生成画像を思い通りに!? 生成画像の制御ができる新たなGANフレームワーク"VCGAN"
3つの要点
✔️CGANの生成部分に変分推論を導入した新たなGANのフレームワークを開発した。
✔️定性的、定量的評価によって、最新の既存手法と比較して提案手法が優れていることが判明した。
✔️入力文章が長い場合でも、その文の意味を正しく反映した画像を生成することに成功した。
現在、GANと呼ばれる深層生成技術により、本物と同じぐらいの精度を持つ架空の画像を作成できるようになってきています。しかし、現状のGANにも問題があり、現状では画像そのものを作成することはできますが、生成画像の制御、つまり人間の意図する画像を生成することが困難であるといった問題があります。
今存在しているGANのほとんどは人間の意志に無関係に画像が生み出されてしまっています。
生成画像の制御を目的として提案された手法には現状、大きく分けて二つ存在します。一つは自然言語に基づく画像生成であり、もう一つはConditional-GAN(CGAN)に代表される画像のクラスラベルに基づく画像生成です。
しかし自然言語を直接利用する方法は、文章の理解の面で困難があり、例えば、”This bird is red and brown in color, with a stubby beak” のような単調な文章からしか目的に合った画像を生成することができません。
クラスラベルを利用するCGANのような方法は、入力ノイズとラベルのデータ構造のミスマッチの問題より、出力画像が不明瞭になってしまうといった問題が発生しています。
本研究では、生成画像の潜在変数獲得部分に変分推論を導入することで、現状の問題を解決し、ある程度人間の意図を反映した画像を生成することができる新たなGANのフレームワーク、Variational Conditional GAN(VCGAN)を提案しました。
提案手法
変分推論
ここで、本論文の肝となる技術である、「変分推論」についての説明をしていきたいと思います。
変分推論とは一言で言うと、確率分布を近似的に求める方法です。
一般的に確率分布は最尤法などの手法を使って求めますが、確率分布が複雑な形になってしまうと解析的に求めることはほぼ不可能になります。
その問題を解決するために、元の確率分布を単純化した別な確率分布を別に定義し、その分布を元々の確率分布に近づけることで、近似的に求めたい分布を求める方法が変分推論です。
以上の内容を数式で表現すると次のようになります。

本研究では,上述した「変分推論」を導入することで,クラスラベルに基づく画像生成を、条件付き尤度関数の最大化問題に置き換えることで、生成器の潜在変数の確率分布を求めるように学習を行います。
問題設定
最終的には次の数式を目的関数とし、この尤度関数を最大化させるように学習を行います。

フレームワーク
本研究で提案されるVCGANのフレームワークは次の図で表すことができます。

この図を参照しつつ、VGGANフレームワークの簡潔な説明をしていきます。
1. はじめのEncoderネットワークでは、まずノイズφ、ラベルcを受け取り、それらを潜在変数zとしてエンコードします。
2. Decoderネットワークでは、潜在変数zが与えられた実画像xの分布を学習するように設計されています。
3. Discriminatorネットワークでは、1、2のEncoder-Decoderネットワーク(本研究での提案手法、変分推論によるフレームワーク)によって生成された画像と本物画像との判別を行います。
Encoder-Decoderネットワークの構造は、VAEの構造と共通している部分があるので、VCGANはVAEとGANのハイブリッドモデルということもできます。
実験結果
続いて、実際にこちらのフレームワークを実際の画像に適用していった結果を述べていきます。
本研究で用いたデータは、以下の表にも示したようにCIFAR10、FASHION-MNIST、CUB、Oxford Flowerの4種類です。
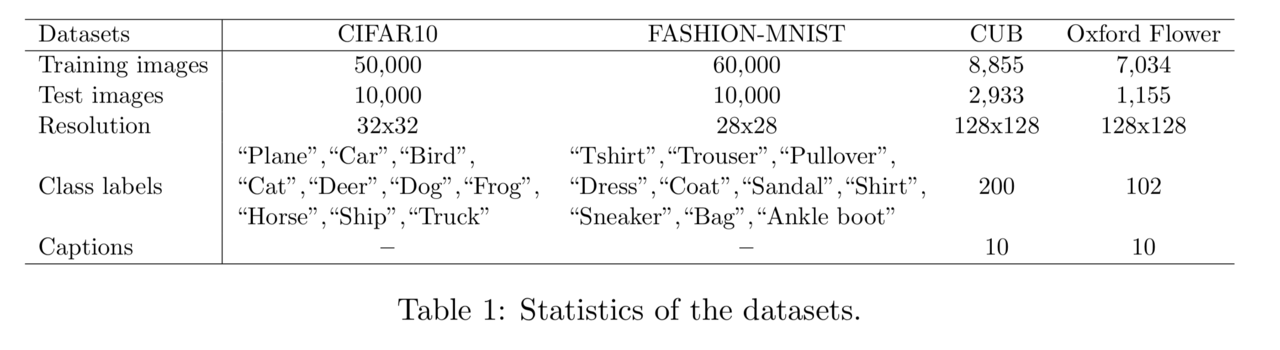
実際に使用した画像の例を以下に示します。左がCIFAR10、右がFASHION-MNISTです。

