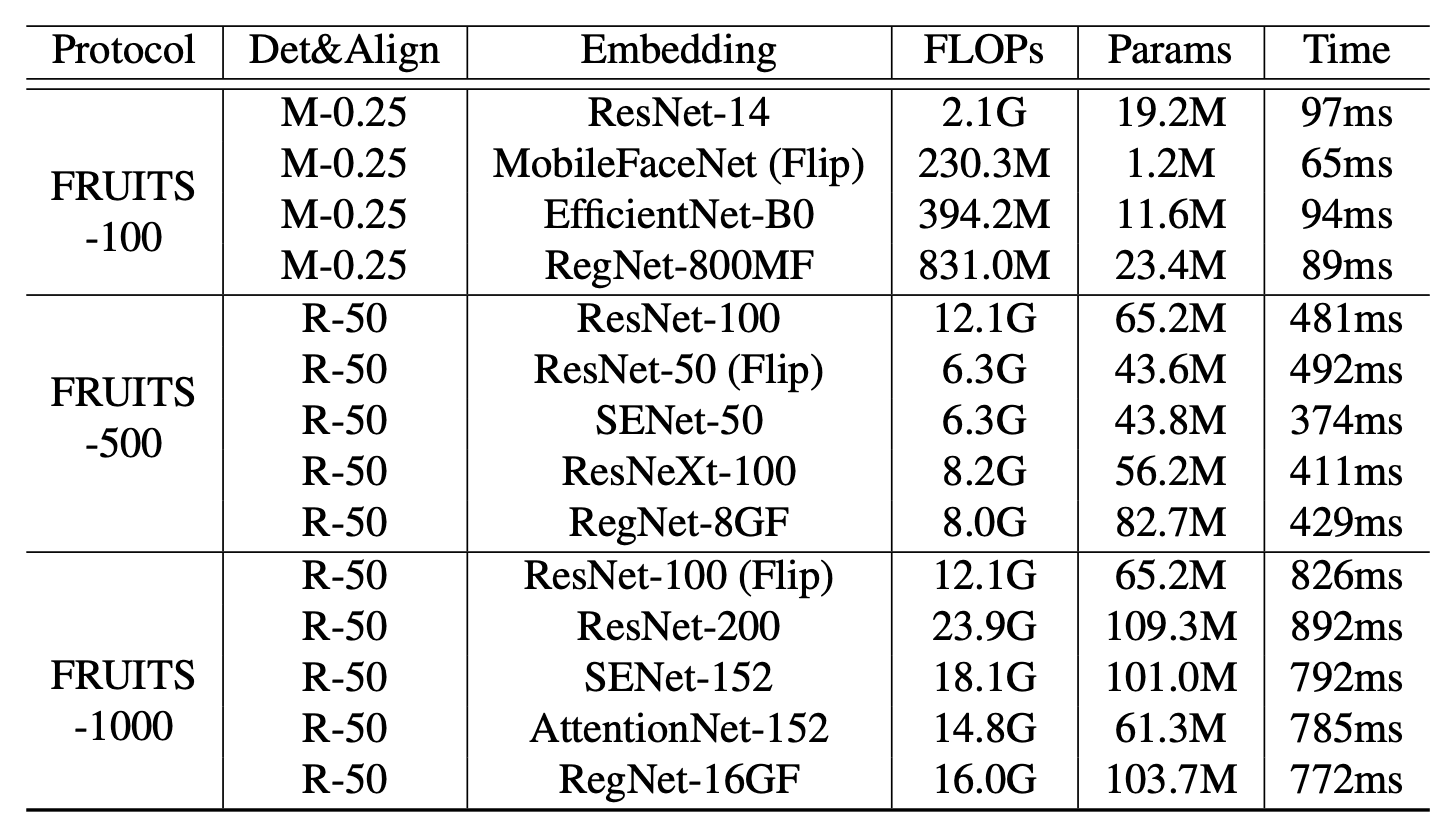
All models apply ArcFace and are trained with WebFace42M. For Embedding, we also apply typical network architectures such as MobileNet, EfficientNet, AttentionNet, ResNet, SENet, and ResNeXt.
