画像分類における適切なラベル表現とは?
3つの要点
✔️ 音声データをラベルとして利用することで画像分類タスク性能が向上
✔️ 様々なラベル表現を利用した実験・比較
✔️ 高次元・高エントロピーなラベル表現が、ロバスト性・データ効率を高めることを実証
Beyond Categorical Label Representations for Image Classification
written by Boyuan Chen, Yu Li, Sunand Raghupathi, Hod Lipson
(Submitted on 6 Apr 2021)
Comments: Accepted to International Conference on Learning Representations (ICLR 2021).
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:
はじめに
画像分類タスクでは、入力画像に対するクラスの予測を行います。このとき、教師データとなるラベルの表現・形式は、モデルの性能にどのような影響を及ぼすでしょうか?
本記事で紹介する論文では、音声データを始めとした様々なラベルを利用し、ラベル表現がモデル性能にどのように影響を及ぼすかについて様々な検証を行い、先の質問への解答を示しました。
実験
実験設定
・データセット
CIFAR-10/100データセットを利用し、画像分類におけるラベル表現として様々なバリアントを利用して実験を行います。
・音声ラベル
以下に示す手順により音声ラベルを生成します。
- カテゴリに対応するテキストから英語音声をTTS(text-to-Speech)システムにより生成します。このとき、全ての音声ラベルは同じパラメータ・APIで生成されます。
- 各音声ファイルは16ビットのパルス符号変調エンコーディングによりWAVE形式で保存され、両端の無音域はトリミングされます。
- サンプリングレート22,050Hz、周波数64Mel、ホップ長256のメルスペクトログラムへ変換します。
- スペクトログラムを-80~0の値を持つN(入力画像次元の二倍)×Nの行列にし、これをラベルとして利用します。
この音声ラベルは、それぞれのクラスごとに一つずつ対応しています。
・その他のラベル
ラベルのどのような特性がどのような影響を及ぼすのかを調査するため、以下に示す様々なラベルを利用して実験を行います。
- シャッフル音声(Shuffled Speech):音声スペクトログラム画像を時間次元に沿って64個に分割し、それらを並び替えます。この処理は、元の音声ラベルのエントロピーや次元を保持します。
- 定数行列(constant-matrix):全ての要素が同一値の(エントロピーがゼロとなる)次元を利用します。
- 混合ガウス(Gaussian-composition):一様に位置と方向をサンプリングされた10個のガウシアンを組み合わせます。
- ランダム/一様行列(random/uniform-matrix):一様分布からランダムにサンプリングされた要素を持つ行列を生成します。また、次元の重要性の調査のため、次元の低いバリアントも利用します。
- BERT埋め込み(BERT embedding):事前学習済みBERTモデルの最後の隠れ層の埋め込みを利用します。
- GloVe埋め込み(GloVe embedding):BERTモデルと同様、事前学習済みGloVeモデルの単語埋め込みを利用します。
前述した音声ラベルも含めたラベルの可視化例は以下のようになります。

・モデル
モデルには以下に示す三つのCNNを利用します。
カテゴリ分類モデル(ベースライン設定)は、画像エンコーダ$I_e$、カテゴリ(テキスト)デコーダ$I_{td}$からなり、$I_e$は先述したCNNバックボーン、$I_{td}$は全結合層となります。
高次元ラベルを利用するモデルでは、画像エンコーダは同一のまま、ラベルデコーダ$I_{ld}$を代わりに利用します。$I_{ld}$は1つの密な層といくつかのtranspose convolutional層からなります。
学習・評価
カテゴリ分類モデルはクロスエントロピー損失により学習され、高次元ラベル利用時は以下の式を最小化するよう学習されます(Huber損失が利用されています)。
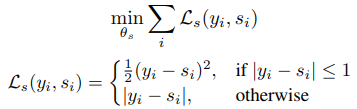
カテゴリ分類モデルは、一般的な分類タスクと同様、最も高い確率を予測されたクラスが対象のクラスと同じであれば、、予測は正しいとみなされます。高次元ラベルについては二種類の形式で測定されます。
