
欠損データ列も統一して時系列データ合成を可能にしたGT-GAN
3つの要点
✔️ 時系列データ合成において、従来規則的なデータと、データ欠落を持つ不規則的なデータを一つの生成モデルで取り扱うことは困難でした
✔️ GT-GANは、GAN, オートエンコーダ、ニューラル常微分方程式、ニューラル制御微分方程式、連続時間フロープロセスのモデルを組み合わせた3つのデータの流れを合成したモデルです
✔️ 不規則データをデコーダ中の常微分方程式、隠れベクトルデータからの生成器への逆伝播を通して補完し、規則データとも統一的なデータ生成を実現しています
AutoFormer: Searching Transformers for Visual Recognition
written by Jinsung Jeon, Jeonghak Kim, Haryong Song, Seunghyeon Cho, Noseong Park
(Submitted on 5 Oct 2022 (v1), last revised 11 Oct 2022 (this version, v3))
Comments: NeurIPs 2022
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
NeurIPS 2022採択論文です。時系列合成は、深層学習分野における重要な研究課題のひとつであり、データの増強に利用することができます。時系列データの種類は、規則的なものと不規則なもの(系列に欠陥がある)に大別されます。しかし、両タイプに対して、モデル変更なしに良好な性能を示す既存の生成モデルは存在しません。そこで、規則的・不規則的な時系列データを合成することができる汎用モデルを提案しています。知る限り、時系列合成の最も困難な設定の一つである時系列合成の汎用モデルを設計したのはこの論文が初めてです。この目的のために、生成的敵対ネットワークをベースとした手法を設計し、ニューラル常微分/制御微分方程式から連続時間フロープロセスに至るまで、多くの関連技術を一つのフレームワークに慎重に統合しています。本手法は、既存のすべての手法を凌駕する性能を持ちます。
はじめに
実世界の時系列データは頻繁に不均衡及び/又は不十分であるため、時系列データを合成することは時系列に関連する多くのタスクの中で、最も重要なタスクの1つになっています。しかし、規則的な時系列データと不規則な時系列データは異なる特性を持つため、両者には異なるモデル設計が採用されてきました。したがって、既存の時系列合成の研究は、規則的または不規則的な時系列合成のいずれかに焦点を当てています[Yoon et al., 2019, Alaa et al., 2021]。知る限りでは、両方のタイプでうまく機能する既存の方法はありません。
規則的な時系列とは、欠落のない規則的にサンプリングされた観測値を意味し、不規則な時系列とは、時折、いくつかの観測値が欠落していることを意味します。不規則時系列は、規則的な時系列に比べて処理が非常に困難です。例えば、時系列データをその周波数領域、すなわちフーリエ変換した後にニューラルネットワークのパフォーマンスが向上することが知られており、いくつかの時系列生成モデルはこのアプローチを用いています[Alaa et al., 2021]。しかし、不規則性の高い時系列から予め決められた周波数を観測することは容易ではありません[Kidger et al., 2019]。ここで、連続時間モデル[Chen et al., 2018, Kidger et al., 2020, Brouwer et al., 2019]は、規則的な時系列と不規則な時系列の両方を処理するのに良い性能を示しています。それらをベースにして、この論文ではモデルの変更なしに両方の時系列タイプを合成することができる汎用モデルを提案しています。
