
テキスト・音声・視覚からマルチモーダルに感情を認識: Sonyが提案したM2FNet!
3つの要点
✔️ テキスト・音声・動画の特徴を活用した感情認識で高精度を達成!
✔️ Transformerにより発話間の関係を、Multi-Head Attentionによりモダリティ間の関係を学習!
✔️ 動画特徴では"表情"だけでなく"シーン全体"のコンテクストを利用する必要性を示した
M2FNet: Multi-modal Fusion Network for Emotion Recognition in Conversation
written by Vishal Chudasama, Purbayan Kar, Ashish Gudmalwar, Nirmesh Shah, Pankaj Wasnik, Naoyuki Onoe
(Submitted on 5 Jun 2022)
Comments: Accepted for publication in the 5th Multimodal Learning and Applications (MULA) Workshop at CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Sound (cs.SD); Audio and Speech Processing (eess.AS)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに

上の図はMELD・IEMOCAP両データセットの感情認識における既存手法と今回紹介するM2FNetの精度(weighted average F1)です。既存手法はデータによって精度の偏りがある一方で提案手法は両データセットで高い精度を維持しています。
今回紹介するのは会話における感情認識(Emotion Recognition in Conversations: ERC)タスクのモデルM2FNet(Multi-modal Fusion Network)です。ERCではテキストデータのみを扱う手法が多く、マルチモーダルな手法は困難とされてきました。それに対してM2FNetは見事3つのモダリティの有用な特徴を活かした高精度な推定を可能にし、2つの主なERCデータセットで共にSoTAを達成しました。主な貢献は次の通りです。
- 表情特徴だけでなくシーン全体の特徴から複数の人物を考慮することで動画からより有用な特徴を抽出した
- 音声・動画から有益な特徴を抽出するために適応的マージンを用いたTriplet Lossを提案した
- Multi-Head Attentionに基づく特徴の融合により、音声・視覚の感情に関わる有益な情報をテキスト特徴にマッピングさせた
- MELD・IEMOCAPベンチマークのweighted average F1 Scoreが最高精度を達成し、提案手法の頑健性を示した
それではM2FNetを見ていきましょう。
ERCとは
ERCは会話における人間の感情をテキスト・シーン・音声を基に認識するタスクで、マルチメディアのコンテンツの解析やモデリングへの応用が期待されています。コンテンツに対するユーザの反応や、ユーザ一人一人に最適化された対話システム、AIによるインタビュー、センチメント分析など応用の幅は大きいです。
会話における感情認識データは下図のようなものになります。二人の人物の会話それぞれに対してText・Vision・Acousticsの3つのモダリティのデータが存在し、それらに対して1つのEmotion(感情ラベル)が割り当てられています。ERCはこの感情ラベルを推定するタスクです。

体系的位置付け
従来のERC手法は主に会話中のテキスト情報を利用することに重点を置いており、他2つのモダリティは無視されがちです。これでは音声や視覚情報を考慮できていないため感情の解析が限定的になってしまします。またIEMOCAPでは高精度でも、より複雑なMELDでは精度が下がるなど頑健性にも問題があります。ERCデータはテキスト・動画・音声の3つのモダリティで構成されるため、それを活かさない手はありません。本論文はマルチモーダルなアプローチを用いることで感情認識の精度を向上させることができるというモチベーションでモデルを提案しています。マルチモーダルなアプローチは既存手法にもありますが、本論文ではよりモダリティ毎の特徴を上手く抽出・結合させるため、いくつかの機構を提案しています。
全体像
まずはM2FNetの全体像を示します。

3つのモダリティなだけあって複雑に見えますが、1つ1つ見ていけば理解できます。
扱うデータは発話集合Uと各発話に対する感情ラベルYで構成されます。U中の各データxiは3つのモダリティ(text・audio・video)で構成され、1つの発話xiに対して感情ラベルyiが与えられます。1つのDialogはk個の発話で構成されます。
![]()
本モデルは大きく2つのステージに分かれています。前半のUtterance Levelでは各発話毎(Intra-Speaker)各モダリティ毎独立して特徴抽出を行います。後半のDialog Levelでは抽出した各発話間(Inter-Speaker)の特徴を抽出し、文脈情報を掴みます。その後モダリティ間の関係性を抽出し、最終的な感情ラベルの推定を行います。
Utterance Level Feature Extraction
Dialog-levelに渡す前に、まずUtterance Levelで各発話・各モダリティに対する特徴を個別に抽出します。テキスト・音声・動画毎個別に説明していきます。音声・動画が重要です。

