Photorealistic Image Generation Using G-buffers And Rendering Pipelines!
3 main points
✔️ Generating realistic images using G-buffers and a rendering pipeline
✔️ Analyzing Artifacts occurrences that cause layout collapse
✔️ Successful transition of GTA V scenes into photorealistic scenes
Enhancing Photorealism Enhancement
written by Stephan R. Richter, Hassan Abu AlHaija, Vladlen Koltun
(Submitted on 10 May 2021)
Comments: Accepted by arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR); Machine Learning (cs.LG)
code:

Outline of Research
This research focuses on the realism of synthetic images (images that represent the real world on a computer). The focus is mainly on making the game world look like the real world, and the research applies the proposed method to Grand Theft Auto V to generate a realistic game world as an example.
The conventional approach is to improve the convolutional network using a rendering technique to obtain a representation of the middle layer, and then use the latest adversarial objective function on this network to learn to achieve super-resolution at multiple perceptual levels. to achieve super-resolution at multiple perceptual levels.
However, in the previous research, it was difficult to control, and various artifacts (artifacts or impurities in the generated image) were generated, resulting in fake-looking images. Therefore, in this research, we proposed a method of sampling image patches during training and a multi-layered structure of the deep network and succeeded in improving the realism and generating stable images.
Proposal of a comprehensive Photorealistic method
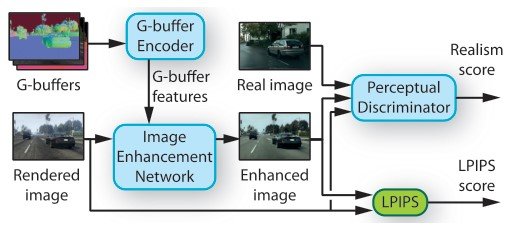
Outline of the proposed method
The proposed method consists of three networks. (1) Image enhancement network, (2) Rendering buffers (G-buffers) for the middle layer, and (3) Perceptual Discriminator. Finally, we analyze the dataset to prevent layout collapse caused by artifacts during adversarial training.
Image enhancement network
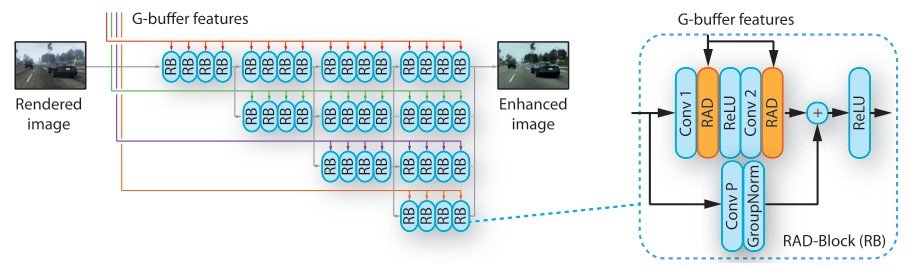
The image enhancement network is based on HRNetV2 and excels at prediction tasks. It takes rendered images and G-buffer features (described later) as input and outputs realistic images. The input G-buffer is divided into different resolutions, and HRNet handles images in parallel through multiple branches that handle these different resolutions. (The colors in the image correspond to the different resolutions.
In this study, we improve HRNet in two ways.
- The first stridden convolutions are replaced by regular convolutions to handle the full resolution and preserve the image details
- Within the residual blocks, the batch normalization layer is replaced by the rendering-aware denormalization (RAD) module
