How To Get The Real Value Out Of GPT-3 : Prompt Programming
3 main points
✔️ The problem with few-shots in GPT-3
✔️ What is GPT-3 really learning?
✔️ Show how GPT-3 really extracts its learned functions
Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm
written by Laria Reynolds, Kyle McDonell
(Submitted on 15 Feb 2021)
Comments: Accepted to arXiv.
Subjects: Computation and Language (cs.CL); Artificial Intelligence (cs.AI)
code:
First of all
GPT-3 achieved the highest level of results for various language tasks by using Few-Shot Prompt. However, when extracting specific learning results from a self-supervised learning language model, prompt may be more effective than fine-tuning or Few-shot format.
Contrary to the validity of the Few-shot format indicated by the title of the GPT-3 paper (Language models are few-shot learners), we believe that GPT-3 does not actually learn the task at runtime.
The main function of Few-shot is not to do meta-learning, but to find already learned tasks in the model.
I prove this by showing a prompt that can extract more performance than the Few-shot format without a sample. 
Scrutiny of Few-shot prompt
The accuracy of GPT-3 was evaluated on the prompt task for 0-shot (natural language explanation only), 1-shot (one correct example), and n-shot (n correct examples). The results show that GPT-3 performs better with more examples, while the 0-shot case is almost always less than half as accurate as of the n-shot case.
The general interpretation is that GPT-3 learns n-shot samples because GPT-3 produces better accuracy with more samples than without.
However, another interpretation is also possible. Instead of GPT-3 learning how to execute a task from Few-shot, isn't Few-shot instructing GPT-3 what task to solve and encouraging it to follow the prompt structure?
In the case of a specific task, for example, translation, a small sample is very insufficient to learn anything substantive about the task.
Prompt programming
To understand autoregressive language models, we first need to consider the context in which they are learned and the function they approximate: GPT-3 is trained in an auto supervised setting on several hundred Gbytes of natural language. This is a form of unsupervised learning, where the ground-truth label is the next token in the original sentence and is derived from the data itself.
Thus the function that GPT-3 approximates is the dynamics of determining the next token in the original sentence. It is the very function of language as used by humans, and is tremendously complex beyond our control.
The dynamics of language involve predicting how words will be used in practice. The dynamics of language is not free from cultural, psychological, and physical contexts. It is more than just a theory of grammar and semantics. For this reason, language modeling is as difficult as modeling all the real possibilities that affect the flow of language. In this sense, GPT-3 clearly does not learn the ground-truth function.
However, we have shown that it approximates to a remarkable degree, as evidenced by its ability to learn cultural references and metaphors and to model complex psychological and physical contexts. The inverse problem of exploring Prompt also involves high-level mental concepts such as tone, connotation, association, meme, style, plausibility, and ambiguity. concepts such as tone, connotation, association, meme, style, plausibility, and ambiguity, making it a challenging problem.
Rewriting Prompt can significantly change the performance of the language model for a task, but formulating Prompt programming precisely is a very difficult problem. However, humans spend most of their time learning heuristics about the dynamics at hand, so Prompt programming has the advantage of being effective.
Prompt programming, where the input and output are in a natural language, can be thought of as natural language programming. It makes use of a myriad of functions that humans are familiar with, but which are not named.

"Simple Colon" Prompt format Bold text will be replaced by text in the source or target language.

