【Group-CAM】Grad-CAMはもう古い?最先端のCNNにおける判断根拠手法
3つの要点
✔️ 特徴量マップのノイズを排除する機構を含む
✔️ 高速な顕著性マップの推論が可能
✔️ いくつかの実験で計算コストが少ないにも関わらずSOTAを達成
Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks
written by Qinglong Zhang, Lu Rao, Yubin Yang
(Submitted on 25 Mar 2021 (v1), last revised 19 Jun 2021 (this version, v4))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
近年深層学習ベースの画像認識モデルは自動運転や医療診断に急速取り入られていますが、ブラックボックス手法で判断根拠が分からないために重大な問題を引き起こす懸念があり、導入を躊躇っている方も多いと思います。
このような懸念を払拭するために深層学習モデルの判断根拠を説明する技術「説明可能なAI(XAI)」が近年重要度を増しています。
コンピュータビジョンで幅広く用いられるXAIが顕著性マップ(saliency map)です。これは、判断根拠となったピクセルを重要度に応じて強調するヒートマップです。例えば、学習済み画像分類モデルに以下の犬と猫の写真を入力し犬と識別したとします。このとき顕著性マップは、根拠となり重要な部分ほど赤くなっている画像となります。この画像の場合、犬の口周辺が根拠となっていることがわかります。