テキスト特徴
テキスト特徴は大規模自然言語モデルであるmodified RoBERTaをfine-tuningさせて抽出します。テキストについては厳密には各発話毎ではなく、Separateトークン<S>で区切った前後の発話も含めて入力させます。得られるテキスト特徴はDT次元です。
![]()
Feature Extractor Module
音声・動画特徴の抽出には既存のモデルではなく独自のモデルを用います。適応的マージンを用いたTriplet Lossによる学習機構です。
 この機構はFaceNetという顔認識モデルのTriplet Lossを参考にしてします。得たいのは各人の様々な表情やシーン・音声を識別できる特徴です。まずはある画像特徴(Anchor)と同じラベルのサンプル(Positive)集合、異なるラベルのサンプル(Negative)集合を用意します。Triplet Lossはこの時Positive Samplesが特徴空間上で近く、Negative Samplesが遠くなるように学習させます。ERCでは同じ感情ラベルのサンプルを近づけ、それ以外を遠ざけることで有用な特徴を得ます。EncoderはResNet18、Projectorは全結合層で構成され、最終的にd次元の特徴量が得られます。提案手法のTriplet Lossは式の通りです。
この機構はFaceNetという顔認識モデルのTriplet Lossを参考にしてします。得たいのは各人の様々な表情やシーン・音声を識別できる特徴です。まずはある画像特徴(Anchor)と同じラベルのサンプル(Positive)集合、異なるラベルのサンプル(Negative)集合を用意します。Triplet Lossはこの時Positive Samplesが特徴空間上で近く、Negative Samplesが遠くなるように学習させます。ERCでは同じ感情ラベルのサンプルを近づけ、それ以外を遠ざけることで有用な特徴を得ます。EncoderはResNet18、Projectorは全結合層で構成され、最終的にd次元の特徴量が得られます。提案手法のTriplet Lossは式の通りです。
![]()
1項目はAdaptive MarginによるTriplet Loss、2項目は特徴量の分散項、3項目は共分散項、λはそれぞれの重みです。
Triplet Lossは膨大なサンプル集合から特に学習に有用なサンプルを厳選します。学習に適しているのはAnchorとPositiveとの距離DapがNegativeとの距離Danより大きいDap-Dan>0のサンプル(Hard)です。最初からDapの方が明らかに小さい場合は最適化の意味があまりありません。この時Triplet Lossはある程度のマージンmを設け、Dap-Dan-m>0であればそれも学習させます(Semi-Hard)。しかしFaceNetではマージンに固定の値を持たせているため、PositiveとNegativeがAnchorから同じような距離にあるような場合はロスが0に近くなり学習が進みません。そこでM2FNetでは特徴量の距離に応じた適応的なマージンを用いたAdaptive Margin-based Triplet Lossを提案しています。
![]()
適応的マージンは次のように特徴間の距離に基づく類似度・非類似度から決定させます。これにより、音声・動画から感情ラベルに関連した特徴をより柔軟に学習することができます。
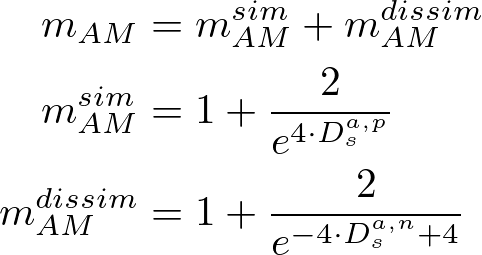
2項目はモード崩壊を防ぐための分散項、3項目は次元同士の相関を下げるための共分散項です。
%3B%5C%3BZ_k%3DZ_a%2CZ_p%2CZ_n%5C%3B%5Cleft(L_%7BVar%7D(Z_k)%3D%5Cfrac%7B1%7D%7Bd%7D%5Csum_%7Bj%3D1%7D%5Ed%201-%5Csqrt%7BVar(Z_%7B%3A%2Cj%7D)%2B%5Cepsilon%7D%5Cright)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
%3B%5C%3BZ_k%3DZ_a%2CZ_p%2CZ_n%5C%3B%5Cleft(L_%7BCov%7D(Z_k)%3D%5Cfrac%7B1%7D%7Bd%7D%5Csum_%7Bi%5Cneq%20j%7D%20Cov(Z_%7Bk%7D)_%7Bi%2Cj%7D%5ET%5Cright)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
音声と動画では少し扱いが違うので細かく見ていきましょう。
音声特徴
2021年のICCVの論文で音声データによる感情認識では信号そのものを扱うのではなく周波数特性をプロットしたメルスペクトログラムを画像とした扱った方が精度が高いことが示されました。これに触発され、M2FNetでも音声を画像として扱い特徴抽出しています。まずタイムワープやAdditive White Gaussian Noise(AWGN)を適用した上でメルスペクトログラムに変換します。
メルスペクトログラムは、局所的な時間窓を設けその窓毎に短時間フーリエ変換(STFT)を適用することで、横軸に時間・縦軸に周波数をRGBでプロットした特徴量です。これを先ほどの特徴抽出器に通し、発話i毎の音声特徴を得ます。DAは得られた音声特徴の次元です。
![]()
動画特徴
動画特徴は、各発話に該当する動画の各フレームから特徴抽出・フレーム間で結合させることで得ます。M2FNetでは感情に関連した特徴をより抽出できるよう、人物の表情だけでなくフレーム全体の特徴も利用してコンテクストをつかむDual Networkを提案しています。