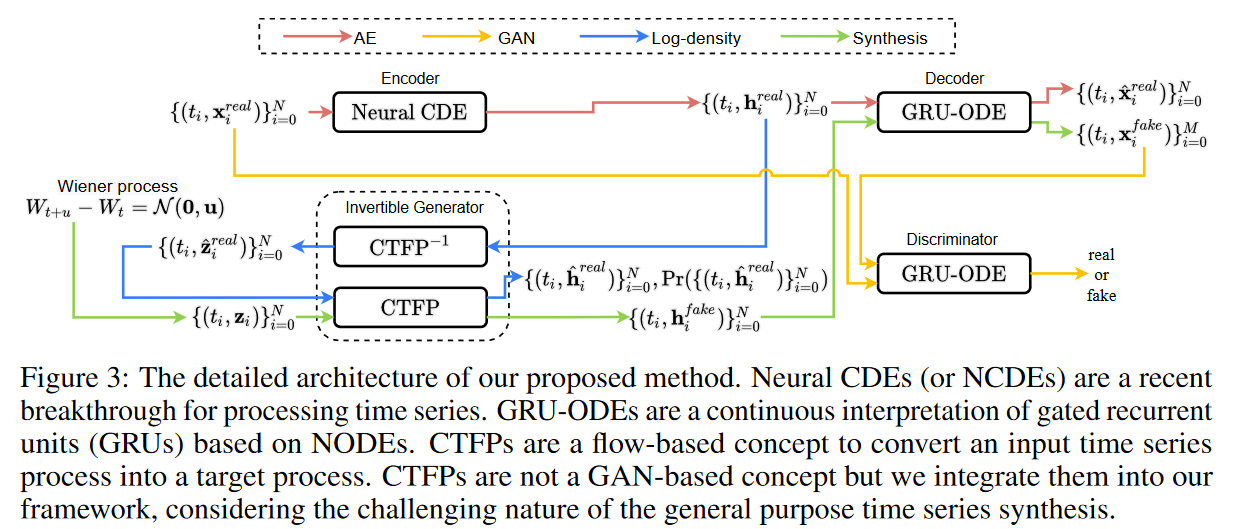
目標を達成するために、この手法では生成敵対的ネットワーク(GANs [Goodfellow et al., 2014])、オートエンコーダ(AE)からニューラル常微分方程式(NODEs [Chen et al., 2018] )、ニューラル制御微分方程式(NCDEs [Kidger et al., 2020] )、連続時間フロー過程(CTFPs [Deng et al., 2020] )まで多様な技術を利用した高度なモデルを設計します。これは、問題の難しさを反映しています。
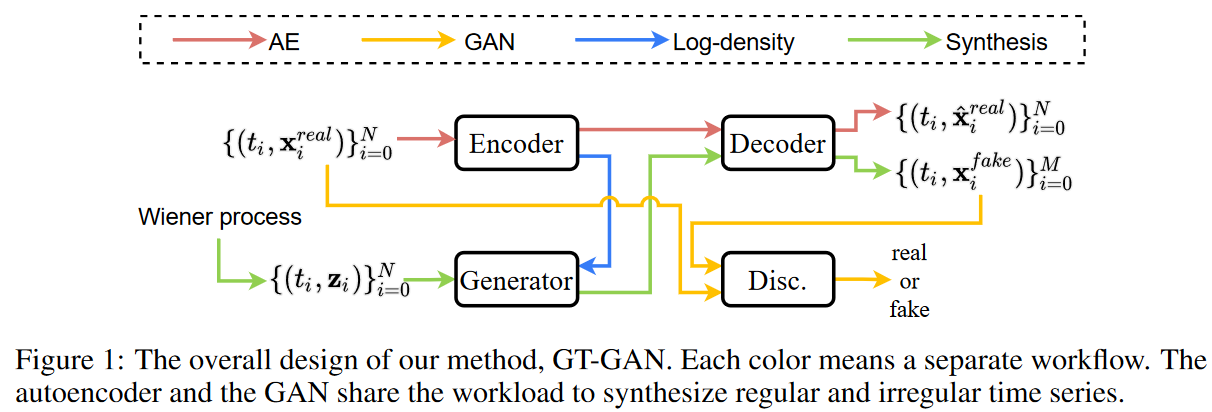
Fig. 1に本提案手法の全体設計を示します。本手法のポイントは、GANの敵対的学習とCTFPの厳密最尤学習を一つのフレームワークにまとめたことです。しかし、厳密最尤学習は、入力と出力のサイズが同じである可逆写像関数にのみ適用可能です。そこで、本論文では可逆的な生成器を設計し、その隠れ空間でGANが敵対的な学習を行うオートエンコーダを採用します。すなわち、
i) エンコーダの隠れベクトルサイズは生成器のノイジーベクトルと同じであり
ii) 生成器は偽の隠れベクトルの集合を生成し
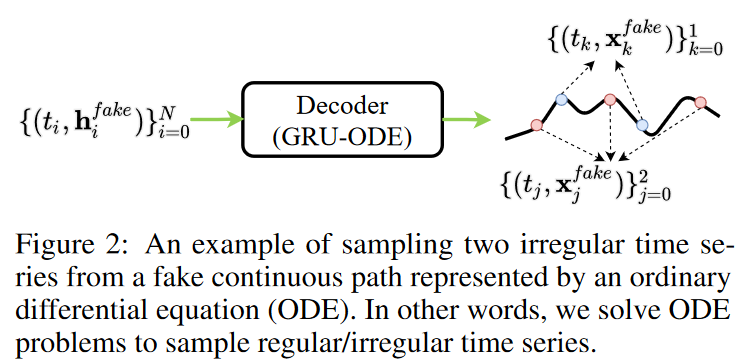
iii) デコーダは集合を偽の連続パスに変換し(Fig. 2参照)
iv) 識別器はサンプリングした偽サンプルを読み込んでフィードバックを提供します。
ここで、第3段階において、デコーダが偽の連続パスを作成することに強調します。したがって、偽の経路から任意の規則的/不規則的な時系列サンプルをサンプリングすることができ、本手法の柔軟性を示しています。
4つのデータセットと7つのベースラインを用いて実験を行いました。規則的な時系列と不規則的な時系列の両方についてテストを行いました。本手法はどちらの環境でも他のベースラインより優れた結果を出しました。
本手法の貢献は以下のようにまとめられます。
1. 最先端の様々な深層学習技術に基づくモデルを設計する。本手法は、正規から不規則までのあらゆるタイプの時系列データを、モデルの変更なしに処理することが可能である。
2.提案モデルの有効性を実験結果と可視化により証明する。
3. 我々の課題は時系列合成の中でも最も困難な課題の一つであるため、提案するモデルのアーキテクチャは慎重に設計されている。
4.切り分け研究により、提案モデルがどの部分が欠けてもうまく機能しないことが示された。
提案手法
時系列合成は困難なタスクであるため、提案するデザインは他のベースラインよりもはるかに複雑になっています。
全体のワークフロー
まず、全体的なワークフローを説明すると、以下のように、いくつかの異なるデータパス(およびデータパスに基づくいくつかの異なる学習方法)から構成されています。
1. オートエンコーダパス
時系列サンプルが与えられると、エンコーダは隠れベクトルのセットを生成する。デコーダは連続パスを回復し、これは提案手法の柔軟性を向上させる。このパスからサンプリングする。すべてのサンプリング時点について連続パスとサンプリング値が一致するように標準的なオートエンコーダ(AE)損失を用いてエンコーダとデコーダを学習させる。
2. 敵対的経路
