
Named Entity Recognition With A Domain With No Annotated Data!
Three main points
✔️ Eigenexpression recognition in domains without datasets labeled by weakly supervised learning methods
✔️ Labeling of out-of-domain datasets with multiple labeling functions and hidden Markov models
✔️ 7% performance improvement over the traditional model of out-of-domain eigenrepresentation recognition in two datasets
Named Entity Recognition without Labelled Data: A Weak Supervision Approach
written by Pierre Lison,Aliaksandr Hubin,Jeremy Barnes,Samia Touileb
(Submitted on 30 Apr 2020)
Comments: Published by ACL 2020
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG); Machine Learning (stat.ML)
Introduction.
Named Entity Recognition (NER) is a task to extract eigenexpressions such as names of people, places and dates from a text. It uses models to label each word in the text as a person <PERSON> or a date <DATE>. Words that are not proper expressions are labeled with an <O> to represent them. This task is one of the elements of various tasks such as
- machine translation
- dialogue model
- Question Answering
- information extraction
- document anonymization
Although eigenrepresentation recognition is such an important task, it is known that its performance can deteriorate rapidly if the target domain is different from the source domain. On the other hand, if there is training data that matches the target domain, transfer learning is effective for eigenrepresentation recognition as well. Therefore, in this article, we introduce a method for automatically labeling a target text when there is no training data for the target domain. Roughly speaking, we can label the target text automatically in the following two steps.
- Label the text with multiple labeling functions
- Aggregating disparately labeled data into one with a hidden Markov model
And by training the model with this aggregated data, we can perform eigenrepresentation recognition on text in domains for which there is no training data.
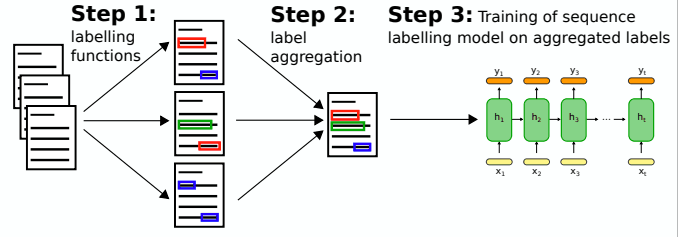
The method I'm introducing here is available on GitHub as open source.
https://github.com/NorskRegnesentral/weak-supervision-for-NER
To read more,
Please register with AI-SCHOLAR.
OR


Categories related to this article






