
勾配流を利用した生成サンプルの改良【ICLR2021】
3つの要点
✔️ 深層生成モデルが生成するサンプルの質を向上させる手法の提案(DG$f$low)
✔️ DG$f$lowを尤度を明示的に扱う生成モデルであるVAEや正規化流へ拡張
✔️ 画像・テキストのデータセットにおいて生成サンプルの質向上を確認
Refining Deep Generative Models via Discriminator Gradient Flow
written by Abdul Fatir Ansari, Ming Liang Ang, Harold Soh
(Submitted on 1 Dec 2020 (v1), last revised 5 Jun 2021 (this version, v4))
Comments: Accepted by ICLR2021
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Machine Learning (stat.ML)
code:

本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
はじめに
近年、機械学習において発展している領域として深層生成モデルが挙げられます。深層生成モデルの研究は実世界に存在するデータに非常によく似たデータを人工的に生成することを目的としています。
深層学習モデルの一つとしてGAN(Generative Adversarial Networks)があります。GANは実データと生成データを判別するDiscriminatorとサンプルを生成するGeneratorという二種類のニューラルネットワークで構成されており、実データ分布と生成データ分布の「距離」をミニマックス最適化によって最小化することで学習を行います。
GANの目的は実データに非常によく似た新規のデータを生成することにあるため、学習が終了するとDiscriminatorは捨ててしまい、Generatorのみを用いてサンプルを生成することが一般的でした。
今回は学習済みのDiscriminatorに残された実データ分布に関する情報を用いて、質の悪い生成サンプルを改善するフレームワーク(DG$f$low)をご紹介します。
勾配流とは
DG$f$lowの具体的な説明に入る前に勾配流について説明します。勾配流とはスカラー関数$F(x)$を最小化する過程における「最短経路」のことです。
ここで「最短経路」は各時間における移動が$F$を最も小さくする方向を向いていることを意味します。従って勾配流$\mathbf{x}(t)$は以下の式を満たします。
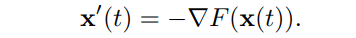
勾配流を用いた生成サンプルの改良(DG$f$low)
従来の深層生成モデルにおける問題の一つとして、潜在空間のサンプルによって生成データの質が大きく異なってしまう点があります。生成モデルの性能を高めるには質の悪い生成データをどのように減らすのかが重要です。従来ではメトロポリス・ヘイスティングス法を用いて質の悪いサンプルを棄却する手法がとられていましたが、DG$f$lowにおいては質の悪いサンプルを捨てずに改良する手法を提案しています。
勾配流を構築する
勾配流を構築するための第一ステップとして最小化したい$F$を考えます。これは従来のGANにおける損失関数と大差なく、生成データ分布と実データ分布の「距離」を表す$f$-ダイバージェンスとなります。ただし、勾配流を離散的な時間ステップでシミュレーションする際に多様性を担保する目的で負のエントロピー項が追加されています。関数$F$は以下のように定義されます。ただし、$\mu$は実データの確率測度であり、$\rho$は生成データの確率測度を表しています。
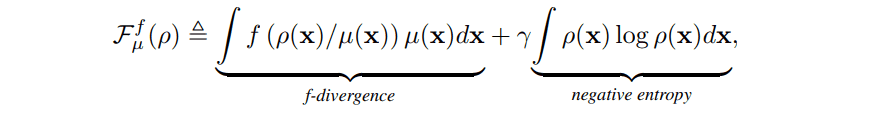
次のステップとして$F$の勾配流について考えます。この勾配流は偏微分方程式の一種であるFokker-Plank方程式として表すことができ、これを満たす$\mathbf{x}$は確率過程の一種であるMcKean-Vlasov過程に従うことが知られています。Euler-Maruyama法による数値シミュレーションを行うことで、各時点のデータ点$\mathbf{x_t}$を得ることができます。

データ空間での改良から潜在空間での改良へ
(1)での数値シミュレーションを見ると、サンプル改良の手続きはデータ空間で行われますが、画像などの高次元データの場合にはエラーが蓄積され、生成データの質が悪くなってしまうという問題がありました。そこで、Generatorが単射であるという条件の元、サンプル改良の手続きを潜在空間で行うよう変更しました。Generatorに関する条件は満たされない場合があるものの、経験的にうまくいくことがわかっています。
以上を踏まえてDG$f$lowのアルゴリズムは以下のようになります。