ノイズベクトルが与えられたとき、生成器は偽の隠れベクトルの集合を生成する。復号器は偽の隠れベクトルから偽の連続パスを復元する。不規則な時系列の合成のため、tj は[0, T ]でサンプリングする。生成器、復号器、識別器を標準的な敵対的損失で学習させる。
3. 対数密度経路
時系列サンプルに対する隠れベクトルのセットが与えられると、生成器の逆パスはノイズベクトルを再生成する。フォワードパスの間、Groverら[2018]とDengら[2020]に触発されて、すべてのサンプリング時点iについて負の対数確率を変数変化定理で計算し、それを最小化して学習する。
特に、オートエンコーダの隠れ空間の次元は生成器の潜在的な入力空間の次元と同じであること、すなわち、dim(h) = dim(z)であることに注意してください。これは生成器における厳密尤度学習のために必要です。厳密尤度を推定するためには、変数の変化定理により、入力と出力の大きさが同じであることが必要なのでする。これに加えて、オートエンコーダと生成器を一つの枠組みに統合することで、偽の時系列を合成する作業を分担させます。すなわち、生成器が偽の隠れベクトルを合成し、デコーダがそこから人間が読める偽の時系列を再生成するのです。
オートエンコーダ
・エンコーダ
一般的なNCDEは、リカレントニューラルネットワーク(RNN)の連続的な類似物として考えられており、以下のように定義されています。
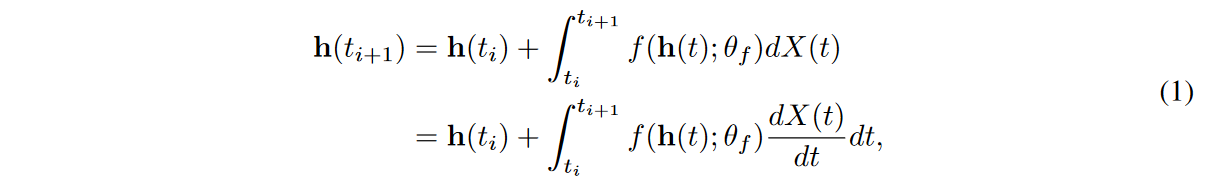
ここで、X(t)は、生の離散時系列サンプル{(ti, xreal i )}N i=0から補間アルゴリズムによって作成された連続パスであり、すべてのiについてX(ti) = (ti, xreal i )、他の非観測タイムポイントについては補間アルゴリズムが値を埋めることに注意してください。NCDEはX(t)の時間微分を読み続けるます。この場合、{hreal i }N i=0を以下のように集めます。
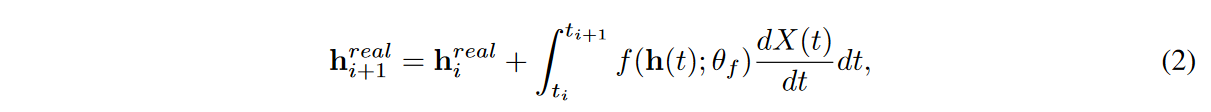
ここで、hreal 0 = FCdim(x)→dim(h)(xreal 0 )、FCinput_size→output_size は特定の入力と出力サイズを持つ完全連結層です。したがって、入力時系列{(ti, xreal i )}N i=0は、隠れベクトル{(ti, hreal i )}N i=0のセットで表されます。NCDEはRNNの連続類似物であるため、不規則時系列の処理に最も適していることを示しています[Kidger et al., 2020]。
・デコーダ
隠れ表現から時系列を再現する本手法のデコーダは、GRU-ODE [Brouwer et al., 2019]に基づいており、以下のように定義されます。
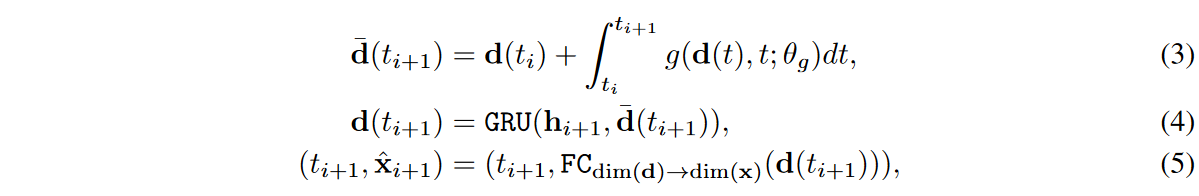
ここで、d(t0) = FCdim(h)→dim(d)(h0) および hi は i 番目の実または偽の隠れベクトル、すなわち hreal i または hfake i を意味します。 Fig. 3 では、デコーダはオートエンコーダと合成プロセスの両方に関与していることを思い出してください。GRU-ODEs は GRU を連続的に解釈するためにニューラル常微分方程式 (NODE) と呼ばれる技術を使用しています。
特に、式(4)におけるゲート付きリカレントユニット(GRU)は、NODEsを用いた時系列処理に有効であることが知られているジャンプと呼ばれます[Brouwer et al., 2019, Jia and Benson, 2019]。全ての訓練時系列サンプルにおいて、全てのiについてxreal iとˆ xreal iの間の標準再構成損失を用いてエンコーダ・デコーダを訓練します。