まず表情特徴(Weighted Face Model)です。発話iに対応する連続した15フレームについて、まず各フレーム毎Multi-task Cascaded Convolutional Network(MTCNN)に入力し顔を検出します。検出された顔は複数あるため、先述した特徴抽出器で得られた各表情特徴の重み付き和を特徴量とします。この時の重みにはbboxの面積を用います。面積を正規化して[0,1]の範囲に抑えて重みとすることで、各フレームで強調されている表情をより重視します。論文にはありませんが敢えて式にすると次のようになります。15フレームの表情特徴にMax-poolingを通すことで各発話iの表情特徴になります。
%3D%5Csum_%7Bj%5Cin%20%5Cmathrm%7BMTCNN%7D(x_v%5Ei)%7D%20%5Cmathrm%7BFaceModel%7D(x_%7Bvj%7D%5Ei)%5Ccdot%20%5Cmathrm%7BArea%7D(x_%7Bvj%7D%5Ei)_%7B%5Cmathrm%7Bnormalized%7D%7D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f) 続いてシーン特徴(Scene Embedding)です。シーン特徴は単純で、各フレームを特徴抽出器に通した15フレームをMax-Poolingで圧縮します。この2つのネットワークにより得られた特徴を結合することで最終的な動画特徴となります。従って敢えて式にする場合は次のようになります。
続いてシーン特徴(Scene Embedding)です。シーン特徴は単純で、各フレームを特徴抽出器に通した15フレームをMax-Poolingで圧縮します。この2つのネットワークにより得られた特徴を結合することで最終的な動画特徴となります。従って敢えて式にする場合は次のようになります。
![\begin{align*}
F_{IV}^i=\mathrm{Concat}\left(
&\mathrm{Maxpool_{15frames}}(\phi_{Scene}(x_v^i)),\\
&\mathrm{Maxpool_{15frames}}(\phi_{WF}(x_v^i))
\right)\;|\;i\in[1,k],\; \forall F_{IV}\in\mathbb{R}^{k\cdot D_v}
\end{align*}](https://texclip.marutank.net/render.php/texclip20221227205222.png?s=%5Cbegin%7Balign*%7D%0A%20%20%20%20F_%7BIV%7D%5Ei%3D%5Cmathrm%7BConcat%7D%5Cleft(%0A%20%20%20%20%26%5Cmathrm%7BMaxpool_%7B15frames%7D%7D(%5Cphi_%7BScene%7D(x_v%5Ei))%2C%5C%5C%0A%20%20%20%20%26%5Cmathrm%7BMaxpool_%7B15frames%7D%7D(%5Cphi_%7BWF%7D(x_v%5Ei))%0A%20%20%20%20%5Cright)%5C%3B%7C%5C%3Bi%5Cin%5B1%2Ck%5D%2C%5C%3B%20%5Cforall%20F_%7BIV%7D%5Cin%5Cmathbb%7BR%7D%5E%7Bk%5Ccdot%20D_v%7D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
このようにして得た各発話i毎のテキスト・音声・動画特徴を今度はDialog Levelの特徴抽出器に用いていきます。
Dialog Level Feature Extraction
ここからはDialog単位で、つまりk個の発話間の関係を抽出していきます。
発話間の関係の学習
まずはモダリティ毎に発話間の関係を学習します。モダリティ毎のk・D次元の特徴FIT、FIA、FIVを複数のTransformer Encoderに入力します。
 低レベルの特徴を無視しないためにTransformer間はskip-connectionで接続させます。論文では下の式のように記述しています。
低レベルの特徴を無視しないためにTransformer間はskip-connectionで接続させます。論文では下の式のように記述しています。
![\begin{align*}
F_T^i=Tr_{N_T}(...(Tr_{N_2}(Tr_{N_1}(F_{IT}^i)))),\\
F_A^i=Tr_{N_A}(...(Tr_{N_2}(Tr_{N_1}(F_{IA}^i)))),\\
F_V^i=Tr_{N_V}(...(Tr_{N_2}(Tr_{N_1}(F_{IV}^i)))),\\
\mathrm{where},\;i\in[1,k]
\end{align*}](https://texclip.marutank.net/render.php/texclip20221227210826.png?s=%5Cbegin%7Balign*%7D%0A%20%20%20%20F_T%5Ei%3DTr_%7BN_T%7D(...(Tr_%7BN_2%7D(Tr_%7BN_1%7D(F_%7BIT%7D%5Ei))))%2C%5C%5C%0A%20%20%20%20F_A%5Ei%3DTr_%7BN_A%7D(...(Tr_%7BN_2%7D(Tr_%7BN_1%7D(F_%7BIA%7D%5Ei))))%2C%5C%5C%0A%20%20%20%20F_V%5Ei%3DTr_%7BN_V%7D(...(Tr_%7BN_2%7D(Tr_%7BN_1%7D(F_%7BIV%7D%5Ei))))%2C%5C%5C%0A%20%20%20%20%5Cmathrm%7Bwhere%7D%2C%5C%3Bi%5Cin%5B1%2Ck%5D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
モダリティ間の関係の学習・結合
続いてDialog Levelの特徴に対して、モダリティ間の関係性を抽出し、結合させます。まず3つの特徴量をMulti-Head Attentionで構成されたFusion Attention Moduleに入力します。ここではテキスト特徴FtをQuery/Value、動画特徴Fvと音声特徴FaをKeyとすることでテキスト特徴空間に動画特徴と音声特徴をマッピングさせます。Ftは前の層の特徴を用いていますが、Fv・Faは変化していない点に注意してください。
最後に、マッピングしたテキスト特徴とFv・Faを結合することで、先ほどの関係性の抽出とは別に直接動画・音声の特徴を用います。これにより最終的な発話全体且つモダリティ全体の特徴量が得られます。