Rendering-aware denormalization (RAD) Rendering-aware denormalization (RAD)
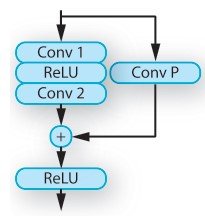
RAD is a module that is responsible for adjusting feature vectors based on external information. In particular, it is a module that learns weights from scene representations and transforms the feature vectors obtained from the G-buffer encoder network using two residential blocks. residential blocks are used in the G-buffer encoder and RAD and consist of a convolutional layer, spectral normalization, and ReLU. It consists of a convolutional layer, spectral normalization, and ReLU.
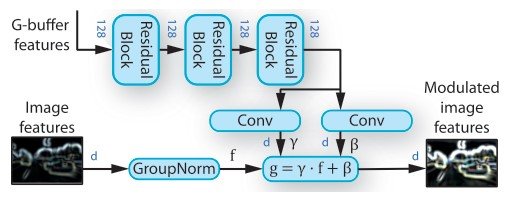
The transformed features are used to learn the elementwise scale $\gamma$ and the shift weights $\beta$. As you can see in the figure below, the weights represent the parameters of the affine transformation of the normalized image features. ($g = \gamma \dot f + \beta$) where the input external information is the feature vector of geographical, object, light, and semantic information of the image obtained through rendering. For each RAD module, we transform the feature vector of the G-buffer using three residential blocks.
Objective function
The image enhancement network is trained with two objective functions.
- LPIPS loss for structural differences between input and output images using LPIPS loss (LPIPS score)
- The perceptual discriminator evaluates the realism of the output image (Realism score).
Compared to traditional methods, we use a specific sampling technique in real and synthetic image patches to reduce the number of significant artifacts while learning.
The rendering pipeline
Real-time rendering usually incorporates multiple passes into the rendering process. One of the features of G-buffers is that they can learn to understand semantic information without being given it ([S. R. Richter et al. G-buffers are able to learn to understand semantic information without providing it ( [S. R. Richter et al., A. Shafaei et al. ]), and by capturing geographic and object features and inputting them into the network, the conversion from pseudo-image to real image can be performed with higher accuracy.
Extraction of G-buffers
The goal of this research is to obtain G-buffers from the game Grand Theft Auto V. We use techniques to extract resources for rendering from computer games ( [S. R. Richter et al, S. R. Richer et al., P. Kr¨ahenb ¨uhl ]) and extract G-buffers with information such as geographical structure (representation, depth), objects (shader ID, reflectivity, transparency), luminosity (approximate luminosity and emission, sky), and other informative G-buffers are extracted.

