新たな映像生成システム "DVD-GAN"が登場! ! 2つの識別器と並列化による処理能力!
参考論文 : Efficient Video Generation on Complex Datasets
近年、最もホットな研究分野であるGANは、最新の”BigGAN”や”StyleGAN”などを筆頭に非常にリアルな画像を生成することができており、その画像は高解像で多様性に富んでいます。しかしながら、高解像度の”ビデオ”生成することは依然として挑戦的な分野であり、より複雑なデータ処理と高い計算能力を必要とします。
従来、ビデオ生成の分野における最先端の作業は、タスクの複雑さを軽減するため、比較的単純なデータセット、すなわち強い制約下におけるデータを中心に行われてきました。
今回「Deepmind」により発表された論文”DVD-GAN (Dual Video Discriminator GAN)”では、いくつかのテクニックと画像生成モデルGANを組み合わせることで、最高精度の解像度かつ最長である”256×256の解像度”と”48フレームまで”のビデオを生成することができます。
DVD-GANとは!?
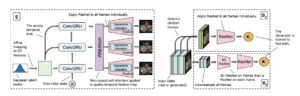
“DVD-GAN”では、トレーニングをスピードアップするためにいくつかのアルゴリズムを導入しながら、GANのアーキテクチャをビデオの世界へと拡張します。
これまでも動画を生成するモデルはいくつかありましたが、DVD-GANの生成器は従来モデルのほとんどに含まれていた”オプティカルフロー”を使用していません。その代わりに、大きな計算容量を保つニューラルネットワークを、データ処理のために利用しています。
より具体的には、「DVD-GAN」は、”self-Attention”と”RNN”を導入しています。RNNは入力動画から各フレームの特徴量を抽出し、self-Attentionを通じて並列化されたResNetにより全てのフレームを(関連性を持って)生成していきます。これにより、全てのピクセルが各フレーム毎に関連性を持って出力されます。
“2つの識別器”と”分離可能self-Attention”
以下では、DVD-GANのモデル構成の中でも特徴的な部分を、
“2つの識別器(Dual- Discriminators)”と”Attention(分離可能self-Attention)”の2つに分けて紹介します。
(1)2つの識別器(Dual-Discriminators)
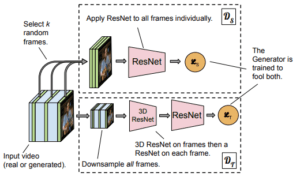
DVD-GANは従来のGANモデルとの最も大きな違いとして、識別器が”Ds : 空間的識別器” と “Dt : 時間的識別器” の2つに分かれている点にあります。生成器は、この両方の識別器を通り抜けるフレームを生成するように学習します。
空間的識別器 Ds :単一のフレームの内容と構成を、ランダムにサンプリングして識別を行う
時間的識別器 Dt :空間的識別器 : Dsでは識別されなかった、フレーム間の動きを生成するための学習信号を、フレーム間の動きがもっとも自然になるように最適化を行い、生成器に戻す
また、モデルをスケーラブルにすることを、フル解像度のビデオ全体を用いることなく実現しています。具体的には、バッチ学習やランダムな補集合のフレームを用いるのではなく、初期化関数Φを導入し、空間的ダウンサンプリングをビデオ全体に行い、その出力を時間的識別器 : Dtに入力します。Φは、2×2の平均プーリングとしての機能を果たします。
これらを用いたアーキテクチャにより、識別器は高画質な画像のビデオを全体処理することはなく、しかし生成器は高画質な画像を処理した場合と同等の結果を出力することが可能になります。
(2)分離可能self-Attention
self-attentionによるモジュールを用いることで、特徴量マップ上の大域的(global)な区間において情報を伝達することを可能にしています。しかしながら、self-attentionは計算量と容量を必要とするため、データ量の大きいビデオには適していません。
今回の例では、横幅 : W・縦幅 : H・時間 : T が特徴量として含まれており、必要な情報量の行列サイズは以下のようになります。
![]()
この問題を回避するために、DVD-GANではより効率的な“分離可能self-attention (Separable self-attention)”を用いています。
分離可能self-attentionでは、同時に全ての必要な特徴量に注目する代わりに、3つの並列なアテンション層を用意し、各フレームの横幅・縦幅・時間にそれぞれ注目します。これにより、メモリ内に保持する行列サイズを以下のように分割し、一度の計算量を減らすことができます。
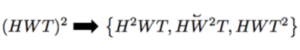
実験結果
“DVD-GAN”の実験では、10秒間のYouTube HDビデオクリップからなる”Kinetics-600データセット”を使用しています。このデータセットには600のカテゴリが含まれており、全部で約50万個のビデオから構成されています。
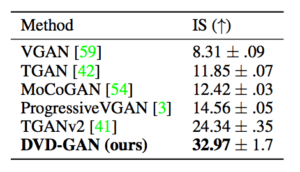
上記は、既存モデルのISスコアとDVD-GANの性能を比較した表になります。ISスコアは生成される画像の精度を指し、大きければ大きいほど優れた画像と言えます。
上表からわかるように、既存モデルであるMoCoGANやTGAN2と比較し、明確に高い質でフレームを生成できることがわかります。しかしながら、リアルな動画を生成するにはまだ不十分と言えます。
以下、実際に生成された動画フレームを見て見ましょう。

上図は、DVD-GANによって生成されたサッカーの動画フレームになります。48フレームの動画を64×64の解像度で生成しています。なんとなく、フィールドやプレイヤーが写っていることはわかりますが、実際のサッカーの動画のようには見えづらいですね。

そのほか上画像のように、DVD-GANは従来のビデオ生成モデルと同様に、ビデオを始点と終点を指定することでその間のフレームを補間することも可能です。0からの生成でなければ、一貫性のある動画フレームを生成できていることがわかります。

実際にDVD-GANを用いてフレーム生成した66個のGIFは上のようになります。各映像を見てみると、細かい部分(例えば、赤ちゃんの顔など)に置いて不自然な部分が見え、自然に撮影された動画でないとこは一目でわかります。
定量的な視点においての進歩はありましたが、例えば画像生成のように人間の目を騙すにはまだまだ多くの課題が残っています。
終わりに
本稿では、大規模なデータセットを計算処理するテクニックを導入したGANをビデオの世界に導入した、ビデオ生成モデル”DVD-GAN”を紹介しました。結果として、“DVD-GAN”は既存モデルと比較し最高精度のビデオを生成することに成功しています。
DeepMindの研究者たちは、完全にリアルなビデオを制約のない条件で生成するにはまだ多くの困難があることを論文で認めつつも、”DVD-GAN”は正しい方向への一歩であると考えています。
画像生成においても、白黒のぼやけた人間の顔の生成モデルから、人間さえも欺くような忠実度の高い肖像画を生成するモデルへの進化には、4~5年かかりました。数年後には、同様にGANによって生成されたリアルなビデオがインターネットにあふれているかもしれません。
ライター個人の意見として、「DVD-GAN(Dual Video Discriminator(2つのビデオ識別器)とDVDをかけている)」を名付けたであろう、論文著者Jeff Donahueのセンスには脱帽です。




この記事に関するカテゴリー






