
TwiBot-22, A Large Graph-based Dataset For Detecting Twitter Bot Users, Is Now Available!
3 main points
✔️ Created TwiBot-22, a graph-based Twitter bot detection benchmark with annotation quality far superior to existing datasets
✔️ 35 representative baseline models for 9 datasets including TwiBot-22Re-implemented and re-evaluated using
✔️ Comparison experiments with all existing datasets and baseline models demonstrate that TwiBot-22 can serve as a comprehensive evaluation benchmark
TwiBot-22: Towards Graph-Based Twitter Bot Detection
written by Shangbin Feng, Zhaoxuan Tan, Herun Wan, Ningnan Wang, Zilong Chen, Binchi Zhang, Qinghua Zheng, Wenqian Zhang, Zhenyu Lei, Shujie Yang, Xinshun Feng, Qingyue Zhang, Hongrui Wang, Yuhan Liu, Yuyang Bai, Heng Wang, Zijian Cai, Yanbo Wang, Lijing Zheng, Zihan Ma, Jundong Li, Minnan Luo
(Submitted on 9 Jun 2022 (v1), last revised 12 Feb 2023 (this version, v6))
Comments: NeurIPS 2022, Datasets and Benchmarks Track
Subjects: Social and Information Networks (cs.SI); Artificial Intelligence (cs.AI)
code:

The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction.
Twitter bot detection is a task that detects bot accounts (automated users) within Twitter and is noted for detecting fake news and keeping online communication safe.
Modern detection methods generally utilize the graph structure of the Twitter network, which allows them to perform well even for new Twitter bots that are not in the training data and cannot be detected by conventional methods.
However, very few of the existing datasets used for Twitter bot detection are graph-based, and the few existing datasets have problems such as limited data size, incomplete graph structure, and low annotation quality, thus the lack of a large The lack of graph base has hindered the development and evaluation of graph-based bot detection models.
This paper addresses these issues by describing a comprehensive graph-based Twitter bot detection benchmark, TwiBot-22, which has much better annotation quality than existing datasets and provides various graph structures on the Twitter network This paper describes the proposed
Twitter bot detection
The negative impact of Twitter bots on society, as seen in fake news, interference in elections, and the spread of conspiracy theories, has been growing in scale over the years. These social problems have led to the development of models to prevent the negative effects of Twitter bots.
Existing Twitter bot detection models are generally feature-based, and methods were proposed to extract numerical features from user information such as metadata, user timelines, and follow relationships.
Subsequently, researchers have also proposed text-based approaches, where text analysis methods such as word embedding, RNNs, and pre-trained language models have been developed to analyze the content of tweets to identify malicious intent.
However, the challenge was cited in that modern Twitter bots often copy regular tweets from real users and insert malicious content in between, making these text-based methods less effective.
Against this background and with the advent of graph neural networks, recent years have seen a focus on the development of graph-based Twitter bot detection models, which interpret users as nodes and follow relationships as edges, allowing GCN, R-GCN, RGT, and other methods to be These methods interpret users as nodes and followers as edges, allowing methods such as GCN, R-GCN, and RGT to be used for graph-based bot detection.
While these graph-based methods are superior to existing methods in addressing various challenges, such as being able to detect new Twitter bots, they are not well supported by existing datasets and specifically suffer from three problems as shown in the figure below: (a) limited dataset structure,(b) incomplete graph structure, and(c) low annotation quality.
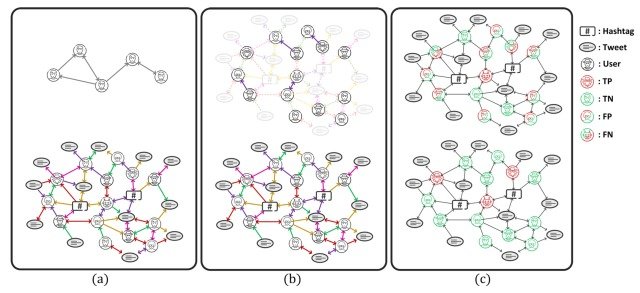
To solve these problems, this paper proposed TwiBot-22, a large graph-based dataset.
