TAPAS:表形式データ上の推論を行う言語モデル
3つの要点
✔️ 表形式データに対する質問回答を行う言語モデルTAPASを提案
✔️ テキスト-表のペアからなる大規模なデータセットを使って事前学習し,セマンティックパーシングデータセットでfine-tuning
✔️ セマンティックパーシングタスクにおいて,既存手法以上の性能を示した
TAPAS: Weakly Supervised Table Parsing via Pre-training
written by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno, Julian Martin Eisenschlos
(Submitted on 5 Apr 2020 (v1), last revised 21 Apr 2020 (this version, v2))
Comments: Accepted to ACL 2020
Subjects: Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Machine Learning (cs.LG)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
導入
表形式のデータに対する自然言語での質問への応答問題は,これまで,セマンティックパーシングの問題として扱われてきました.(セマンティックパーシングとは,質問文を論理演算に置き換える処理のことです.)この問題を教師あり学習で扱う際には,アノテーションデータの不足が課題となっていました.
本論文では,表形式データ上で推論を行い,質問に回答できる弱教師あり学習モデルTable Parser (TAPAS)を提案します.
モデル実装
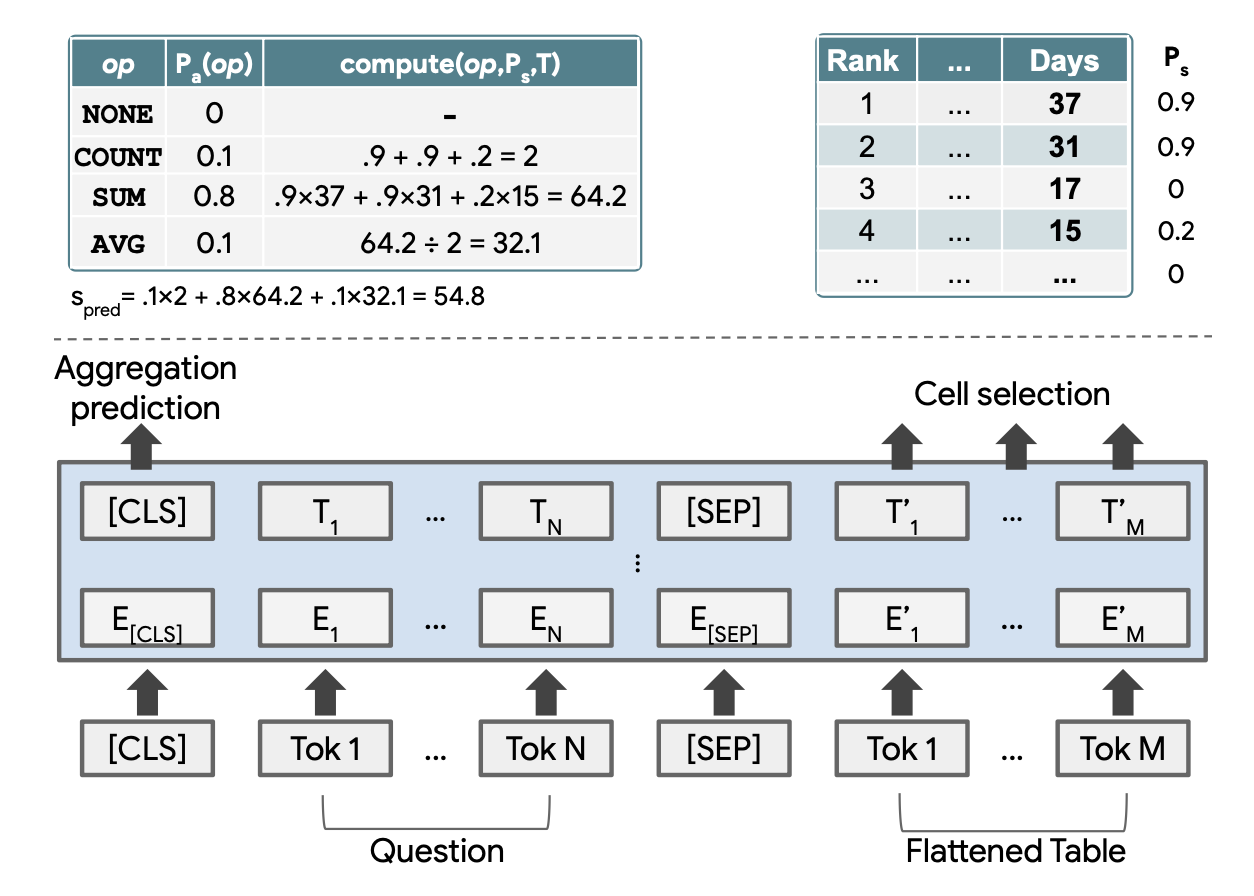
上の図が提案モデルの処理の概要図です.