この分野の手法は2種類に大別することができ、今回紹介するGroup-CAMはそれぞれの欠点を克服した手法になります。
- 領域ベース手法(Region-based Saliency Methods)
- 活性化ベース手法(Activation-based Saliency Methods)
領域ベース手法(Region-based Saliency Methods)
この系統の手法は、対象となる画像を学習済みモデルにマスクを施して入力し、ピクセルやスーパーピクセルの重要度を判別します。RISEでは、無作為に作成したマスクを数千枚作成しモンテカルロ法で各ピクセルの重要度を決定します。この他の手法としてScore-CAMやXRAIがあります。
しかし、数千枚のマスク生成と推論が必要となるため、計算コストが重い問題があります。1枚の推論にRISEやXRAIでは、約40秒かかることがこの論文で報告されています。
活性化ベース手法(Activation-based Saliency Methods)
この系統の手法は、モデルのバックボーンにおける特徴量マップをもとに顕著性マップを推論します。基本的に最終層の特徴量マップが使われることが多いです。推論時の流れは、特徴量マップの各チャンネルの重みを決め重み付けしチャンネル方向に足し合わせ拡大し入力画像と組み合わせます。この系統の研究では、どのように重み付けを行うかが論点となっている場合が多いです。
よく知られている手法にGrad-CAMがあります。重みは、最終層の特徴マップに関する勾配に全平均プーリング(Global Average Pooling;GAP)を適用することで決めています。
しかし、この重みが特徴量マップの重要度を正しく評価できていない点やそもそも特徴量マップ自体がノイズを含んでしまっていて重要ではない部分も含んでしまうという問題もあります。

論文概要
今回紹介するGroup-CAMは、上で述べた次の問題を解消した手法となります。
- 領域ベース手法の計算コストが重い問題
- 活性化ベース手法のノイズを含んでしまう問題
全体のアーキテクチャは以下の通りです。
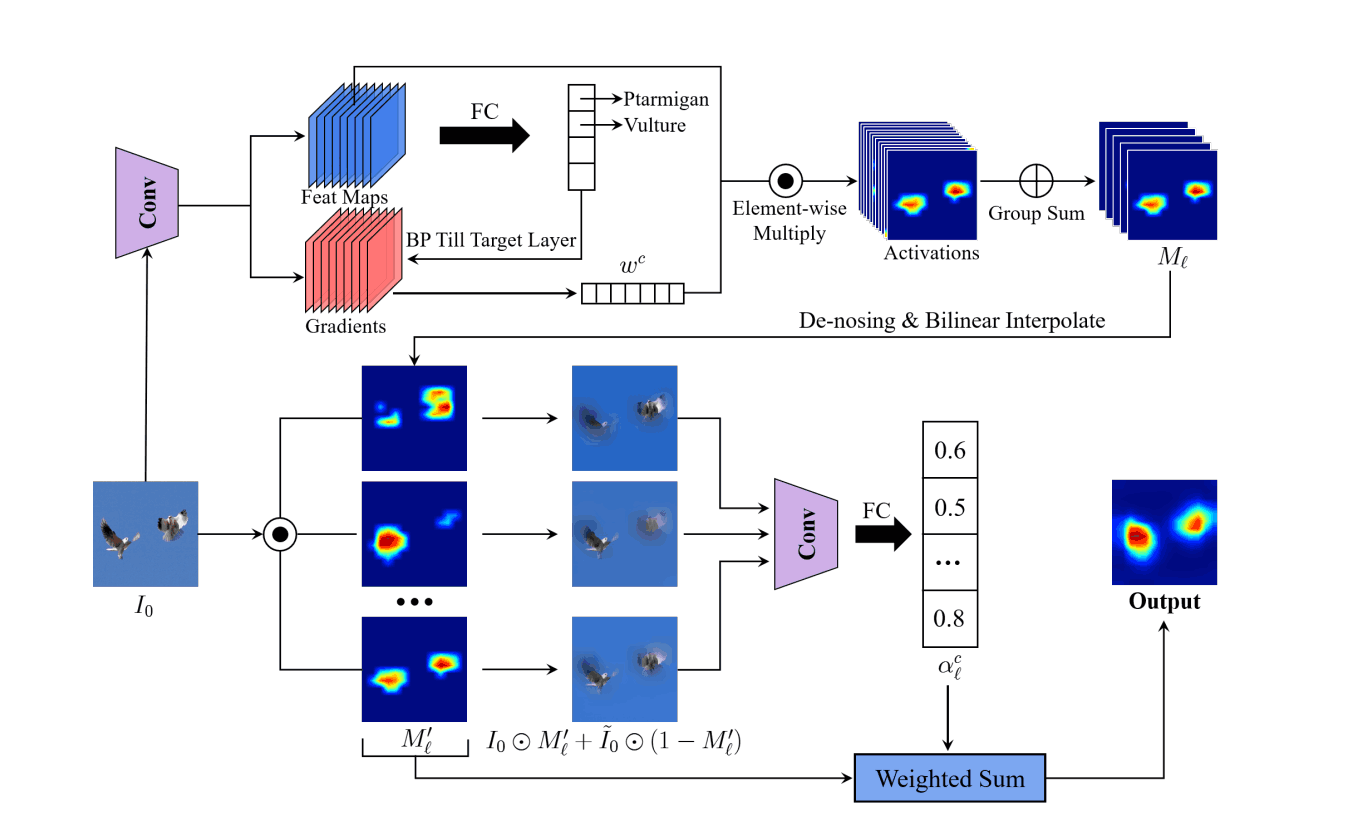
推論には3つのフェーズがあります。
- 特徴量マップの重みを決定
- 特徴量マップのノイズ除去
- グループ化した特徴量マップの重みを決定し顕著性マップを作成
Step1. 特徴量マップの重みを決定
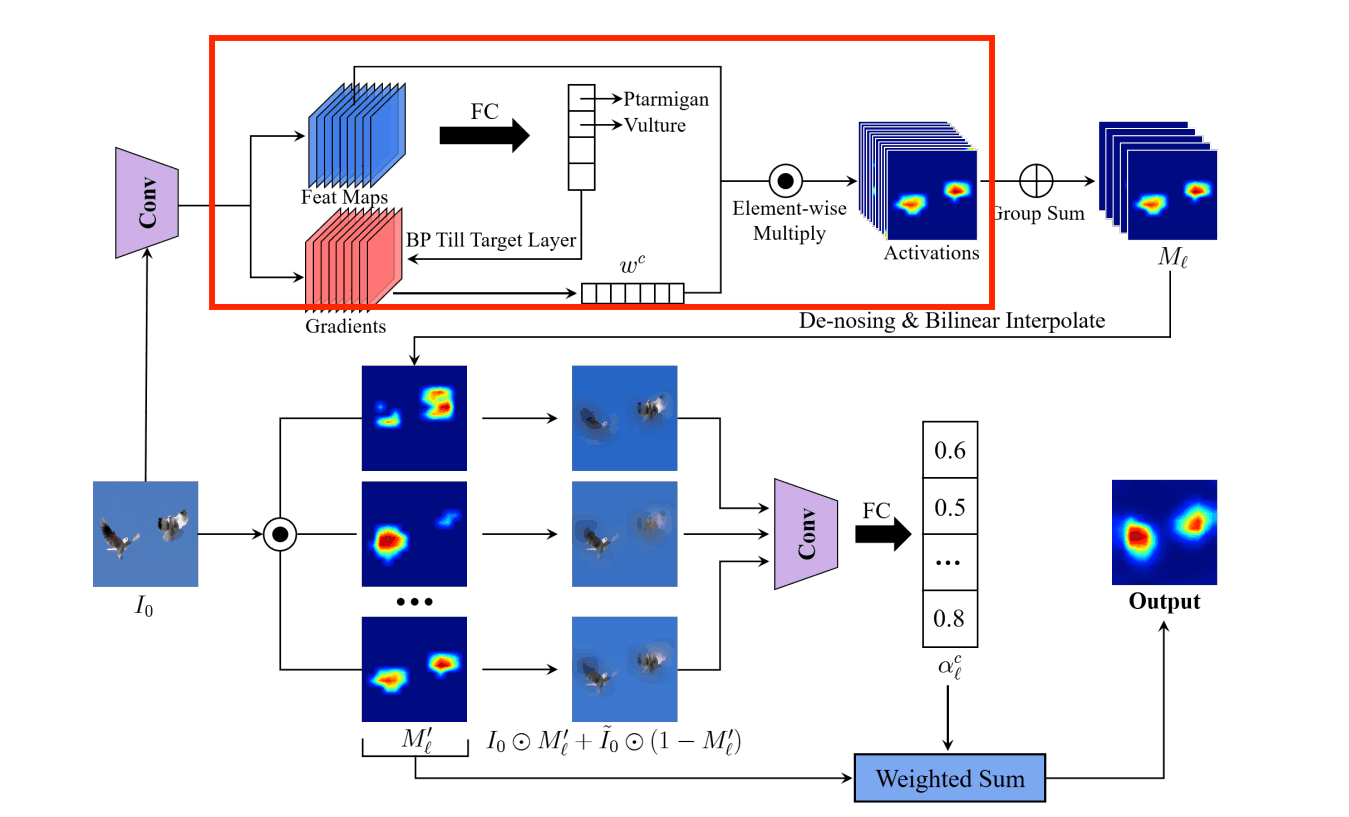
やっていることはGrad-CAMと同じです。まず、判断根拠が欲しい画像を学習済みモデルに入力し畳み込み層における特徴量マップを保持しておきます。その後、誤差逆伝播方法を用いて分類結果に対する畳み込み層の勾配を計算します。