FRUITS-100 has very tight inference speed limits, so we used RetinaFace-MobileNet-0.25 (M-0.25) for Det&Align, ResNet-14 for Embedding, MobileFaceNet, EfficientNet-B0, and RegNet-800MF, and other lightweight architectures are applied. The results of FNMR and attribute bias analysis for All in the test set are shown in (a) and (b) below.
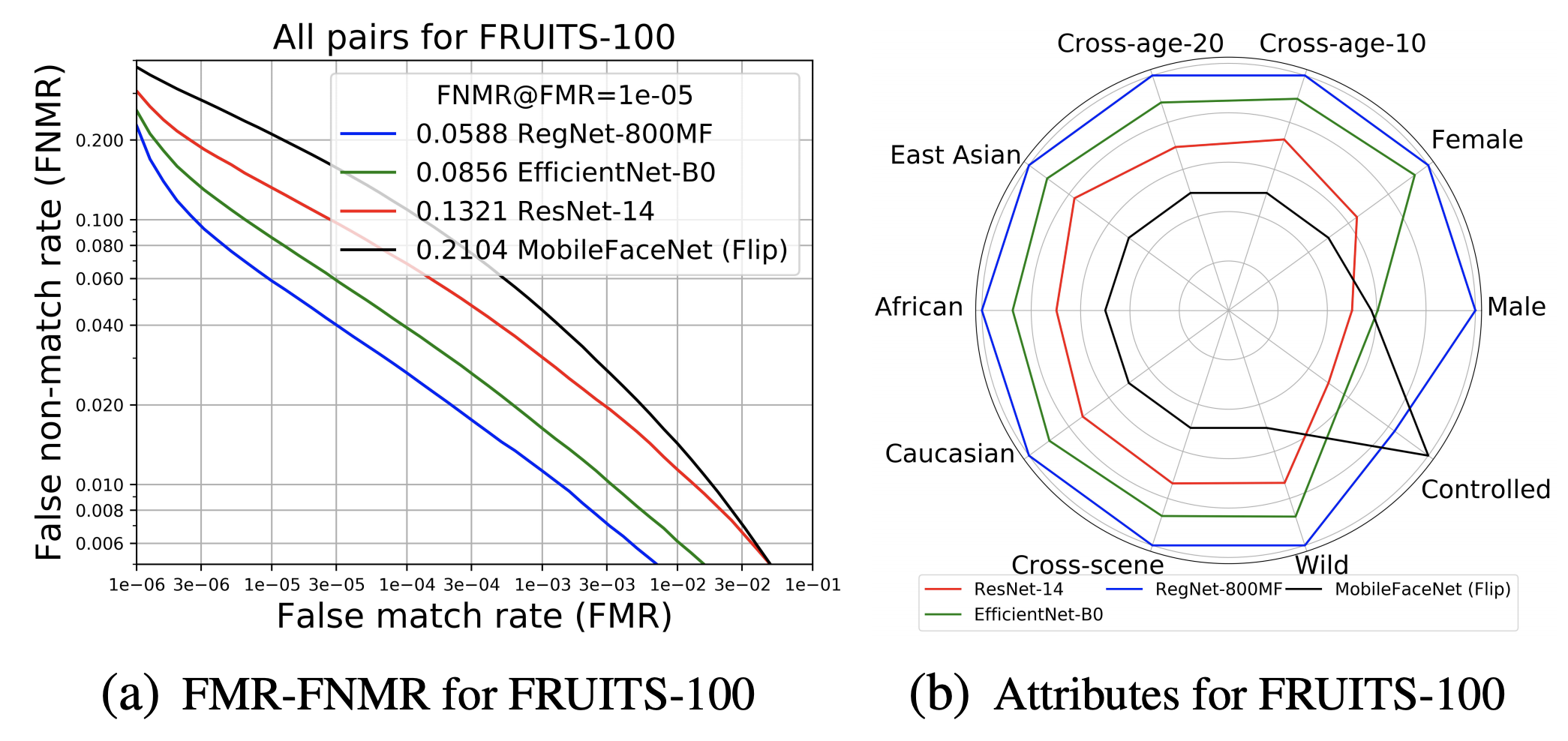
Since we are applying a lightweight model under very constrained conditions, the best baseline (RegNet800MF) gives an accuracy of about 5.88% FNMR@FMR=1x10-5. It can be said that there is still a very large room for improvement in FRUITS-100.