実験結果
二次元データセットでの検証
はじめにDG$f$lowの性能を2次元の人工データセット(25Gaussians[上段], 2DSwissroll[下段])において確認しました。それぞれのデータセットに関してWGAN-GP(青)を学習させた後にDG$f$lowを含む3種類の手法(赤)でサンプル改良を行っています。
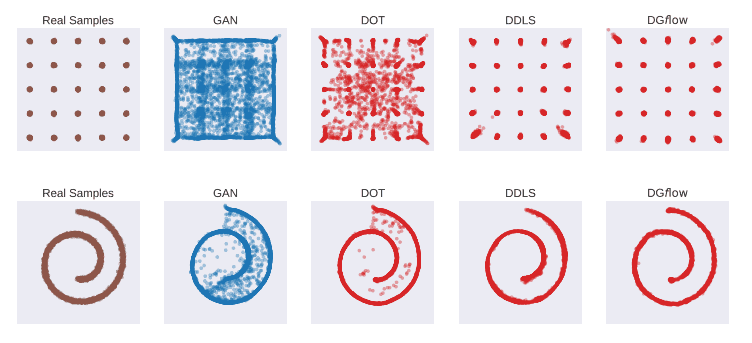
上の図から、WGAN-GPから生成されるサンプルの中には実データからかけ離れたものが少なからず存在しており、DG$f$lowとDDLSではそれらを改良できていることがわかります。
画像データセットでの検証
画像データの生成に関してはCIFAR10およびSTL10データセットを用いました。生成サンプルの評価にはFrechet Inception Distance(FID)およびInception Score(IS)という二つの指標を用いました。(ブログではFIDの比較のみ扱います)FIDは小さい値ほど良い指標です。
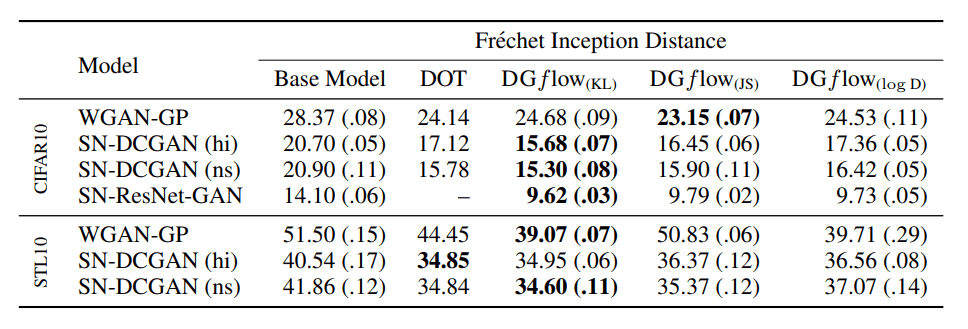
上の表ではFIDの比較が行われています。ベースとして用いる深層生成モデルとしてWGAN-GP、SN-DCGAN、SN-ResNet-GANが用いられています。これらは全てDiscriminatorがスカラーを出力するタイプのGANとなっています。ほとんどの場合において従来手法であるDOTを上回る性能を確認できました。
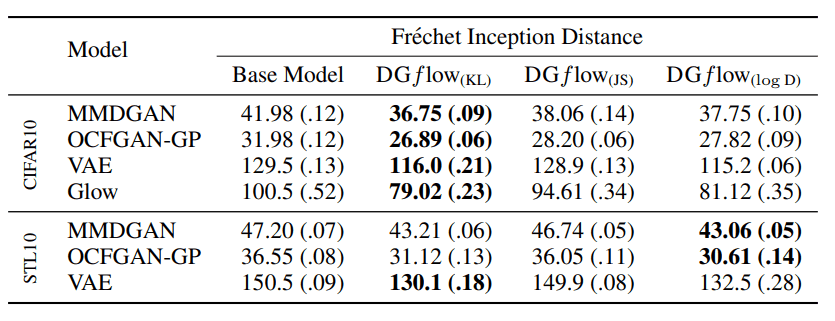
上の表ではベースとして様々な種類の深層生成モデルをテストした結果です。例えば、MMDGANなどはDiscriminatorの出力がベクトルとなるGANの派生形です。また、VAEやGlowは明示的に対数尤度を扱う深層生成モデルであり、GANとは異なります。アーキテクチャや生成モデルが異なる場合であってもDGflowを用いることでサンプルの改良を行えることが示されました。
言語データセットでの検証
テキストデータの生成においては文字レベルの言語モデリングに用いられるBillion Words Datasetを用いました。Billion Words Datasetは32文字の文字列に前処理されたデータセットです。生成サンプルの評価には生成サンプルと実データのn-gram間で計算したJSダイバージェンスを用いています。(JS-4, JS-6)

上の表より、テキストデータに関してもWGAN-GPによって生成されたサンプルがDG$f$lowによって改良されていることがわかります。
おわりに
いかがだったでしょうか。今回ご紹介したDG$f$lowは、扱う深層生成モデルの種類(GAN,VAE,正規化流)に関わらず生成サンプルの質を底上げしてくれる強力なフレームワークと言えそうです。ただし、勾配流のシミュレーションにおける時間ステップ数はハイパーパラメータとなっており、どのように決めるかは議論の余地がありそうです。手法の名前が$f$-ダイバージェンスの"$f$"と勾配流のflowの組み合わせになっているところがおもしろいですね。
勾配流の数値シミュレーションに関する理論的背景が気になる方は是非元論文を読んでみてください!



この記事に関するカテゴリー