"Master Translator" Prompt format source_phrase is replaced by the text in the source or target language.
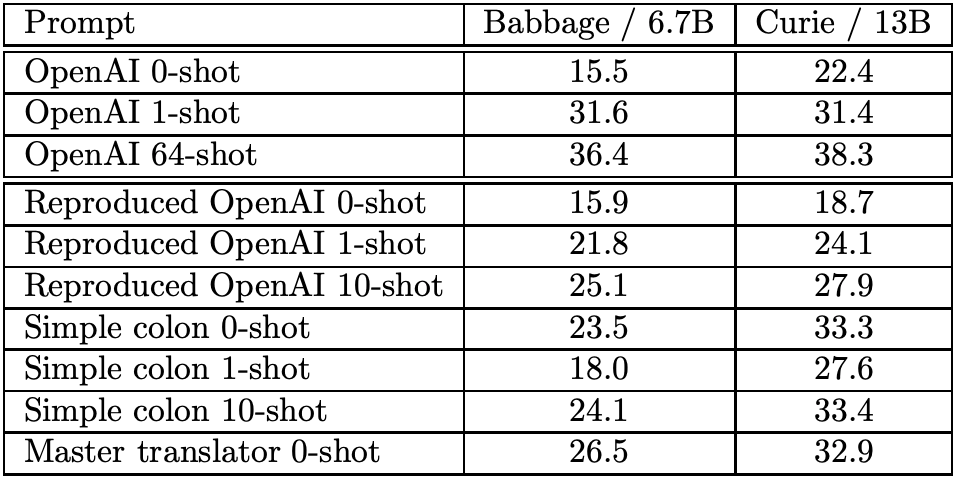
We compare the BLEU scores of the GPT-3 models (Babbage and Curie models). We compare the results of the proposed methods (Simple Colon and Master Translator) with the values given in the GPT-3 paper. Below we show how they can help create effective prompts.
Direct task specification: constructing the signifier
A signifier is a key pattern of intended behavior. This is the name of the task, such as translate, or a compound description, such as "Paraphrase this paragraph so that second graders can understand it and emphasize its real-world application.
This is a very powerful and compact feature that explicitly or implicitly calls functions that the language model thinks it has already learned. For example, the phrase "translate french to English" is superimposed on a list of all possible French-to-English mappings.
Task specification by demonstration
Unlike fine-tuning, few-shot is processed as a whole and is not necessarily interpreted as parallel and independent.
Task specification by memetic
The proxies or analogies used in human communication can be very complex or subtle, with memetic concepts such as personality or trait situations used as proxies for intent.
For example, instead of thinking of an answer to a moral question, one could ask Mahatma Gandhi, Ayn Rand, or Yudkowsky; since GPT-3 is well suited for embedding narrative context, one can also use the freedom of the narrative to further create action. Another example of an effective proxy is a dialogue between a teacher and a student.
Prompt programming as constraining behavior
The reason GPT-3 fails is this: the probability distribution generated in response to a Prompt is not a distribution of how one person would continue the Prompt, but a distribution of how any person could continue that Prompt. A contextually ambiguous Prompt could be continued in an inconsistent way, and various people could have continued it by imagining a plausible context. For example, this is the case.
Translate French to English: My body is a transformer of the self, but also a transformer for this wax of language.
It is expected to translate from French to English, but it is possible that French sentences following this input sentence will be returned.
Serializing reasoning for closed-ended questions
For tasks that require inference, it is important that Prompt directs the computation of the language model.
Some tasks may be too difficult to compute in a single pass, but it is reasonable to expect that they can be solved by breaking them up into individually tractable subtasks. In the case of humans, the computation may be done on notepaper, but even language models such as GPT-3 need to make use of scratch space.
Metaprompt programming
The biggest drawback of Prompt programming is that it is difficult to design a Prompt for a particular task, and there is no automatic way to do it; a Metaprompt is a seemingly harmless fragment with a short phrase like "This problem asks us to".
This sets up a description of the steps to be taken to solve the problem by asking for a description of the intent of the problem. Alternatively, it can take the form of a fill-in-the-blank where the model allows you to enter details specific to the problem.
Summary
This research calls for future research in the creation of Prompt programming theory and methods. We are entering a new paradigm of human-computer interaction where programming can be done using natural language.
A text-based game is a possible evaluation method for a language model as large and with a variety of functions as GPT-3. Because sophisticated language models have the ability to describe models of virtual worlds, they can be used to model the world and test complex features of agents, such as problem-solving, information gathering, and social intelligence (including deception).



Categories related to this article