テーブル構造をエンコードするために,BERTのエンコーダモデルに独自のポジショナルエンコーディングを追加した構造になっています.
表形式を単語の系列に平滑化し,質問文と連結して入力します.出力部分には,操作対象のセルを選択するための出力層と,演算処理を予測するための出力層を追加しています.
追加のポジショナルエンコーディングについて
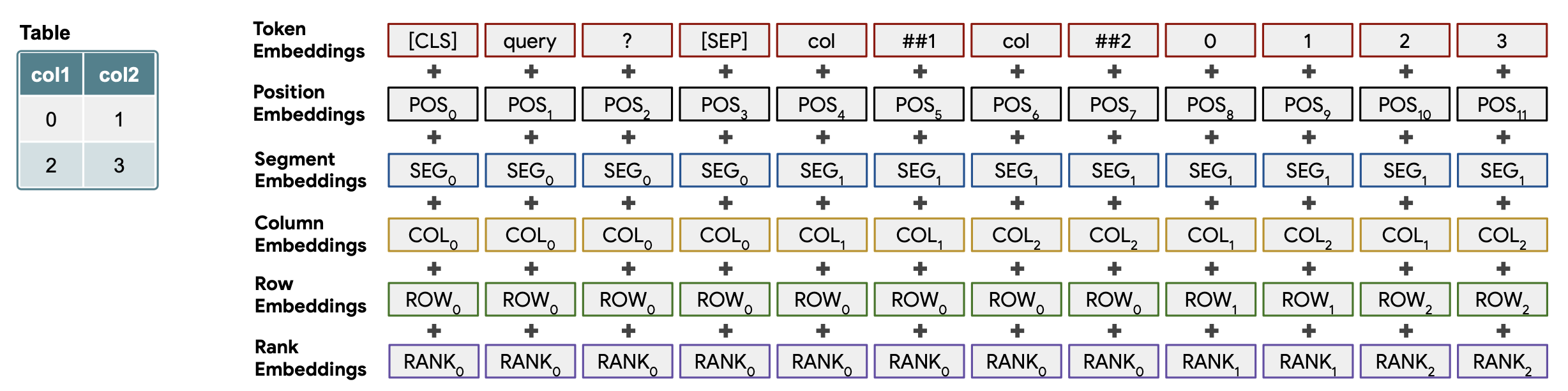
上の図のように,単語や表のデータの系列(Token Embeddings)に加えて,複数のエンべディングが追加されています.
Position Embeddings
BERTと同様の,系列中における位置のエンべディングです.
Segment Embeddings
質問文と表形式データを区別するためのエンべディングです.前者が0,後者が1に対応しています.
Column Embeddings / Row Embeddings
表中の行や列のインデックス(1から始まる)を表すEmbeddingsです.質問文に対しては0を対応させます.
Rank Embeddings
表の列データが浮動小数点数か日付である場合,昇順で序列を付与します.比較できない数値に対しては0を,最小値から小さい順に1から番号を付与していきます.これは,数字データを言語情報として直接比較するのは難しいという問題に対する対策です.
Previous Answer
対話形式で質問と回答が繰り返されている際に,直前の質問や回答に言及する際に用いられるエンべディングです.回答には1を,それ以外には0を割り当てます.
セルの選択のための出力層について
演算子に与えられる,操作対象のセルを出力する部分です.
各セルは独立したベルヌーイ変数としてモデル化され,そのセルが選ばれる確率を出力します.確率が0.5より大きいセルが選択されます.
演算処理を予測するための出力層について
SUM(合計),COUNT(カウント),AVERAGE(平均),NONEなどの操作を出力します.
事前学習
TAPASモデルをWikipediaの大規模な表形式データを使用して事前学習しておきます.
そのためにWikipediaからテキストと表形式データのペアを抽出してデータセットを作成します.
質問文の代わりとして,テーブルのキャプションや記事のタイトル,記述などを使用します.
このデータを使用して,Masked language modelタスクを目的として訓練させます.
Fine-tuning
訓練データセットは$N$個のサンプルからなるとします.そのサンプルとは,表形式データ$T$,質問文$x$と,その答え$y$からなるペア$(x, T, y)$です.
モデルの目的は,表形式データ$T$と質問文$x$が与えられた時に,適切なセルを選択し,適切な演算$z$を施して,正しい回答$y$を出すことができるようになることです.
以下では,タスクごとに詳細に解説していきます.回答$y$は,選択するべきセルの座標$C$と正解スカラー値$s$のタプルとして記述されるとします($y = (C, s)$).