- モデルの出力と最も近いground-truthラベルを選択します(NN:nearest neighbor)。
- 真ラベルとのHuber損失(smooth L1 loss)が特定の閾値(実験では3.5)を下回る場合、予測は正しいとみなされます。
実験結果
前述した全てのラベルにおける分類精度は以下の通りです。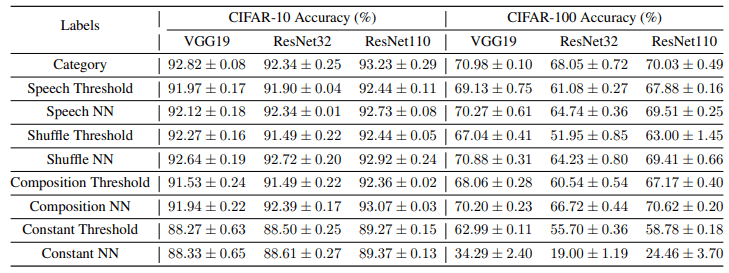
音声ラベル、シャッフル音声ラベル、混合ガウスラベルは従来のカテゴリ分類ラベルと遜色ない性能を示していますが、定数行列ラベルは少し性能が低下していることがわかります。
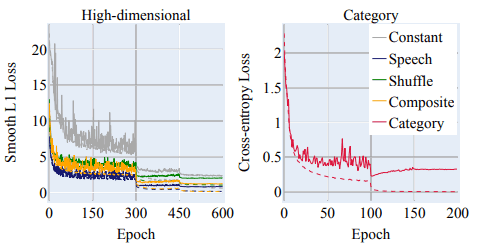
学習曲線は以下の図の通りで、こちらからも定数行列ラベルを利用した訓練の難しさが示されています。
ロバスト性について
モデルのロバスト性の評価のため、FGSMと反復法によるAdversarial Attackを行います。このとき、正しく分類された画像に対してのみ攻撃を実行し、どれだけ性能が維持されるかを調査します。
結果(テスト精度)は以下の図で示されています。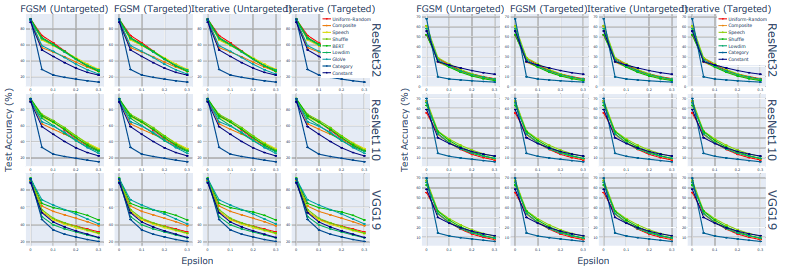
図の左側はCIFAR-10上で、右側はCIFAR-100での実行結果を示しています。攻撃の強さ(横軸:Epsilon)に応じて全てのモデル精度は低下していますが、音声/シャッフル音声/ガウスラベルを用いた場合は、全ての場合において従来のカテゴリラベルより大幅に優れた性能を示しました。
また、一様ランダム行列(Uniform-Random/Lowdim)は低次元の場合でも優れた性能を発揮した一方、定数行列からなるラベル(Constant:紫線)は比較的低い性能となっています。これは、ラベルが高次元であること以外にも、何らかの特性がモデルのロバスト性を向上させていることを示唆しています。
訓練データ効率について
CIFAR-10データセットについて、訓練データの1%、2%、4%、8%、10%、20%のみを利用して学習を行います。このときのテスト精度は以下の通りです。
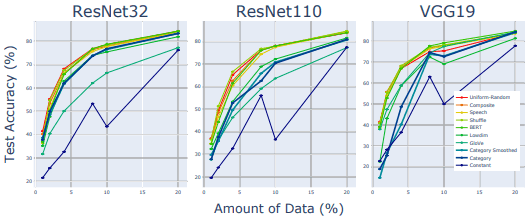
全体として、ロバスト性評価と同じような結果となっています。特に定数行列ラベルの性能は、他の高次元ラベルと比べ低い性能となっており、やはり高次元性以外の何らかの特性が性能に影響しているとみられます。
ただし、低次元の一様ランダム行列(Lowdim)の結果はロバスト性の評価と異なり、高次元行列と比べて劣る結果を示しています。
高次元・高エントロピー表現の有効性
ラベルのロバスト性・データ効率を向上させる、効果的な特徴表現に役立つラベル表現の特性として、論文では「高いエントロピーをもつ高次元ラベル表現」を仮説として提唱しています。
この仮説について、以下の表で様々なラベル表現の統計量を示します。
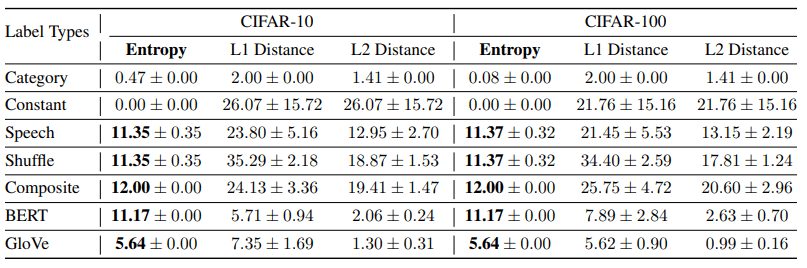
L1/L2 Distanceは、異なるラベルペア間の距離を示しています。
ロバスト性・データ効率にて優れた結果を示したラベル(音声/シャッフル音声/混合ガウス等)のエントロピーは全て、通常のカテゴリラベル・定数行列ラベルと比べて高くなっており、先の仮説を補強する結果を示しています。
特徴の可視化
CIFAR-10上でResNet-110を訓練した場合について、t-SNEを用いて特徴を可視化した結果は以下の通りです。
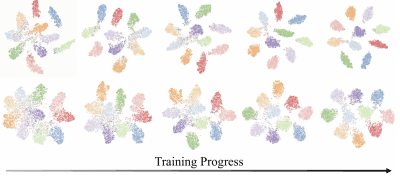
上段は音声ラベル利用時、下段はカテゴリラベル利用時の結果を示しています。また、左から右の順に学習が進んでおり、それぞれ10%、30%、50%、70%、100%学習が完了した状態を示しています。
音声ラベルの特徴表現は、カテゴリラベルと比べ、訓練の初期段階でクラスターが形成されており、訓練が進むにつれてより分離したクラスターが得られていることがわかりました。
まとめ
本記事で紹介した論文では、画像分類タスクにおけるカテゴリラベルを、音声スペクトログラム等の高次元・高エントロピー行列に置き換えることで、優れたロバスト性・データ効率を発揮することを示しました。
ラベル表現がモデル性能に影響することを示したことは、モデルの学習に用いられるカテゴリラベルが果たして有効なのか、という疑問に繋がります。ラベル表現の役割について新たな視点を提供した、重要な研究であると言えるでしょう。
レシピ
Axrossレシピに画像分類に関する実践レシピが公開されています。




この記事に関するカテゴリー






