
2人寄るだけでも文殊の知恵? 〜 2つのモデルが協力し合うDualNetの登場!〜
3つの要点
✔️ 2つの並列DCNNを連携させ、互いに補完的な特徴を学習するDualNetを提案
✔️ 2つのサブネットワークがうまく協調するように、反復学習と共同微調整からなる対応する学習戦略も提案されています。
✔️ CaffeNet、VGGNet、NIN、ResNetに基づくDualNetについて、CIFAR-100、Stanford Dogs、UEC FOOD-100で実験的に評価し、いずれもベースラインより高い精度を達成することを確認
DualNet: Learn Complementary Features for Image Recognition
written by Saihui Hou, Xu Liu, Zilei Wang
Published in: 2017 IEEE International Conference on Computer Vision (ICCV)
code:


本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
近年、深層畳み込みニューラルネットワーク(DCNN)に関する研究が盛んで、様々な視覚課題の性能を著しく向上させています。
DCNNの成功には、ネットワークアーキテクチャの深さと、入力の階層的な表現を学習できるエンドツーエンド学習アプローチが大きく関係していると考えられています。
そうしたことから、DCNNをより高性能にするため、一般的にネットワークはより深く、あるいはより広く設計されています。
本論文では、図1に示すように、画像認識においてより正確な表現を効率的に学習するためのフレームワーク「DualNet」が提案されています。
DualNetは、2つの並列DCNNを連携させ、互いに補完的な特徴を学習することで、画像からより豊かな特徴を抽出することを目的としています。
具体的には、Extractor(特徴抽出器)とClassfier(画像分類器)の2つの論理部分から構成されるエンドツーエンドDCNNのExtractorを並べることで2倍幅のネットワークを構築し、これをDualNetのExtractorとして使用します。
そうすることで、入力画像に対して2つの特徴量のストリームを抽出することができ、それらを集約して統一的な表現を形成し、Fused Classifier(融合型分類器)に渡して全体的な分類を行うことができます。
一方、各サブネットワークのExtractorの後ろには、別々に学習した特徴を単独で識別できるようにするためのAuxiliary Classifer(補助分類器)が2つ付加されており、この3つのClassifierに重み付けをすることで、補完的な制約を課しているのが、まさにDualNetのキーポイントと言えます。
また、この論文では、新たなフレームワークである「DualNet」の他に2つのサブネットワークがうまく協調するように、反復学習と共同微調整からなる対応する学習戦略も提案されています。
本手法は、層幅を単純に2倍にする方法と比較して、メモリコストをあまりかけずに実用的であり、画像認識に大きな改善をもたらすことができる。
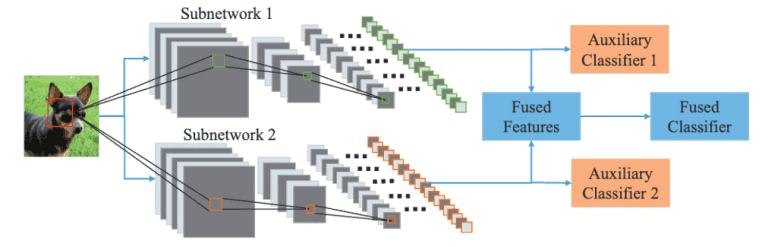 図1:DualNet概要図