セル選択
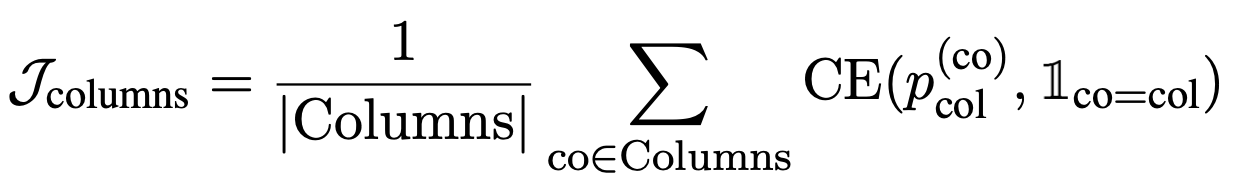
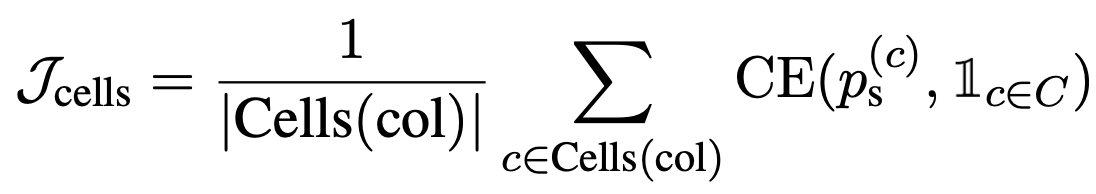
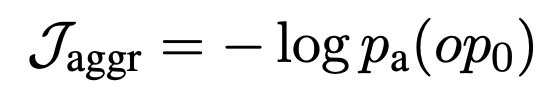
適切な列と適切なセルを選択したかを表す損失$\mathcal{J}_\mathrm{columns}$,$\mathcal{J}_\mathrm{cells}$に加え,適切な演算NONEを選択しているかを表す損失$\mathcal{J}_\mathrm{aggr}$を合計した損失$\mathcal{J}_\mathrm{CS} = \mathcal{J}_\mathrm{columns} + \mathcal{J}_\mathrm{cells} + \alpha \mathcal{J}_\mathrm{aggr}$を用いて,最適化を行います.
スカラー値での回答
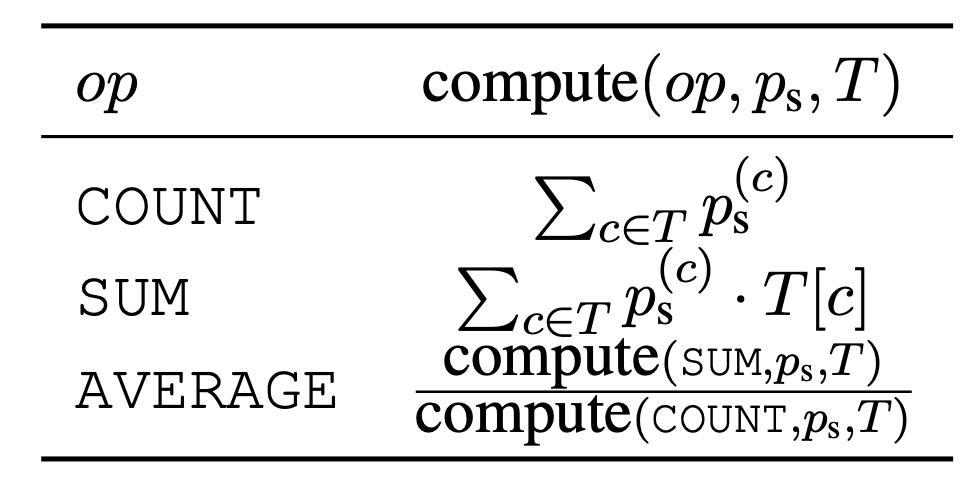
上の表のように,各種演算(COUNT, SUM, AVERAGE)を微分可能な形で表現します.
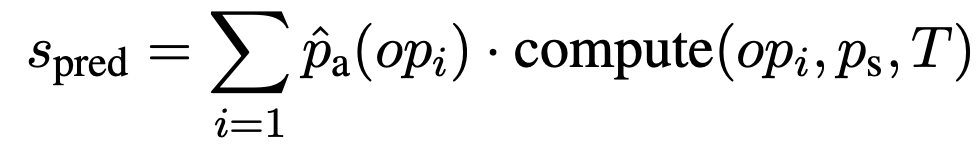
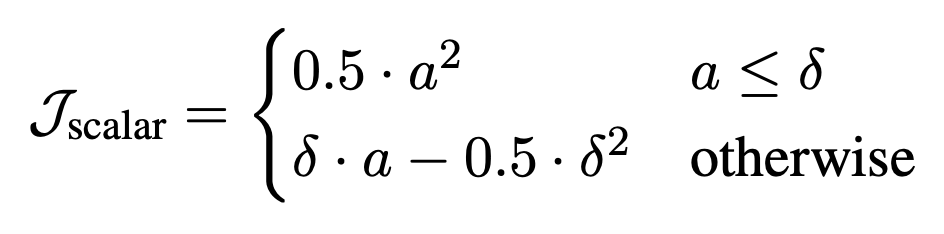
そして,選択したセルに対して選択した演算をかけた結果$s_{\mathrm{pred}}$と正解スカラー値$s$の差分の絶対値を$a$とし,演算結果のスカラー値が適切かを表す損失を$\mathcal{J}_\mathrm{scalar}$として計算します.