In addition, from G-buffers
- Check pixel-by-pixel reflections using viewpoint vectors on the surface of the object and extract the reflection vectors
- Calculate the dot product of the surface and this reflection vector
I am.
The results can be found in Section 4.4 of the main text (Do G-buffers help?) and show that without the information from the G-buffers, the computation for low-dimensional features is rough, and with the addition of G-buffers, realistic scenes can be reproduced for features of all dimensions in the VIPER dataset. in the VIPER dataset.
In the experiment "How to ingest G-buffers?", the simple addition of G-buffers (concat) resulted in better overall performance than the network with SPADE module ([14]) instead of RAD module. the network with SPADE module instead of RAD module. In addition, the network using SPADE module produces highly variable results on the dataset, some of which are realistic and some of which are complete failures. On the other hand, the proposed method using the RAD module consistently produces highly accurate results.

G-buffers Encoder
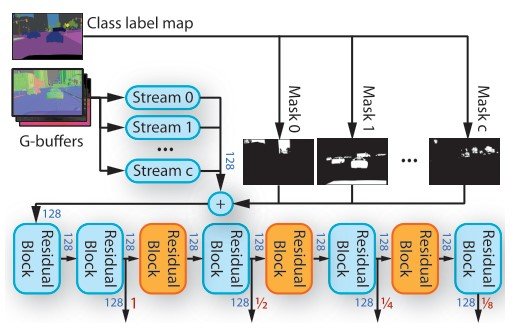
G-buffers extract material information, depth image, normal image, continuous depth value in the color image, and sparse continuous information such as trees and sky. To deal with each information of G-buffers, we use a G-buffer encoder as shown in the figure above. The G-buffers encoder has multiple network streams, and each stream consists of two residual blocks (Fig. 8). Thanks to this mechanism of residual blocks, we can train at multiple scales.
Let $f_c$ be the feature tensor of the stream when the object class $c$ is the target, and $m_c$ is denoted as the mask of the object. The object is then masked. ($\Sigma_c m_c \cdot f_c$)
The ID of an object is grouped with multiple class labels from the semantic segmentation map. This allows the G-buffers to map the object type to the stream. The output feature tensor is input by the image enhancement network through the RAD module.
Perceptual Discriminator
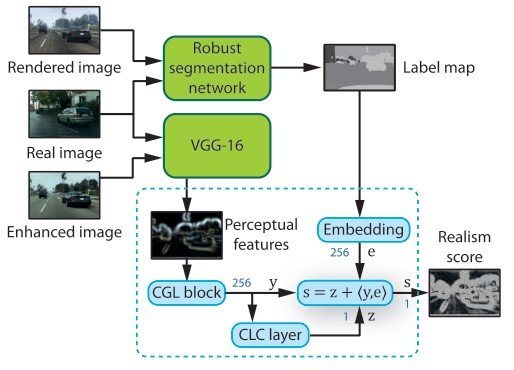
While training an image enhancement network, the realism of the output image is evaluated by a perceptual discriminator. This discriminator consists of a robust semantic segmentation network (MSeg), a perceptual feature extraction network (VGG-16), and multiple discriminator networks.
This segmentation network is applied to the target dataset and the unaltered rendered image. This gives us the semantic information of real and synthetic images. Note that if we train on synthetic images, we will lose generality for realistic data. Also, we do not use backpropagation for the segmentation network because it is not necessary for generating realistic images.
By applying VGG to real and highly accurate images, we can obtain perceptual features of abstract information per dimension and apply the network according to the perceptual level.
Analysis of layout changes caused by Artifacts
In the adversarial setting, the discriminator labels images as real or fake in order to identify them during training. It then back-propagates on this gradient to add noise so that the generator can produce more realistic images.
Here, if face and real images can be identified with fake features, for example, if more fake GTA V empty images are trained and there is a tree at the same pixel location in the Cityscapes dataset, then a tree will be generated at the empty location in GTA V. This is a problem.

As you can see from the probability depth map above, the data set is trained with a uniform distribution, so if the information of the sampling location is different, the generated information will be different.

A sampling of the corresponding patch
The above analysis shows that randomly sampling images in GTA and Cityscapes result in different layouts than expected even though the same object information is obtained.
Therefore, we propose a different sampling technique here. First, we try to crop only 7% of the total displayed image. Second, we adjust the sampled patches so that the distribution of objects displayed by the discriminator is stable. This is calculated in such a way that if the cosine similarity of the pixels of the cropped patch and the feature tensor extracted by VGG16 is higher than 0.5, the two patches are matched. (For more details, please refer to the paper)
The discriminator is the one from PatchGAN. (Which discriminator?) The projection layer described above is less accurate in higher dimensions, while adaptive backpropagation is more accurate in the highest dimensions.

experiment
In our experiments, we use the Kernel Inception Distance (KID) to evaluate the realism, which measures the distance between semantic structures, but does not directly measure the realism, and may ignore information in the rendered image. This is why we use the inception network. Therefore, we propose a method to replace the features obtained by the inception network with the features of different layers of VGG. (the squared maximum mean discrepancy (MMD)) This allows us to consider the perceptual image quality. ( [Q. Chen, R. Zhang ])
In order to align the distribution of patches used to obtain features between datasets, we extract patches of 1/8 of the image size from the semantic label map of each dataset and further downsample them. Then, the vectors of the synthetic dataset (in this case, GTA V) are searched for paired patches from the real dataset using the nearest neighbor. This yields the following semantic counterparts of the patches.