この勾配に全平均プーリング(Global Average Pooling;GAP)を適用し、チャネル数次元の重みを計算します。k番目の畳み込み層におけるチャンネルcの重みwkcは数式で表すと次のようになります。
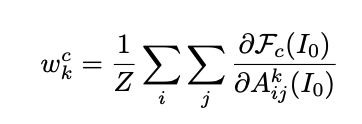
入力画像: I0
k番目の畳み込み層の特徴量マップ: Aijk
Fc(I0):クラスcの予測確率
i,j: 高さと幅
Z: Akに含まれるピクセル数
Step2. 特徴量マップのノイズ除去
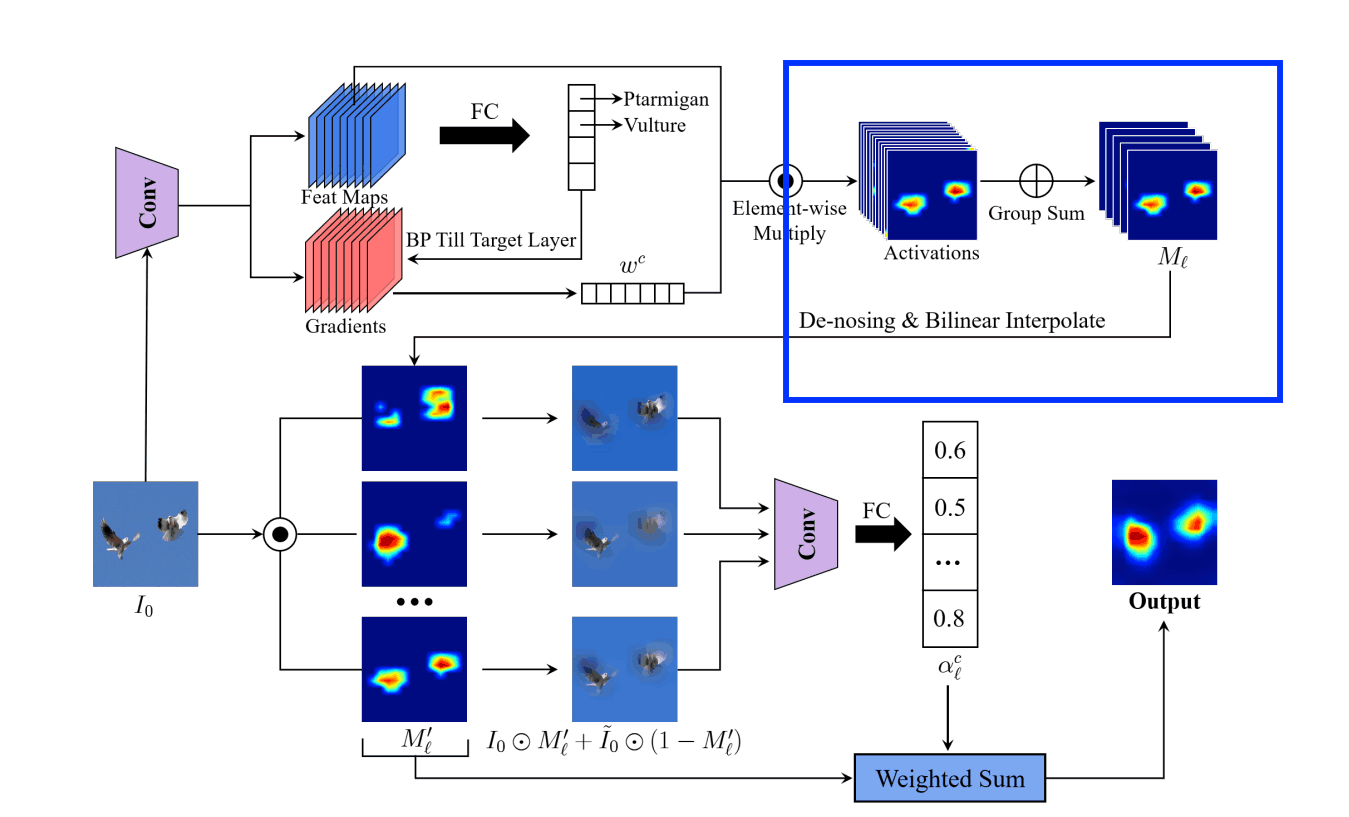
ここでは2つのことを行います。
- Step1で得られた特徴量マップをG個のグループに分け、G個の特徴量マップにまとめる
- まとめた特徴量マップのノイズを除去し正規化
Step1で得られた特徴量マップをG個のグループに分け、G個の特徴量マップにまとめる
グループの分け方はResNexTと同じように隣接する特徴量マップがまとめられます。
まとめられた特徴量Mlは次のように表されます。
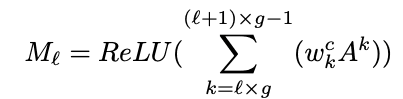
K: チャンネル数
g=K/G: グループに含まれる特徴量マップのチャンネル数
まとめた特徴量マップのノイズを除去する
下位θ%のピクセルを0にするノイズ除去を行います。
Mlのmijピクセルにノイズ除去Φを施したものは次のように表されます。
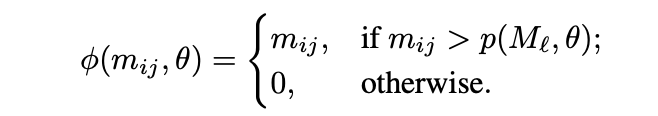
p(Ml,θ): 下位θ%のピクセルの上限