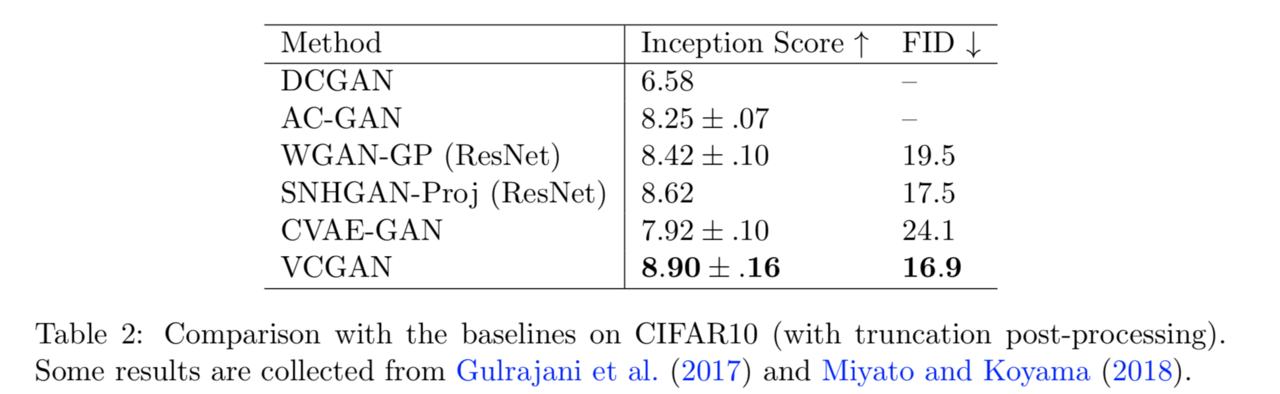
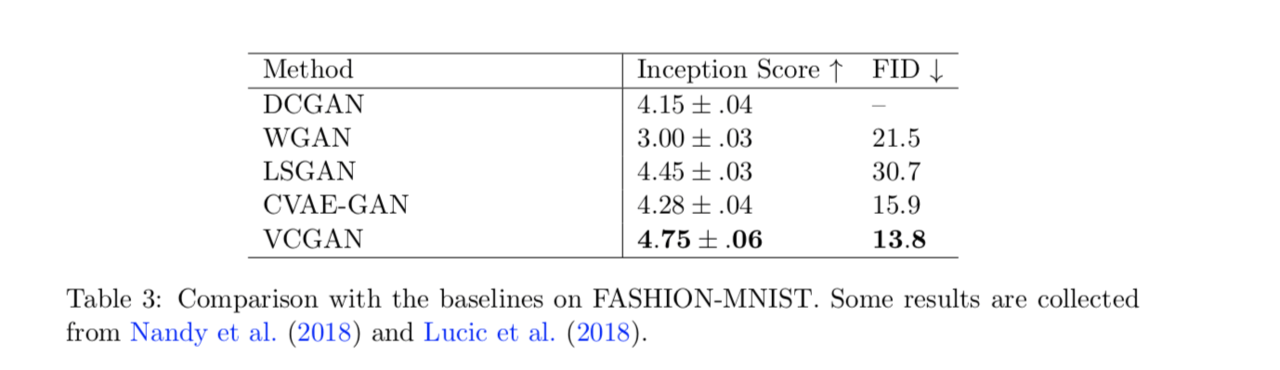
提案フレームワークの評価指標として、Inception score (IS)、Frechet Inception distance (FID)を用いました。また、性能評価のための既存手法として、DCGAN、LSGAN、AC-GAN、WGAN、WGAN-GP、CVAE-GAN、SNHGAN-Projを使用しました。
これらの手法に関して、性能比較を行った表を以下に示します。この表より、両方の指標において提案手法が最も優れていることが確認できます。
次に、提案手法を用いて、クラスラベルより画像を生成した結果の評価を行いました。以下の画像は、CIFAR10で、クラスラベルとノイズの両方を入力にした場合の生成画像の比較となっております。
使用した手法は上から順に、
(a) CVAE
(b) Concat-CGAN
(c) CBN-CGAN
(d) CVAE-GAN
(e) VCGAN
が対応しています。
この結果を見ても、VCGANがもっとも鮮明な画像を生成することに成功していることが確認できます。
最後に、こちらのVCGANを用いて、文章よりその文の意味を反映した画像を作成することを試みていきます。
文章を画像に変換する場合、クラス条件に基づくタスクとは異なり、文章を条件付きベクトルに変換する必要があります。
今回は、VCGANに入力する前に、 hybrid character-level convolutional-recurrent network を利用することで、文章を1024次元に圧縮しました。
その結果を次の図に示します。
この結果を見ても、長い文章でもその文章の意味を反映した画像が生成されていることがわかります。
結論
本研究では、生成器に変分推論を導入することで、入力されたクラスラベルの深い意味を反映し、かつ多様性に富み、鮮明な画像を生成する新しいGANフレームワークを提案しました。既存手法との比較により、クラスラベルに基づく生成においては最高の性能を示すことが確認できました。また、文章よりその意味を正しく反映した画像を作ることにも成功しています。今後の展開としては、一つの文章より、その文章の意味を反映した多様な画像を生成することが期待されています。
Variational Conditional GAN for Fine-grained Controllable Image Generation
Mingqi Hu、Deyu Zhou、Yulan He
accepted by ACML 2019




この記事に関するカテゴリー