Comparison with previous studies
In this section, we provide a comparison on the accuracy of photorealism enhancement with previous studies: for the methods that require semantic segmentation labels as input, we use synthetic and real images as proposed by MSeg [72], and the proposed We used a similar robust segmentation network for the discriminator.
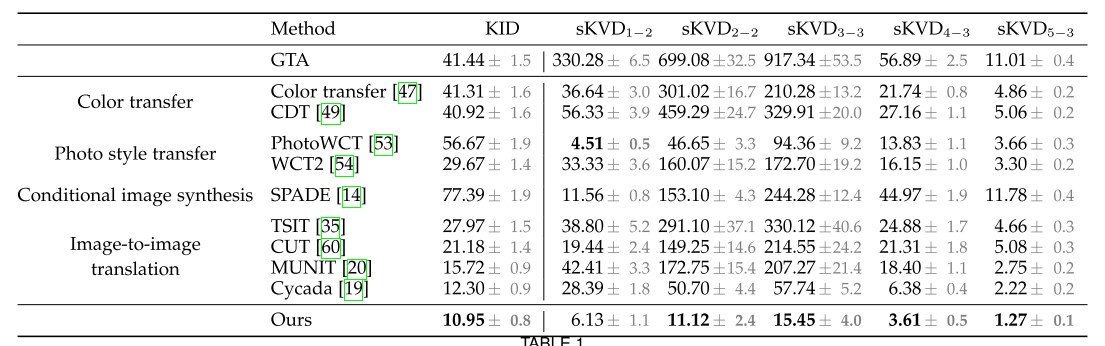
We look at the results in Table 1. As an experiment for comparison, the
- Color transfer (does it generate colors well?)
- Photo style transfer (whether the image style is successfully generated)
- Conditional image synthesis (whether the image can be reproduced under certain conditions)
- Image-to-image translation (whether the image can be generated in another domain)
We are doing four things
Color transfer is compared to color transfer (Color Transfer ) and color distribution transfer (CDT ). These methods limit the color of the pixel, making it difficult to improve the expressiveness of the texture and causing artifacts (see figure below). As a result, we are seeing more significant improvements in the evaluation of low-dimensional features.

Photo style transfer compares with closed-form (equations for which solutions exist) solutions of fast photographic style transfer ( PhotoWCT ) and current SoTA wavelet transforms (WCT2). Each approach requires a style image and a semantic segmentation map for the source and style images; the part that differs from color transfer is that it does not transform the pixel colors, but rather the learned, high-dimensional feature space derived from semantic segmentation. Thus, the transformation is more powerful than color transfer.
However, photo style transfer relies on the style image matching the input image. Therefore, when the input image changes, photo style transfer can produce unrealistic color transitions and temporarily unstable images by interactively learning the synthetic environment.
Conditional image synthesis is compared with the most powerful SPADE. We train it on prepared urban images, and the results show that SPADE is less accurate than any of the methods. The reason for this is that compositing photos from only semantic segmentation maps is more difficult than simply modifying the images, and SPADE is trained to compose images into images from the Cityscapes dataset, which means that between Cityscapes and GTA because of the transitions in the distribution of scene layouts.
Image-to-image translation is compared with Cycada and various other methods, where Cycada is specialized in transforming synthetic images into realistic photographs. This method uses pixel-level cycle-consistency with low-dimensional features cycle-consistency and semantic consistency loss (deals with semantic labels to preserve the information of the composite image).
Among these methods, Cycada gave the best accuracy, but it used more semantic information than perceptual loss (visually perceivable differences), but as shown in the figure, it produced unrelated objects. This is probably due to the fact that the segmentation network was pre-trained on unaltered synthetic images and was not updated during the training of the synthetic network of images. (Figure 11)
Summary
In this study, the information from the G-buffers was well incorporated into the feature space, and the Image Enhancement Network, which is a network that generates high-precision images at each scale, was trained using the rendering technique. This is thought to be a factor in the success of the photorealistic task. In addition, the analysis by comparing the probability density distributions of the datasets may have captured the factors that cause the occurrence of Artifacts. Maybe one day in the future, GTA and other video games will be indistinguishable from real life!



Categories related to this article