そして、[0,1]の範囲になるように正規化を行い、バイリニア補間により入力画像のサイズまで拡大します。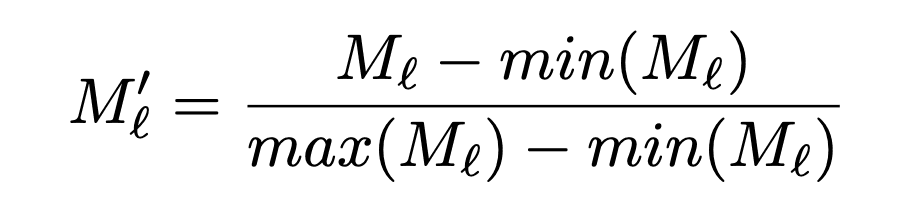
Step3. グループ化した特徴量マップの重みを決定し顕著性マップを作成
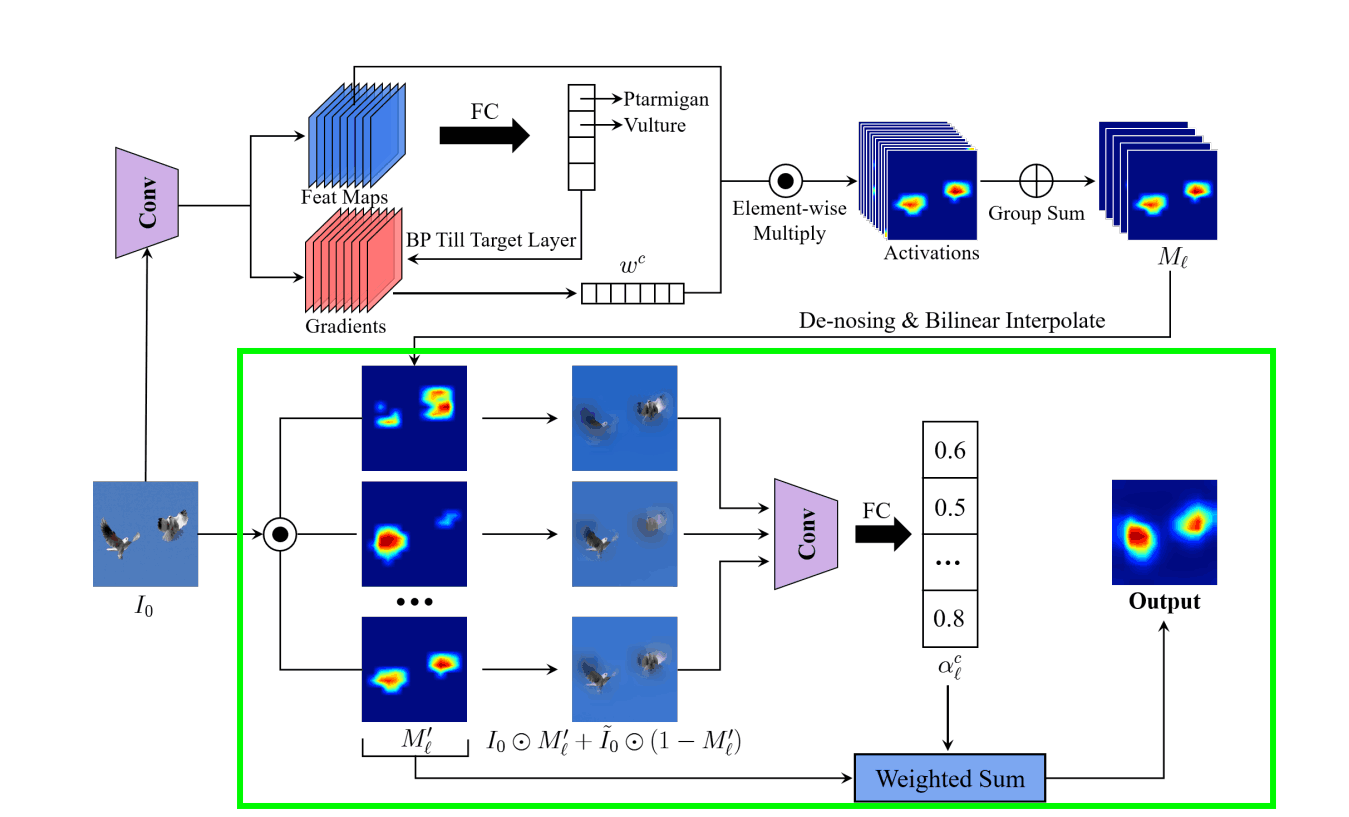
正規化した特徴量マップMl'をマスクとして元の入力画像Ioに施し、ガウシアンぼかしを施したĩoも足します。これを加える理由は、マスク化した入力画像だけだと敵対的影響が出てくる可能性があるためです。
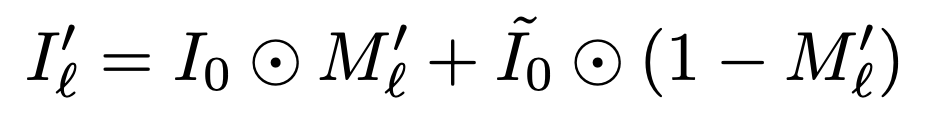
ここからやることはRISEと同じです。マスクを施した入力画像のクラスcにおける予測確率をG個分推論し、ĩoを入力したときのクラスcにおける予測確率との差を取ります。
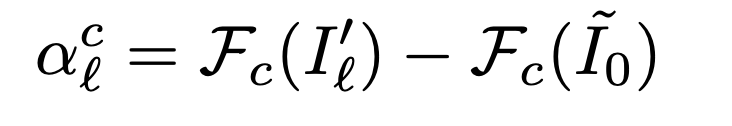
そして、l番目のまとめられた特徴量マップをalcで重み付けしヒートマップを生成します。
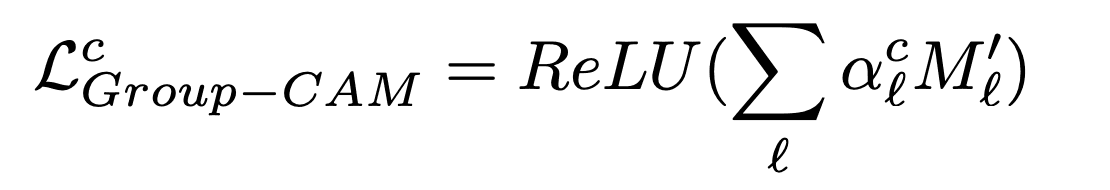
実験
クラス判別の可視化
torchvisionの学習済みモデルVGG19で46.06%の信頼度でブル・マスティフ(犬)、0.39%の信頼度でトラ猫と判別したときの判断根拠が真ん中と右の画像になります。見ての通り、トラ猫の信頼度は低いにも関わらず根拠を説明できていることが見て取れます。