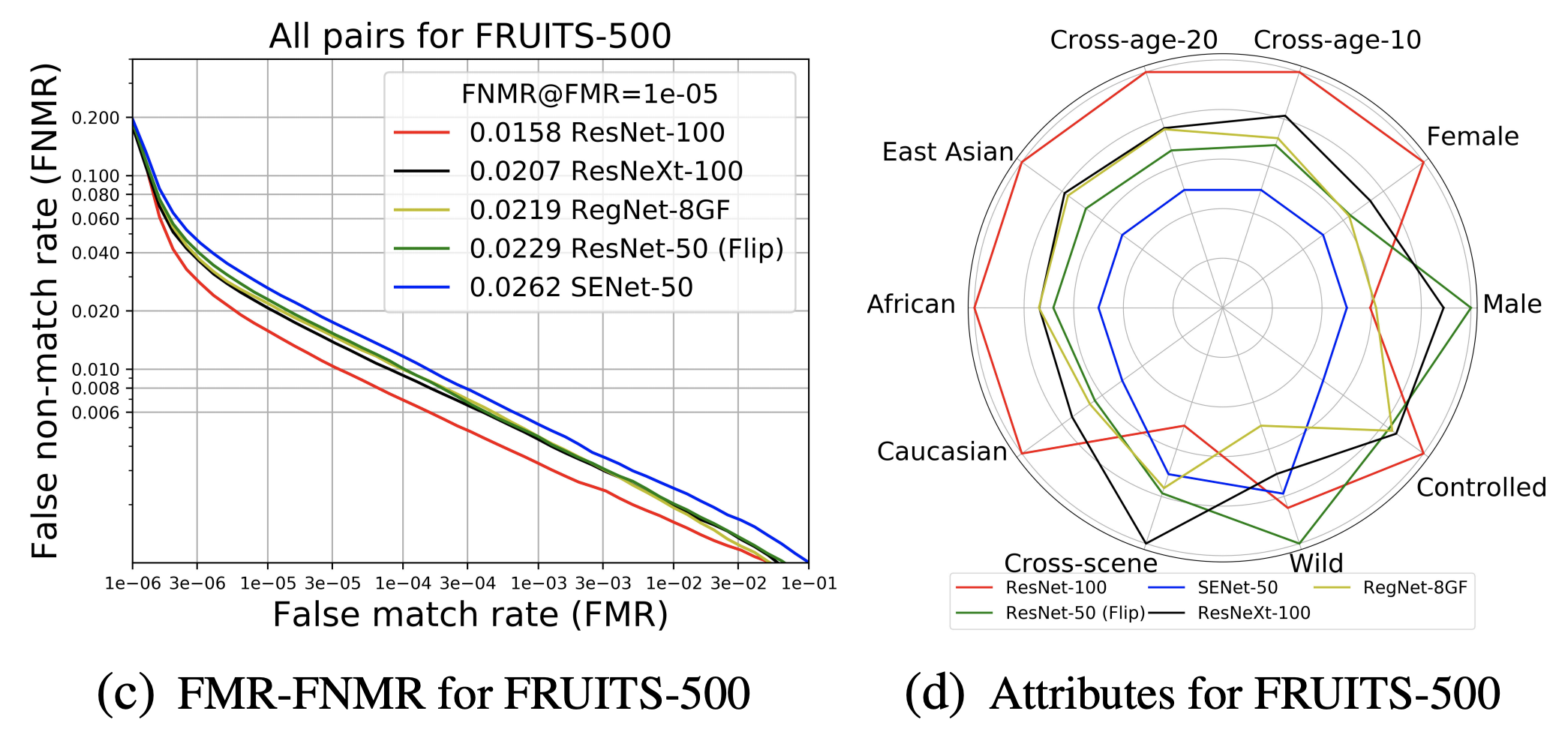
FRUITS-500 will be able to apply a higher performance model compared to FRUITS-100. We apply RetinaFace-ResNet-50 (R-50) for Det&Align, ResNet-100, ResNet-50, SENet-50, ResNeXt-100 and RegNet-8GF for Embedding. The results of FNMR and attribute bias analysis for All in the test set are shown in (c) and (d) below. The best baseline (ResNet-100) shows the best overall performance without bias.