汎用敵対ネットワーク
・生成器
標準的なGANでは、生成器は一般的にノイズの多いベクトルを読み取って偽のサンプルを生成するが、本手法の生成器はWiener過程からサンプリングした連続パス(または時系列)を読み取って偽の時系列サンプルを生成します。この生成概念は連続時間フロー過程(CTFP [Deng et al., 2020] )として知られています。本手法の生成プロセスへの入力はWienerプロセスからサンプリングされたランダムなパスであり、これはパスの潜在ベクトルの時系列によって表され、出力は同じく隠れベクトルの時系列で表される隠れベクトルのパスとなります。
したがって、生成器は次のように書くことができます。
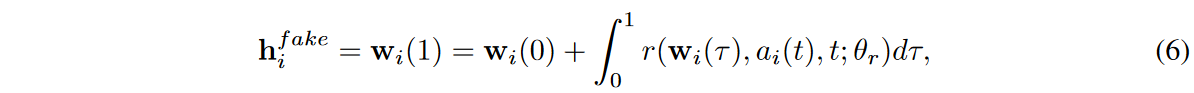
ここで、τは積分問題の仮想時間変数、tiは時系列サンプル{(ti, xreal i )}M i=0に含まれる実物理時間です。この設計はai(t)で拡張されたNODEモデルに相当することを強調します。
NODEの可逆的な性質のおかげで、変数の変更定理とHutchinsonの確率的トレース推定器を用いて、以下のようにhreal iの正確な対数密度、すなわち、hreal iが生成器によって生成される確率を計算できます[Graswohlら、2019、Dengら、2020]。
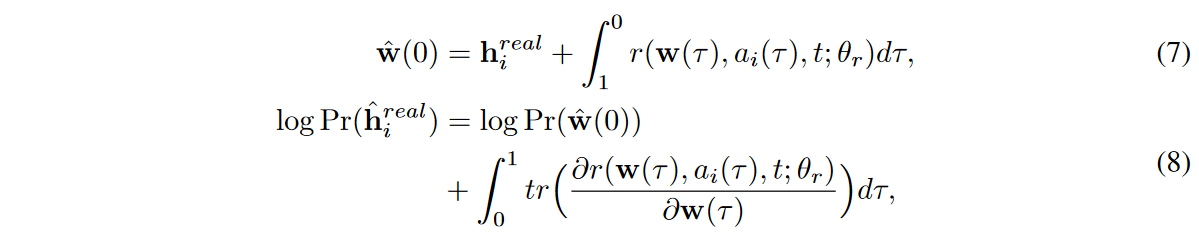
式(7)はFig. 3の「CTFP-1」に、式(6)、式(8)は「CTFP」に対応する。式(7)では、逆モード積分問題を解くために、積分時間を逆にしていることに注意してください。そこで、各 ti に対して負の対数密度を最小化し、生成器の学習を、i) 識別器に対する敵対学習、ii) 対数密度を用いた最尤推定量(MLE)学習の2種類の学習パラダイムで行います。
・識別器
GRU-ODE技術に基づき、以下のように識別器を設計します。
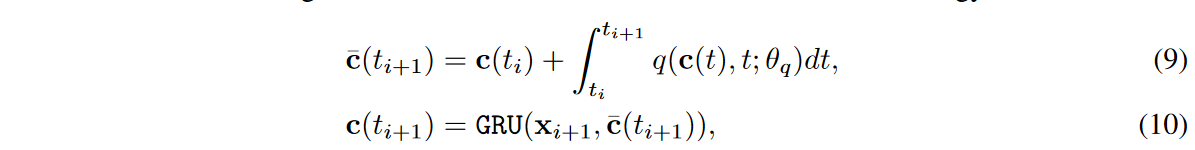
ここで、c(t0) = FCdim(x)→dim(c)(x0), xi はi番目の時系列値、すなわちxreal i またはxfake iを意味します。ODE関数qはgと同じアーキテクチャであるが独自のパラメータθqを持っている。その後、本物か偽物かの分類 y = σ(FCdim(c)→2(c(tN ))) を計算するが、σはソフトマックス・アクティベーションです。
学習方法
エンコーダ・デコーダの学習には、平均二乗復元損失、すなわち、すべての i に対する ‖xreal i -ˆ xreal i ‖22 の平均を用います。次に、標準的なGANの損失を用いて、生成器と識別器を学習します。予備実験では、オリジナルのGAN損失が本手法のタスクに適していることがわかりました。したがって、WGAN-GP[Gulrajani et al., 2017]などの他のバリエーションの代わりに、標準的なGANロスを使用します。我々は、以下の順序でモデルを訓練します。
1. エンコーダデコーダネットワークをKAE反復のための再構成損失を事前に訓練する。
2. KJOINT反復では、上記の事前学習の後、以下の順序で全ネットワークの共同学習を開始する: i) エンコーダ・デコーダのネットワークを再構成損失で学習、 ii) 識別器・生成器のネットワークをGAN損失で学習、 iii) 識別器の分類出力を改善するデコーダを識別器損失で学習、 iv) PMLE反復毎に生成器をMLE損失で学習する。MLEの学習が頻繁すぎるとモード崩壊が起こることがわかったので、PMLEの繰り返しごとにMLEの学習を行う。