図1:DualNet概要図
提案手法
前節でも説明したように、DualNetの特徴は、2つのネットワークを連携させ、入力画像から補完的に特徴を学習することであると言えます。
一方のネットワークにおいて他方で欠けている関心対象の詳細を学習することで、融合後、より豊かで正確な画像表現を抽出し、認識を行うことができるようになります。
特に、DualNetの設計においては、以下の原則に従っています。
- 融合後の特徴は、各サブネットワークで抽出された特徴に比べて最も識別力が高い
- VGGNetやResNetなどの代表的なDCNNや、CIFAR-100などの一般的なデータセットで良好に動作する汎用的なフレームワークであることが必要
- 計算コストの観点から、ミニバッチサイズを小さくすることなく、学習とテストにできるだけ効率的で、Tesla K40 GPU (12 GB メモリ制限) に対応するネットワークであること
- 汎化能力と計算効率を確保するため、SUM、MAX、Concatなどの単純な融合手法のみを考慮し、2つのサブネットの協調・補完性を重視
以下では、DualNetのアーキテクチャとそれに対応する学習方法についてそれぞれ詳しく説明します。
DualNet
DualNetでは2つのモデルをサブネットワークとして用いることで相補学習を行いますが、使用するモデルは既存のどのようなモデルでもよく本論文ではCaffeNet、VGGNet、NIN、ResNetを使用しています。
DualNet From CaffeNet(DNC)のアーキテクチャ例を図2に示します。
ここでは、簡単のために2つのCaffeネットをS1、S2と表記しています。特に、エンドツーエンドのCaffeNetを論理的にExtractorとClassifierの2つの機能部に分割しています。
ExtractorとClassifierの分割は決められたものではなく、理論的にはどの層でも可能ですが、ここではpool5で分割しています。(分割部分をpool5とした理由はいくつか記載がありましたが、ここでは省略します。気になる方は論文を確認してみてください。)
全体として、DNC はS1Extractorと S2Extractorが並列に配置され、それらによって生成された特徴マップがFused Classifierに統合される対称的なアーキテクチャを有しています。
また、各特徴抽出器が生成する特徴を単独で識別できるようにするために、補助的にS1ClassifierとS2Classifierを追加しています。
そして,3つの分類器に重み付けをすることで,相補的な制約を課しています。
融合方法としてSUMを選択したのは、簡単であることと、元のCaffeNetの最後の完全接続層(分類器)のパラメータを引き継ぐためであり、係数は{0.5,0.5}に固定されています。
同様の手法を16層VGGNet、NIN、ResNetに適用しそれぞれDualNet From VGGNet (DNV)、DualNet From NIN(DNI)、DualNet From ResNet (DNR) を構成しました。
DNVにおいてS1 ExtractorとS2 ExtractorはVGGNetのpool5 より前の層で構成されています。