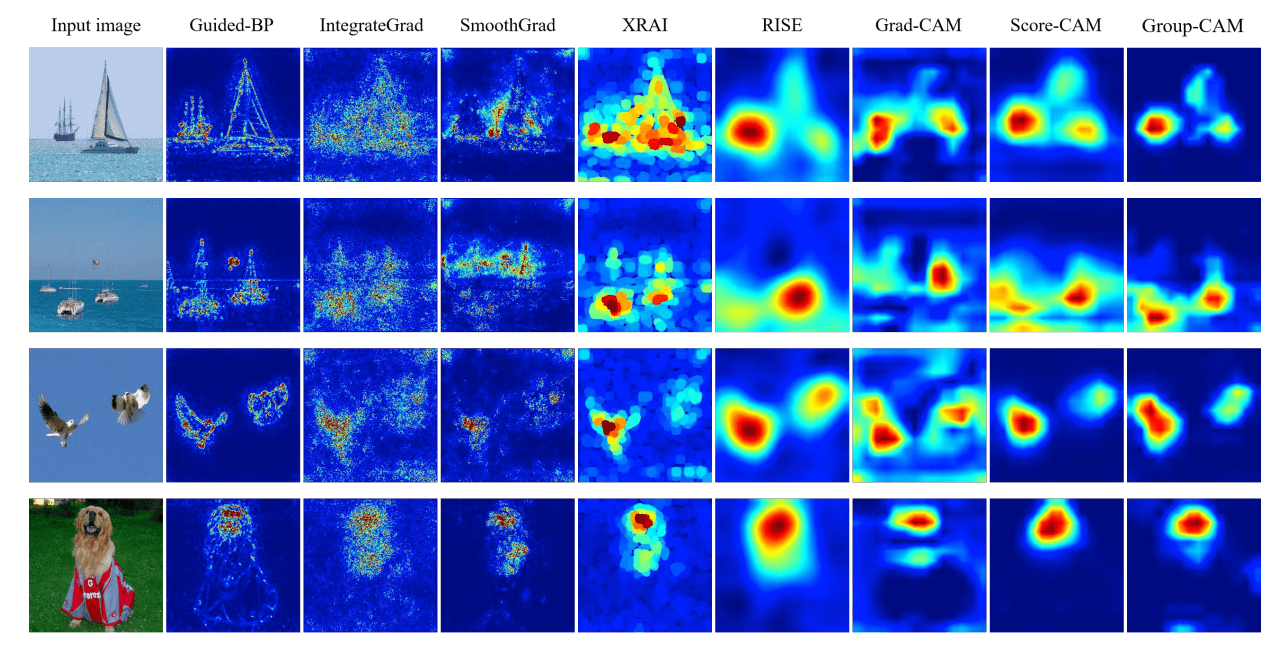
下の図は他のSOTAを達成した手法と比較したものです。Group-CAMはノイズがその他の手法に比べて少ないことがわかります。
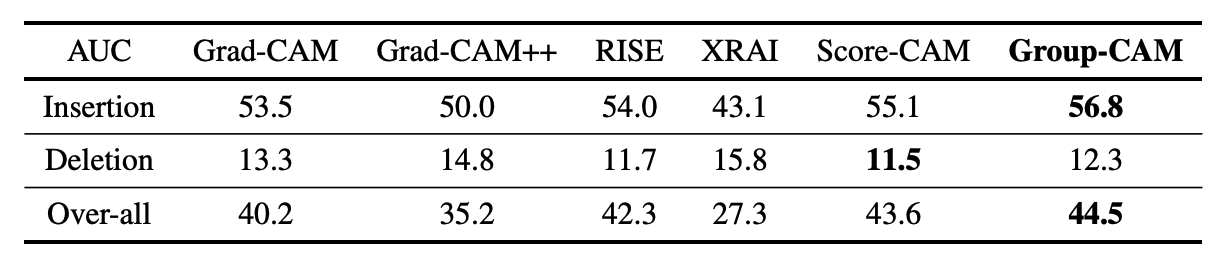
削除と挿入テスト
RISEで提案された削除と挿入テスト(Deletation and Insertion test)の結果を示します。
この手法が開発された背景は、CNNにおけるXAIは人間がアノーテーションしたバウンディングボックス上に顕著性マップの最も重要度が高い部分があれば性能が良いと考えられていましたが、CNNは背景を加味した上で識別を行なっている可能性があるため、必ずしもこれが正しいとは限らないためです。
削除テストでは、ヒートマップ上の最も重要だと考えられる部分から3.6%ずつぼかしたピクセルに置換するのを顕著性マップがなくなるまで行い、縦軸をクラスの予測確率としたグラフの面積(AUC: Area Under Curve)を指標として使います。
挿入テストでは、逆にぼかした画像に3.6%ずつ元の画像を顕著性マップの重要度に応じて足して行き、縦軸をクラスの予測確率としたグラフの面積(AUC: Area Under Curve)を指標として使います。
削除テストでは、急激に予測確率が落ちた方が重要な判断根拠と考えられるためAUCが低い方が良く、挿入テストでは、急激に予測確率が上がった方が重要な判断根拠と考えられるためAUCが高い方が良いと考えられています。