特に、識別器を助けるためにデコーダを訓練する2-iiステップは、オートエンコーダとGANが単一のフレームワークに統合される一つの追加ポイントです。つまり、生成器は、デコーダと識別器の両方を欺く必要があるのです。
NCDEとGRU-ODEの良設定性(well-posedness)については、Lyonsら[2007, Theorem 1.3]とBrouwerら[2019]でLipschitz連続性という穏やかな条件のもと既に証明されています。本論文は、本手法のNCDE層も良設定問題であることを示します。ReLU、Leaky ReLU、SoftPlus、Tanh、Sigmoid、ArcTan、Softsignなどほぼ全ての活性化関数はリプシッツ定数が1であり、ドロップアウト、バッチ正規化、その他のプーリング方法など、その他のよくあるニューラルネットワーク層はリプシッツ定数の値が明示されています。したがって、ODE/CDE関数のリプシッツ連続性は、本手法のケースでも満たすことができます。つまり、よく解かれた学習問題です。その結果、我々の学習アルゴリズムは良設定な問題を解くので、その学習過程は実際上安定です。
実験評価
実験環境
・データセット
本論文では、2つのシミュレーションデータセットと2つの実世界のデータセットで実験を行いました。Sinesは5つの特徴を持ち、各特徴は独立に異なる周波数と位相で作成されています。各特徴について、i∈{1, ..., 5}, xi(t) = sin(2πfit + θi), wherefi ∼ U [0, 1] and θi ∼ U [-π, π]とする。MuJoCoは14個の特徴量を持つ多変量物理シミュレーション時系列データである。Stocks は 2004 年から 2019 年までの Google の株価データである。各観測は1日を表し、6個の特徴量を持ちます。EnergyはUCI家電エネルギー予測データセットで、28個の値を持ちます。挑戦的な不規則環境を作成するために、各時系列サンプル{(ti, xreal i )}N i=0から30, 50, 70%の観測がランダムにドロップされます。ランダムな値を落とすことは、文献上では主に不規則な時系列環境を作るために使われている[Kidger et al., 2019, Xu and Xie, 2020, Huang et al., 2020b, Tang et al., 2020, Zhang et al., 2021, Jhin et al., 2021, Deng et al., 2021]。したがって、我々は規則的環境と非規則的環境の両方で実験を行います。
・ベースライン
定期的な時系列の実験では、以下のベースラインを考慮する。TimeGAN、RCGAN、C-RNN-GAN、WaveGAN、WaveNet、T-Forcing、P-Forcingである。不規則な実験では、不規則な時系列を扱えないWaveGANとWaveNetを除外し、他のベースラインはそのGRUをGRU-4tとGRU-Decay(GRU-D)[Che et al, 2018]に置き換えて再設計しました。GRU-4tとGRU-Dは、不規則な時系列データの処理に有効なモデルです。GRU-4tは、さらに観測間の時間差を入力として使用します。GRU-Dは、GRU-4tを修正して観測値間の指数減衰を学習させたものである。TimeGAN-4t, RCGAN-4t, C-RNN-GAN-4t, T-Forcing-4t, P-Forcing-4t (resp. TimeGAN-D, RCGAN-D, C-RNN-GAN-D, T-Forcing-D, P-Forcing-Decay) は GRU-4t (resp. GRU-D) で変更され、不規則データを扱えるようになったものである。また、我々のアブレーション研究では、NODE、VAE、フローモデルなど、多くの先進的な手法が用いられている。本提案手法では、これらの高度な手法を内部的にサブパーツとして持っているため、あえてアブレーション研究に残している。