FRUITS-1000 applies ResNet-100, ResNet-200, SENet-152, AttentionNet-152, and RegNet-16GF for Embedding. Te The results of FNMR and attribute bias analysis for All in the test set are shown in (e) and (f) below.
Results of NIST-FRVT
NIST-FRVT (Face Recognition Vendor Test) is a performance evaluation test of face recognition models conducted by NIST (National Institute of Standards and Technology, USA), which defines security standards. Internationally, it is common to evaluate face recognition models by the results of NIST-FRVT.
This paper has been submitted to this international evaluation test, the NIST-FRVT. The model we applied is based on the trained on WebFace42M using RetinaFace-ResNet-50 for Face Detection and Face Alignment, and ArcFace-ResNet-200 for Face Embedding, according to the FRUITS-1000 configuration.
The model trained with WebFace42M (OURS) ranked third out of 430 models submitted. The results show high performance on a variety of tasks. of the top five models in NIST-FRVT. in the FNMR. of the top five models in NIST-FRVT is shown in the table below.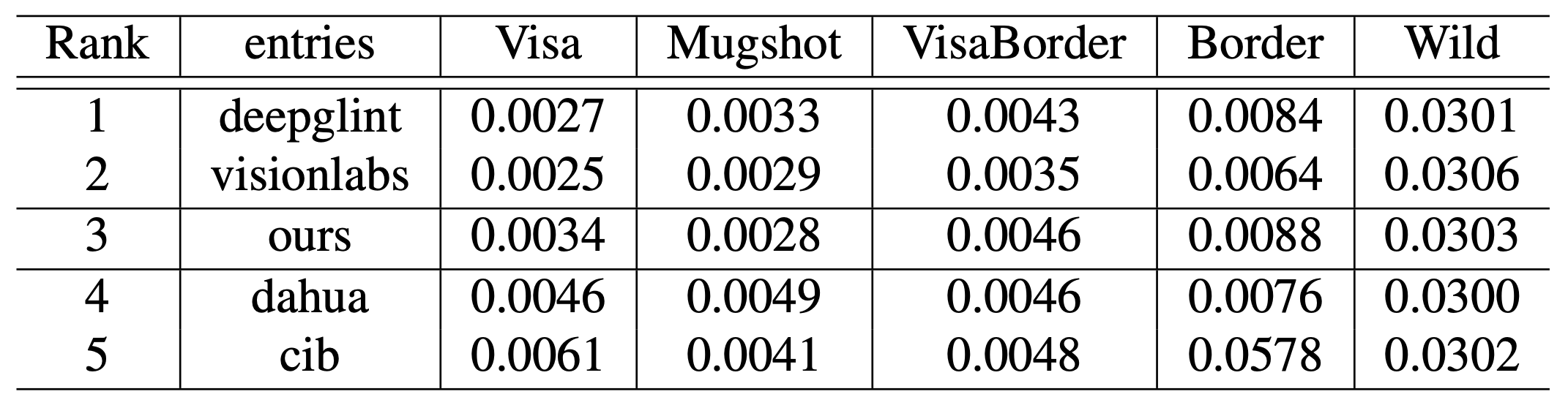
As can be seen from the NIST results, the high performance of WebFace42M on Public data, while private companies with large datasets are the top performers, will be an important opportunity to bridge the gap between academia and the private sector in face recognition research.



Categories related to this article