見ての通り、全体でGroup-CAMが最も良い結果となっています。全体の評価値は、AUC(Insertion) - AUC(Deletion)で計算されています。
検出評価
データセットMS COCO2017のval2017上で学習済みモデルResnet-50を用いて評価を行います。評価の仕方は、物体のバウンディングボックス上に顕著なピクセルが存在すればHitとして扱い、全てのカテゴリについて平均した値をパフォーマンス値としています。
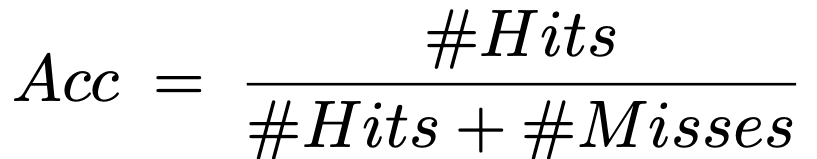
実験では、Grad-CAMより0.8%高い結果を得られています。 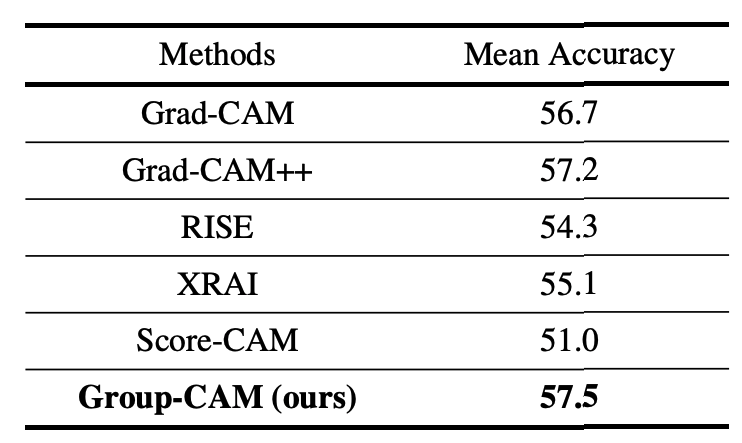
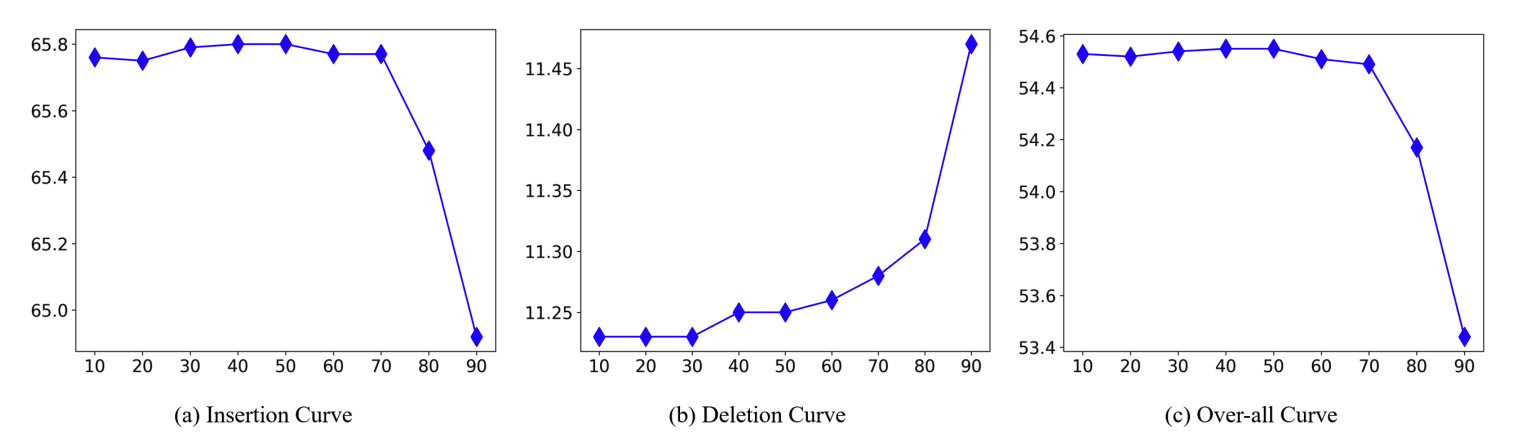
ノイズ除去ハイパーパラメータθ
θが70以下の場合は一定で70以上になると急にAUCが下がることがわかりました。
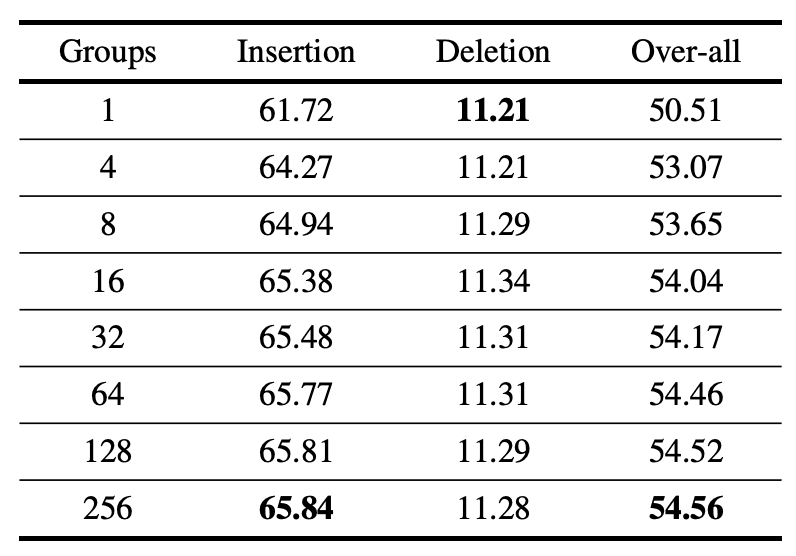
グループ数G
Gは増やせば増やすほど全体のAUC値が上がることが分かりました。しかし、Gを上げれば計算コストがあがってしまうため、実験では32を採用しています。
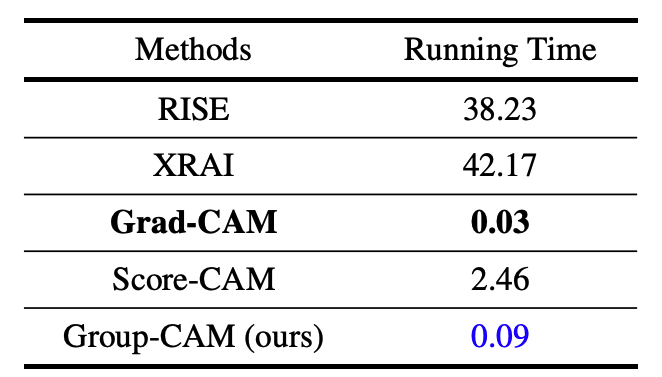
実行時間