・評価指標
合成されたデータの定量的な評価のために,TimeGAN [Yoon et al., 2019]で使用されているdiscriminative scoreとpredictive scoreで評価します。識別スコアは、元データと合成データの類似度を測定します。ニューラルネットワークを用いて元のデータと合成されたデータを分類するモデルを学習した後、元のデータと合成されたデータがうまく分類されているかどうかをテストします。識別スコアは|Accuracy-0.5|であり、このスコアが低いと分類が困難であるため、元データと合成データは類似していると判断します。予測スコアは、TSTR(train-synthesis-and-test-real)法により合成データの有効性を測定するものである。合成されたデータを使って次のステップを予測するモデルを学習させた後、予測値とテストデータのグランドトゥルース値との間の平均絶対誤差(MAE)を計算します。MAEが小さければ、合成データを用いて学習したモデルは元データに近いと判断します。定性的な評価としては、合成されたデータを元のデータで可視化します。可視化には2つの方法があります。一つは,t-SNE[Van der Maaten and Hinton, 2008]を用いて,元データと合成データを2次元空間に投影するものです。もう一つは,カーネル密度推定を用いてデータの分布を描く方法です。
実験結果
・通常の時系列合成
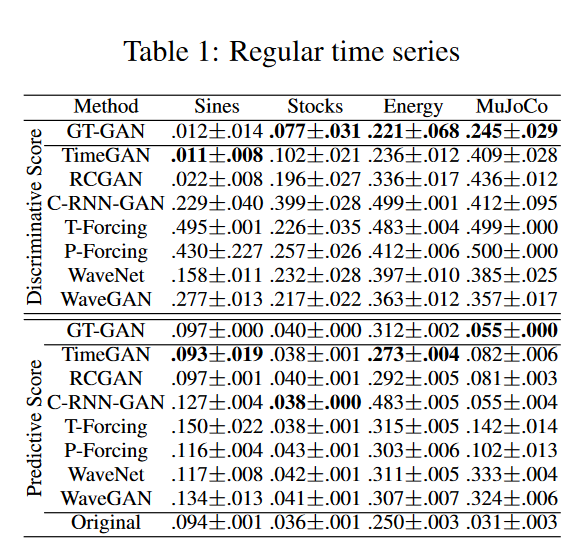
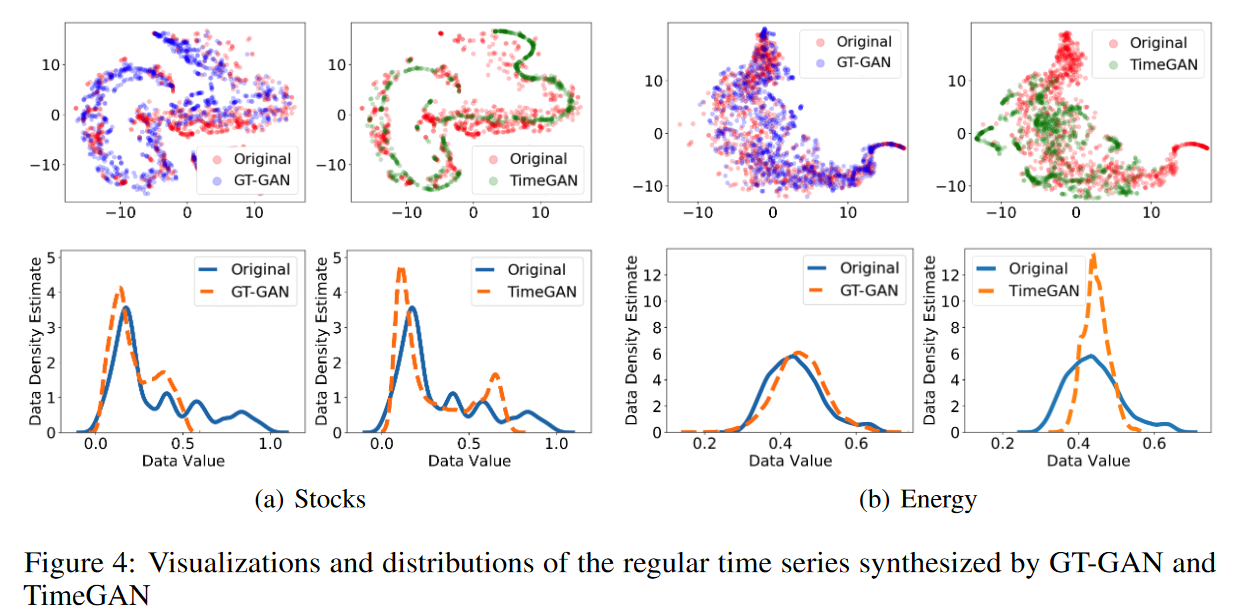
Table 1では、通常の時系列合成の結果を列挙しています。GT-GANは、ほとんどの場合において、従来の最先端モデルであるTimeGANよりも優れた性能を示しています。Fig. 4の1段目に示すように、GT-GANはTimeGANよりも元のデータ領域をよくカバーしています。また、Fig. 4の2行目は、GT-GANとTimeGANで生成した偽データの分布です。GT-GANの合成データの分布は、TimeGANよりも元データの分布に近く、TimeGANの暗黙的尤度学習に対してGT-GANの明示的尤度学習が有効であることが示されました。
・不規則な時系列合成
Table 2、3、4では、不規則な時系列合成の結果を一覧にしています。GT-GANは全てのケースにおいて、他のベースラインよりも優れた識別・予測スコアを示しています。Table 2において、各時系列サンプルからランダムに30%の観測値を削除した場合、GT-GANはTimeGANを大きく上回り、最良の結果を示すことがわかりました。GRU-4tで修正したベースラインとGRU-Decayで修正したベースラインは同等の結果を示し、この表ではどちらが優れていると言うことはできません。

Table 3(50%ドロップ)では、多くのベースラインが妥当な合成品質を示さず、例えば、TimeGAND, TimeGAN-4t, RCGAN-D, C-RNN-GAN-D, C-RNN-GAN-4t は識別スコアが0.5でした。意外なことに、T-Forcing-D、T-Forcing-4t、P-Forcing-D、P-Forcing-4tはこのケースでよく機能します。しかし、本手法のモデルは全てのデータセットにおいて明らかに最良の性能を示しています。GRU-4tで修正したベースラインは、GRU-Decayで修正したベースラインよりも、このケースでわずかに良い結果を示しています。