NINと ResNetには完全連結層が存在せず、入力サイズが 32×32 と小さいため、最後の畳み込み層(例えば、NINではcccp5)で2つのサブネットワークの特徴マップを平均化し最後の畳み込み層を予測3としています。
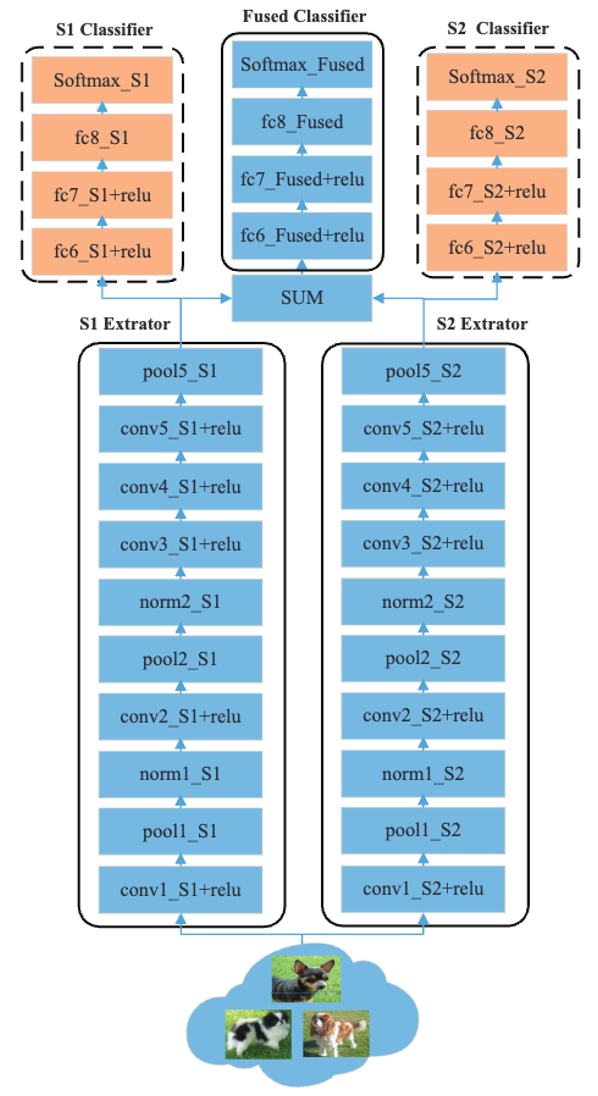
図2:DualNet From CaffeNet(DNC)のアーキテクチャ例
DNCの学習方法
DNCの学習は、図3に示すように大きく反復学習(Iterative Training)と共同微調整(Joint Finetuning)の2つで構成されます。
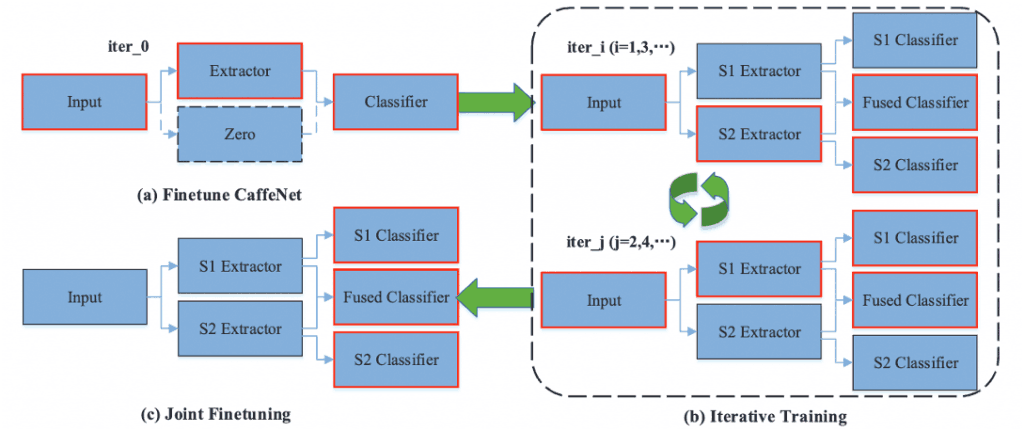 図3:DNCの学習方法
図3:DNCの学習方法
反復学習
反復学習とは、S1 ExtractorとS2 Extractorの間で、一方を固定し他方を微調整することを反復して行うことです。
この方法により、各反復において一方の抽出器に他方の抽出器に対する補完的な特徴を明示的に学習させ、より識別性の高い融合特徴を得ることが可能になります。
反復学習の具体的な方法についてDNCを例に取り説明します。
初めに2つあるサブネットワークのどちらか(ここでは、わかりやすくするためS1とします)のExtractorとFused Classifierを学習します(iter_0)。
ここで、S1 Auxiliary Classiferは省略しているため、学習されません。
学習によって得られたパラメータをS1 ExtractorとFused Classifierの初期値とし、iter_1以降で反復学習を行います。
(iter_i, i=1,3,...)では、S2 Extractor、S2 Classifier、Fused Classifierの学習を行います。
学習中はS1 Extractorのパラメータは固定され、更新されません。
具体的には、S2 Extractor、S2 Classifier、Fused Classifierを含む各モジュールは以下のように定義される損失関数に従って最適化されます。
$L_1=L_{\text {Fused }}+\lambda_{S2} L_{S2}$
ここで、$L_{\text {Fused }}$と$ L_{S2}$はSoftmax FusedとSoftmaxS2によって計算されたクロスエントロピ損失であり、損失重み$\lambda_{S2}$は0.3としています。
第2項は学習の正則化のためにあり、$\lambda_{S2}<1$はS2 ExtractorにFused Classifierが最適化においてより重要であることを知らせるためである。
また、(iter_j, j=2,4,...)では、S1 Extractor、S1 Classifier、Fused Classifierの学習を行います。
学習中はS2 Extractorのパラメータは固定され、更新されません。
具体的には、S1 Extractor、S1 Classifier、Fused Classifierを含む各モジュールは以下のように定義される損失関数に従って最適化されます。
$L_2=L_{\text {Fused }}+\lambda_{S 1} L_{S 1}$