TwiBot-22
A common problem with existing datasets was that the dataset included only a few types of bots, whereas, in the real world of Twitter, there are a wide variety of users and bots simultaneously.
To solve these problems, TwiBot-22 employs a breadth-first search for user collection, which augments the obtained users with diversity-aware sampling to include various types of users and bots. This allows us to include various types of users and bots.
This makes TwiBot-22 five times larger than the largest existing dataset, containing 92,932,326 nodes (users) and 170,185,937 edges (follow relationships).
We then asked bot detection experts to annotate 1000 randomly selected users from TwiBot-22 and then annotated all data with an automatic annotation model using the resulting data.
A comparison of TwiBot-22 and existing data sets is shown in the figure below.
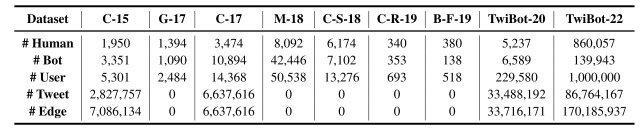
Thus, it can be seen that TwiBot-22 consists of a very large and diverse set of users and bots compared to the existing dataset.
Experiments
In this paper, we reimplemented 35 baseline methods for the nine datasets compared in the table above, including TwiBot-22, and conducted comparative experiments as shown in the figure below.
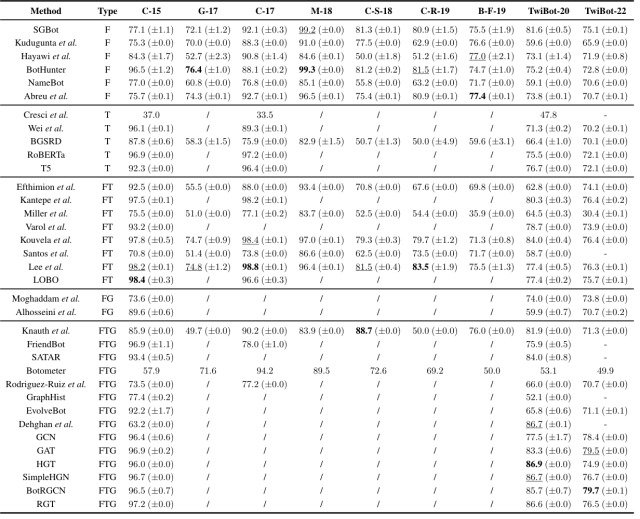
The findings of this comparative experiment can be summarized as follows
- Graph-based approaches are generally more effective than feature-based or text-based methods, and indeed the top five models for TwiBot-20 and TwiBot-22 are all graph-based methods
- While most existing datasets do not include a graph structure of Twitter users to support graph-based approaches, TwiBot-22 supports all baseline methods and serves as a comprehensive evaluation benchmark
- Accuracy for TwiBot-22 was on average 4.8% lower than TwiBot-20 for all baseline methods, indicating that Twitter bot detection is a task that needs further study
Especially for the third finding, the author points out that the bot detection model also needs to be constantly improved to detect them, since Twitter bots are constantly evading detection through technical improvements.
summary
How was it? In this article, we introduced a paper that proposed TwiBot-22, a new large-scale dataset for graph-based Twitter bot detection.
Comprehensive comparative experiments involving TwiBot-22 have demonstrated that this dataset is a valid evaluation benchmark, but the following issues remain unresolved in the Twitter bot detection task
- How to identify bot clusters? (New Twitter bots have been observed to act in groups and cooperate with each other to form clusters)
- How to incorporate multimodal user features to improve detection accuracy?
- How to evaluate the generalization capability of a model?
The author has stated that he will focus on solving these problems based on the TwiBot-22, and it will be interesting to see what happens in the future.
The details of the dataset and baseline model architecture presented here can be found in this paper for those interested.



Categories related to this article