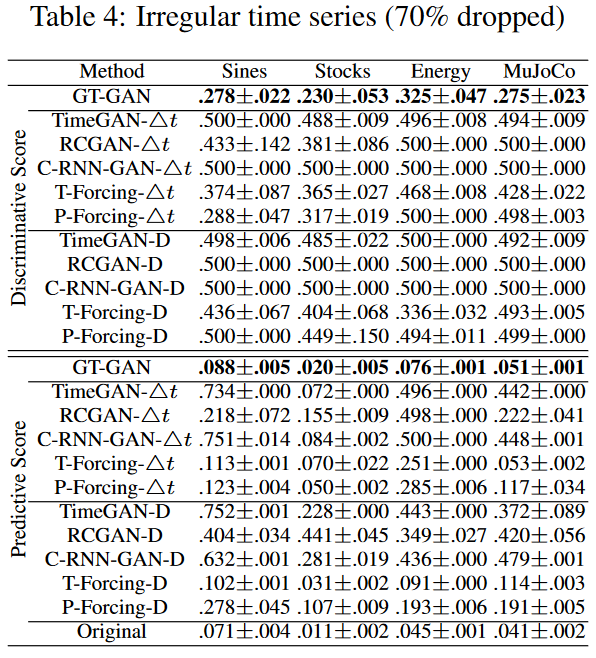
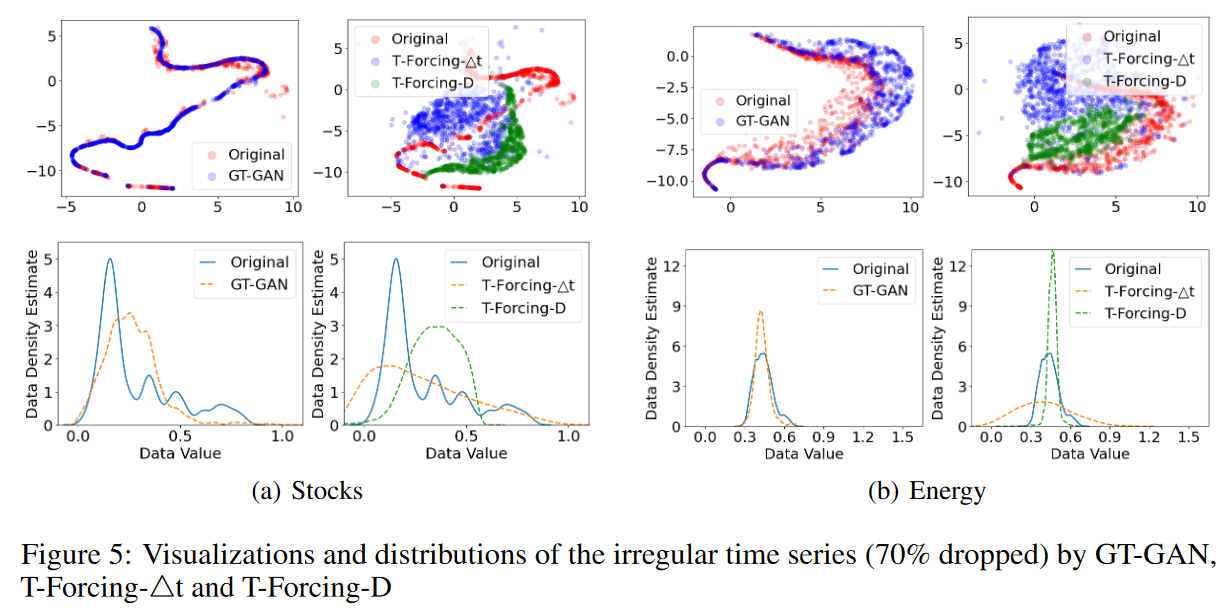
最後に、Table 4 (70% dropped) は、本論文で最も困難な実験の結果である。すべてのベースラインは、ドロップ率が高いため、うまく機能しない。T-ForcingD、T-Forcing-4t、P-Forcing-D、P-Forcing-4tは、50%を超えないドロップ率で妥当な性能を示したが、この場合、うまく機能しない。このことは、不規則性の高い時系列データに弱いことを示している。また、他のGANベースのベースラインも同様に脆弱である。我々の方法は、例えば、既存のすべての方法を大きく上回る。Sinesの識別スコアはGT-GANが0.278、T-Forcing-Dが0.436、P-Forcing4tが0.288、MuJoCoの予測スコアはGT-GANが0.051、T-Forcing-Dが0.114、T-Forcing4tが0.053となりました。Fig. 5は、我々の手法と、最も良いパフォーマンスを示したベースラインを視覚的に比較したものです。
・切り分けと感度解析
GT-GANの特徴は、式(8)の負の対数密度を用いたMLE学習と、エンコーダとデコーダの事前学習ステップです。Table 5は、一部の学習機構を削除した様々なGT-GANの修正結果です。負対数密度学習を用いたモデルは、用いないモデルよりも良好な性能を示しています。つまり、MLE学習は合成データをより実データに近づけます。事前学習されたオートエンコーダを用いない場合、予測スコアはGT-GANより優れています。しかし、識別スコアは最悪です。
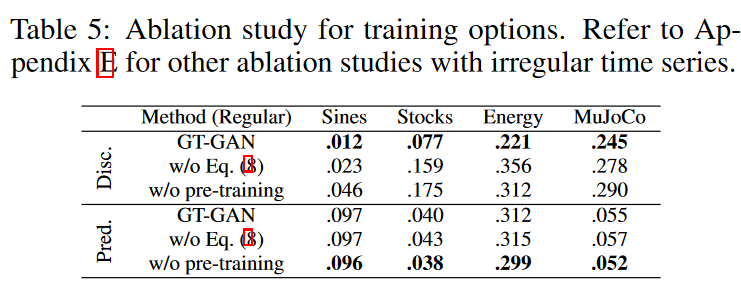
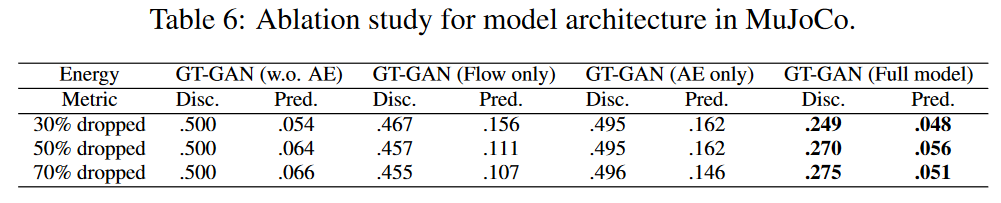
Table 6では、本手法のモデルのアーキテクチャを変更しました。
i) 最初の切り分けモデルでは、オートエンコーダを削除し、生成器と識別器のみで敵対的学習を行う(GT-GAN (w.o. AE)と呼ぶ)。
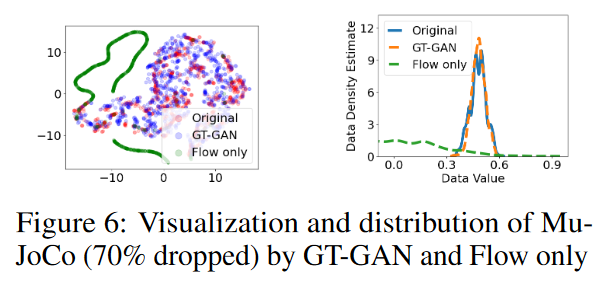
ii) 2番目の切り分けモデル(GT-GAN(Flow only))は、CTFPベースの生成器のみを持ち、最尤法による学習を行う。このモデルは、オリジナルのCTFPモデル[Deng et al., 2020]と同等である。
iii) 3番目の切り分けモデルは、オートエンコーダーのみを持ち、「GT-GAN(AEのみ)」と表記される。ただし、VAE(variational autoencoder)モデルへ変換する。GT-GANのフルモデルでは、エンコーダーは隠れベクトル{(ti, hreal i )}N i=0 を生成するが、この切り分けモデルでは、{(ti, N (hreal i , 1))}N i=0 に変更し、N (hreal i , 1) はhreal i を中心とする単位ガウシアンを意味するものとします。デコーダはフルモデルと同じです。このモデルには変分学習を用いています。
切り分けモデルのうち,GT-GAN(Flowのみ)はほとんどの場合,識別器のスコアより優れています。しかし,本手法のフルモデルが全てのケースで明らかに最良です。本論文の研究では、Table 6に示すように、GT-GANの切り分けモデルは、いずれかの部分が欠落している場合、そのフルモデルほど良いパフォーマンスを発揮しないことが示されています。