ここで、$L_{\text {Fused }}$と$ L_{S1}$はSoftmax FusedとSoftmaxS1によって計算されたクロスエントロピ損失であり、損失重み$\lambda_{S1}$は0.3としています。
第2項は学習の正則化のためにあり、$\lambda_{S1}<1$はS1 ExtractorにFused Classifierが最適化においてより重要であることを知らせるためである。
こうして学習されたDualNetの評価はFused Classifierの出力をCaffeNetなどのベースモデルと比較することで行います。
また,3つの分類器の予測値を組み合わせることで,各クラスの確率を計算することも可能となっています。
$\textit{score}=\textit{score}_{\text {Fused }}+\lambda_{S 2}\textit{score}_{S 2}+\lambda_{S 1}\textit{score}_{S 1}$
ここで、$\textit{score}_{\text {Fused }}$、 score S2 ,score S1 は,テスト時のFused Classifier, S2 Classifier, S1 Classifierの出力を意味しており、このスコアが認識の評価に用いられる。
共同微調整
DualNetにはS1分類器、S2分類器、Fused分類器の3つの分類器モジュールが存在するが、反復学習のみではそれらの能力が十分に生かされているとは言えません。
そこで本論文では、DualNetの性能をさらに向上させるために、別の統合手法を提案されています。
DNVのようなネットワーク全体の微調整は時間がかかり、大きなGPUメモリを必要とするため、代わりに3つの分類器モジュール(例えば、DNCのfc8、DNIのccp6)の最後の完全接続層を以下の損失関数で共同微調整します。
$L_3=L_{\text {Fused }}+\lambda_{S 2} L_{S 2}+\lambda_{S 1} L_{S 1}$
ここで,$L_{\text {Fused }}$,$ L_{S1}$,$ L_{S2}$ は、それぞれFused Classifier, S2 Classifier, S1 Classifier が出力するクロスエントロピーロスあり、損失重み$\lambda_{S1}$,$\lambda_{S2}$は0.3としています。
実験設定
CIFAR-100,Stanford Dogsなど広く使われている複数のデータセットに対して、DualNet From CaffeNet (DNC), DualNet From VGGNet (DNV), DualNetFrom NIN (DNI), DualNet From ResNet (DNR) の性能を評価します。
反復学習のハイパーパラメータは、特定のデータセットで標準的なディープモデルをファインチューニングする場合と同じであり、共同微調整では、数回の追加反復のために、基本学習率を10分の1に減少させています。
結果と考察
CIFAR100の画像分類に対して、標準的なNINとResNetの精度を提案手法であるDualNet From NIN(DNI)、DualNet From ResNet (DNR) の精度と比較した結果を図4に示します。