NVIDIA 2080Ti GPUで動かした結果が以下の通りです。Grad-CAMとGroup-CAMは0.1秒以下と高速に実行できることがわかります。
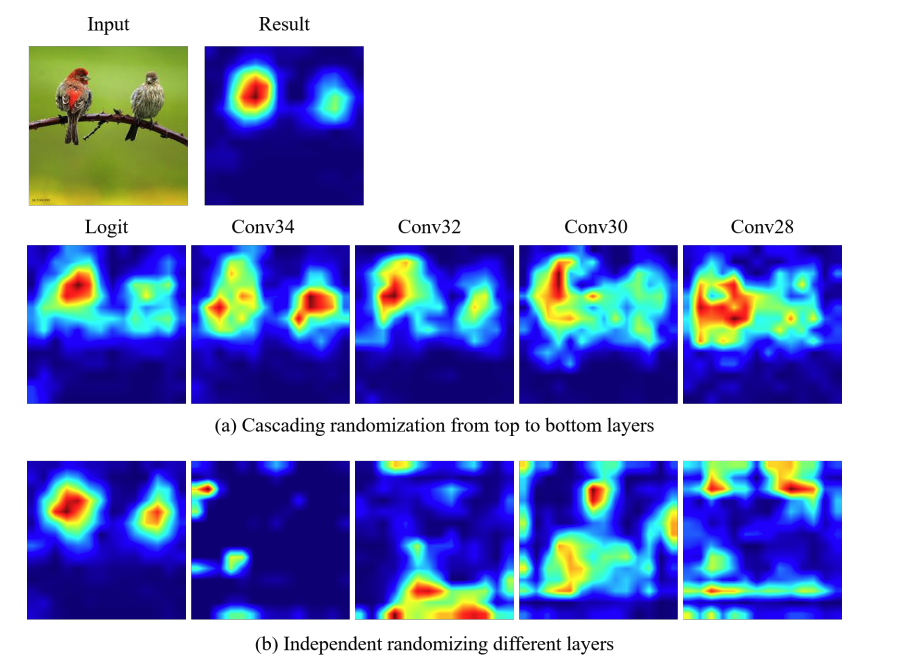
Sanity Check
Sanity Checkは、Google Brainのチームが発表したXAI手法を評価するための手法です。パラメータが全く違うのにも関わらず同じような出力をした場合、しっかり学習結果を反映できているとは言えません。
本論文では、分類器から対象となる層までを初期化し得られたヒートマップと得られた結果を比較することで、手法がパラメータ依存していることを示しています。
データ増強
Group-CAMはデータ増強手法にも応用できます。論文上では、学習時間を短くするためにwkcをなくし誤差逆伝播法を用いず、θ%以下のピクセルを0、それ以外を1とするマスクとし生成されるIl'で学習をすると、ResNet-50がImageNet-1k上で0.59%精度が向上したと報告しています。
まとめ
CNNの判断根拠を説明する手法は活性化ベースと領域ベースに大別することができ、Group-CAMはそれぞれの欠点を補ったモデルであると言えます。Grad-CAMを用いる際に乗るノイズが軽減されていたり、1枚の判断根拠を推論する計算コストが少ない利点があります。今後ViTの判断根拠可視化手法にどのようにこの研究が活かされていくかが楽しみです。





この記事に関するカテゴリー