モデルの性能に大きく影響するハイパーパラメータは、ジェネレータの絶対許容度(atol)、相対許容度(rtol)、MLEトレーニングの周期(PMLE)です。atolとrtolは、CTFPのODEソルバーが実行する誤差制御を決定します。その結果、データ入力サイズに応じて適切な誤差許容値(atol, rtol)が存在することがわかりました。例えば、入力サイズの小さいデータセット(Sines, Stocksなど)は(1e-2, 1e-3)で、入力サイズの大きいデータセット(Energy, MuJoCoなど)は(1e-3, 1e-2)で良好な識別スコアが得られることがわかります。
関連研究
GANは、最も代表的な生成技術の一つです。その代表的な研究論文で初めて紹介されて以来、GANは様々な分野の主要なものに採用されてきました。近年では、時系列データに対するGANの合成に注目が集まっています。そのため、時系列データの合成のためのGANがいくつか提案されています。C-RNN-GAN [Mogren, 2016]は、生成器と識別器にLSTMを用いることで、逐次データに適用できる通常のGANの枠組みを持っています。Recurrent Conditional GAN (RCGAN [Esteban et al., 2017])は、その生成器と識別器がより良い合成のために条件入力を取ることを除いて、同様のアプローチをとっています。WaveNet [van den Oord et al., 2016]も、拡張カジュアルコンボリューションを用いて、過去のデータの条件付き確率から時系列データを生成しています。
WaveGAN [Donahue et al., 2019]はDCGAN [Radford et al., 2016]と同様のアプローチで、その生成器はWaveNetをベースにしています。GANモデルではないが、teacher-forcing (T-Forcing [Graves, 2014]) や professor-forcing (P-Forcing [Lamb et al., 2016]) のモデルの予測特性を利用して、ノイズベクトルから時系列データを生成するように修正することが可能です。TimeGAN [Yoon et al., 2019]は、さらに別の時系列合成のためのモデルです。このモデルは主に偽の正規時系列サンプルの合成を目的としています。彼らは、GANの敵対的学習と、xiからxi+1を予測する教師あり学習で、xiとxi+1はそれぞれ時刻tiとti+1における二つの多変量時系列値を意味する枠組みを提案しました。
まとめ
時系列合成は深層学習における重要な研究課題であり、これまで正則時系列合成と不規則時系列合成に分かれて研究されてきました。しかし、モデルの変更なしに規則的な時系列と不規則な時系列の両方を扱える既存の生成モデルはまだ存在しませんでした。本提案手法であるGT-GANは、GANからNODE、NCDEに至る様々な先進的深層学習技術に基づいており、モデルアーキテクチャやパラメータの変更なしに、考えられる全てのタイプの時系列を処理することが可能です。様々な合成データセットと実世界データセットを取り入れた実験により、提案手法の有効性が証明されました。切り分けの研究では、欠損部分を除いた完全な手法のみが合理的な合成能力を示しました。
(記事著者)複雑なモデル全体の学習時の安定性については詳述されていませんが、ニューラル制御微分方程式と常微分方程式部分については良設定であるとし、安定しているとしています。




この記事に関するカテゴリー