最後は2層の全結合層を通すことでついに感情ラベルが出力されます。損失はクロスエントロピーです。M個のダイアログ毎k個の発話があり、C個の感情ラベルから1つの感情が割り当てられている場合の想定です。
%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
実験
実験ではERCのベンチマークとしてMELD・IEMOCAPを用いてアブレーションやSoTAとの比較をおこなっています。共にテキスト・動画・音声データで構成されるマルチモーダルデータセットです。
データセット
MELDはTVシリーズ「Friends」の1,400以上の会話と13,000の発話で構成されます。発話には7つの感情ラベルanger, disgust, sadness, joy, surprise, fear, neutralのうち1つが付与されています。あらかじめ用意されているTrain/Validをそのまま用います。
IEMOCAPは約12時間の会話データベースです。6つの感情ラベルhappy, sad, neutral, angry, excited, frustratedが存在し、実験では学習データからランダムに10%選択したデータをハイパーパラメータのチューニングに用いています。
設定
学習にはAdamWを用いています。特に言及がない限り、Dialog LevelのTransformer Encoderの数NT・NA・NVは経験的にMELDでは1、IEMOCAPでは5、MHAF層の数mは共に5と設定しています。
特徴抽出器は音声データの機構はデータセット毎メルスペクトログラムで学習させ、動画データについては別にCASIA webface databaseという顔認識データセットで事前学習させています。細かな学習設定は論文を参照してください。Triplet Lossの係数λ1、λ2、λ3は音声データも動画データも共に20、5、1としています。
評価指標
推定された感情ラベルのAccuracyとweighted average F1 Scoreを用いています。
アブレーション
アブレーションではマルチモダリティやTransformer Encoder、Fusionの寄与を検証しています。まずはモダリティです。下の表はText・Visual・Audioの3つのモダリティについて、1つのみ、2つを結合、3つを結合したものを用いた時の精度を示しています。特に一番下は単なる結合ではなく提案手法の一部であるFusion Attention Moduleを用いたものです。表の通り、3つ全てのモダリティを用いた時の方が精度が良く、更に提案手法のFusion機構を用いることで大きく精度が向上することが分かります。