図4の表は上からそれぞれ以下の結果を示しています。
ここで、右と左の違いはデータ拡張を適用したかしていないかの違いを示します。
- NINとResNetを使用してCIFAR100の画像分類を行なった結果
- 反復学習を用いて学習したFused Classifierのみの出力によってCIFAR100の画像分類を行なった結果
- 反復学習を用いて学習した3つの分類器の出力を重み付けして合わせた結果を使用してCIFAR100の画像分類を行なった結果
- 反復学習に加え共同微調整を用いて学習した3つの分類器の出力を重み付けして合わせた結果を使用してCIFAR100の画像分類を行なった結果
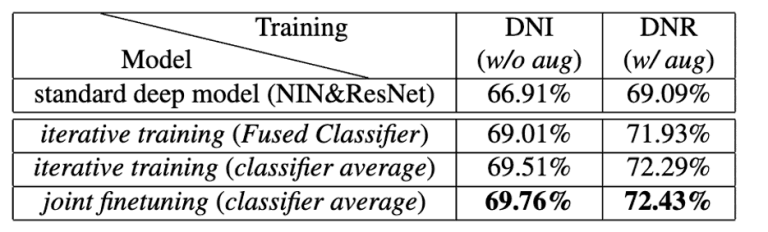 図4:提案手法の評価結果1(CIFAR-100)
図4:提案手法の評価結果1(CIFAR-100)
同様に、CIFAR100の画像分類に対して、既存手法の精度を提案手法であるDualNet From NIN(DNI)、DualNet From ResNet (DNR) の精度と比較した結果を図5に示します。
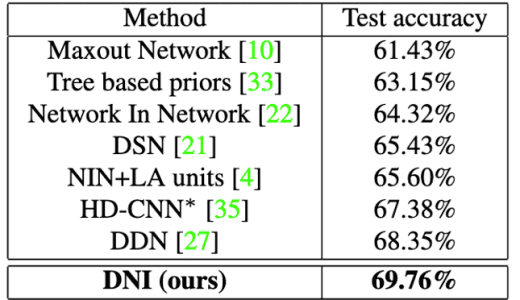 図5:提案手法の評価結果2(CIFAR-100)
図5:提案手法の評価結果2(CIFAR-100)
どちらの結果においても提案手法が最も良い精度を示していることが確認できます。
また、評価結果1において、反復学習に加え共同微調整を用いた方が精度が最も良かったことから共同微調整の有効性についても確認することができました。
続いて、Stanford DogsとUEC FOOD-100の画像分類に対して、標準的なCaffeNetとVGGNetの精度を提案手法であるDualNet From CaffeNet(DNC)の精度と比較した結果を図5に示します。
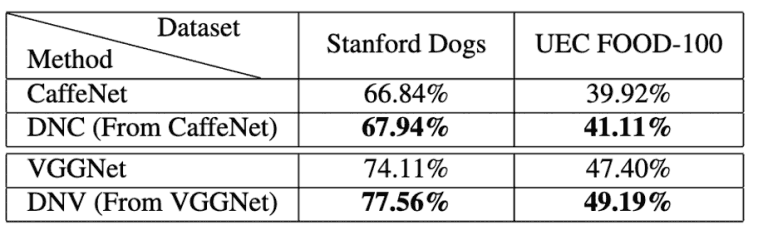 図6:提案手法の評価結果3(Stanford Dogs,UEC FOOD-100)
図6:提案手法の評価結果3(Stanford Dogs,UEC FOOD-100)
どちらのデータセットに対しても、提案手法あるDNCとDNVは良好な性能を示し、CaffeNetとVGGNetよりも高い精度を達成することを確認できました。
まとめ
本論文では、画像認識タスクに対してDualNetと呼ばれる汎用的なフレームワークを提案しました。
このフレームワークでは、2つの並列DCNNが協調して補完的な特徴を学習することにより、より広いネットワークを構築し、より識別性の高い表現を得ることができます。
また、この新たなフレームワークである「DualNet」を最大限活用するために、2つのサブネットワークがうまく協調するよう、反復学習と共同微調整からなる対応する学習戦略も提案されています。
実験では、CaffeNet、VGGNet、NIN、ResNetに基づくDualNetについて、CIFAR-100、Stanford Dogs、UEC FOOD-100で実験的に評価し、いずれもベースラインより高い精度を達成することを確認しました。
特に、CIFAR-100における精度は先行研究と比べ最も良いものとなりました。



この記事に関するカテゴリー