続いては動画特徴です。動画特徴だけシーンの特徴と表情特徴を用いるやや複雑な機構をとっていたので、アブレーションではこのDual Networkの有効性を確かめています。シーンの特徴のみ、表情特徴のみ、そして両方を結合させた提案手法の3つの比較では表の通り、提案手法が最も精度が高い結果が得られました。各埋め込み単体では精度が向上しないことを見ると、シーンからの文脈情報と表情特徴の両方が感情認識では重要であることが分かります。

Fusion前のTransformer Encoderの数もNA=NV=NTの中で検証しています。その結果MELDでは1層、IEMOCAPでは5層を採用する場合が高精度であることが分かりました。

最後はFusion機構の数mの検証です。ここは5層を採用した時が最も精度が良いことが分かります。特に言及がない限りはこれらのパラメータはアブレーション時の最高精度で設定されています。

SoTAとの比較
論文ではM2FNetを、テキストベースのSoTAモデルやマルチモーダルのSoTAモデルと比較させ、その優位性を実証しています。まずはテキストベースのモデルです。両データセットで従来手法に優れており、MELDでは従来のEmotionFlowより0.21%高く、IEMOCAPでは従来のDAG-ERCより1.83%高い結果となりました。IMOCAPでは精度が高くてもMELDでは精度が下がってしまう手法が多い中で提案手法はどちらも高精度を達成しています。

続いてはマルチモーダルの手法です。MELD・IEMOCAP共に従来手法より高精度な結果を出しました。特にMELDでの精度向上が著しいです。

この実験からM2FNetがマルチモダリティの特徴をうまく活用し、感情認識の精度を高めたことが分かりました。
所感
3つのモダリティを十分に活かした本手法の優位性がよくわかる論文でした。実用的にはテキストベースの方が需要が大きい気がしました。例えばSNSや口コミなどの解析ではテキスト特徴のみで精度が要求されるはずです。動画・音声・テキスト全てが揃っているデータは限られるように思いました。それでもデータさえ揃えば2つのベンチマークで高精度を達成した頑健性が発揮されるため、期待の大きい手法と感じました。
クリエイティビティを謳うソニーならではの感情認識の応用が楽しみです。
まとめ
今回は会話における感情認識ERCで高精度を達成したM2FNetを紹介しました。M2FNetはERCデータセットで用意されている3つのモダリティ音声・テキスト・動画の特徴を十分に活かすため、Utterance levelとDialog levelの2つのステージで、モダリティ毎発話毎の特徴抽出・発話間の特徴抽出・モダリティ間の特徴抽出を段階的に行います。動画特徴では表情だけでなくシーン全体の特徴も用いることが重要であることを示しました。実験ではテキストベースの手法とマルチモーダルな手法を比較し、見事2つのベンチマークでSoTAを達成しました。CVPRには補足資料もあるので是非ご覧ください。これからの発展が楽しみです。



この記事に関するカテゴリー