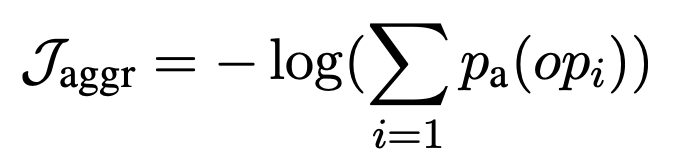
さらに,適切な演算を選択しているかを表す損失$\mathcal{J}_\mathrm{aggr}$を計算し,二つの損失を合計した損失$\mathcal{J}_\mathrm{SA} = \mathcal{J}_\mathrm{aggr} + \beta \mathcal{J}_\mathrm{scalar}$を用いて最適化を行います.
実験
データセット
次の3つのセマンティックパーシングのためのデータセットを複数使用して実験しました.
WIKITQは,Wikipediaから得られた表データに対して,様々な質問文と回答が付与されたデータセットです.
SQAは,WIKITQの質問を分解し,シンプルな問題に置き換えたデータセットです.
WIKISQLは,SQLに対する操作と質問文を格納したデータセットです.
実験設定
32000単語からなる語彙のトークナイザー(標準的なBERTのトークナイザー)を使用します.BERT-Largeモデルから,事前学習・Fine-tuningを始めました.
実験結果
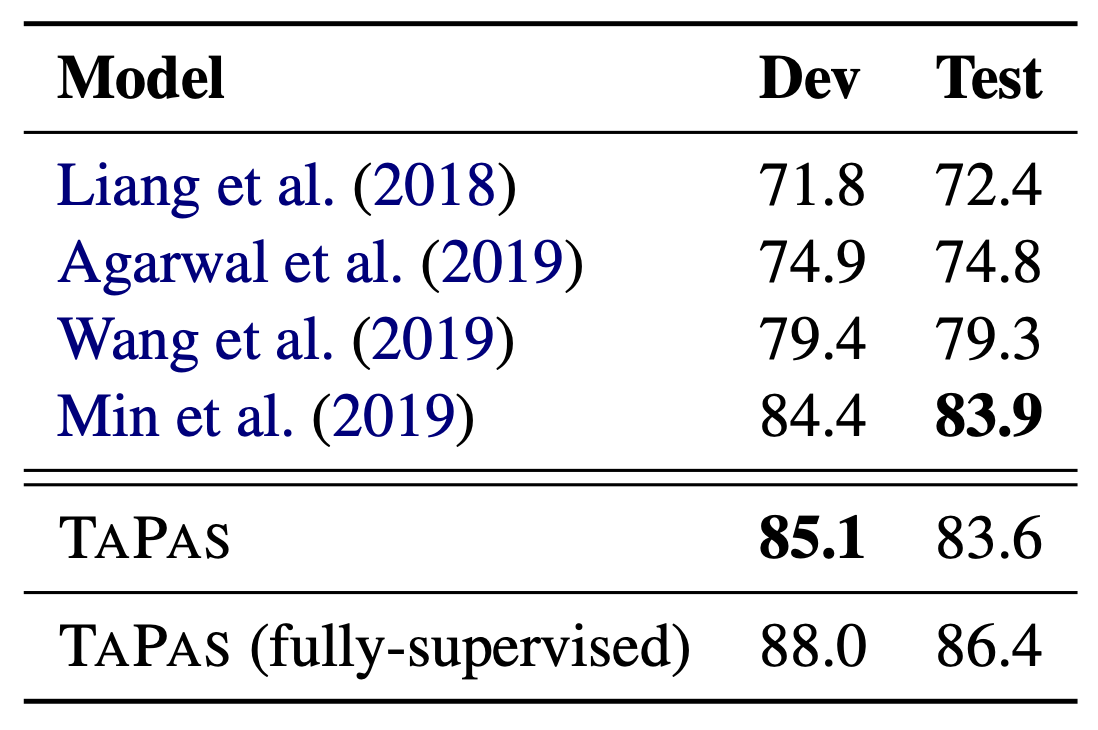
上の表はWIKISQLに対するパフォーマンスです.TAPASはState-of-the-artの手法と同程度のパフォーマンスを示していることがわかります.
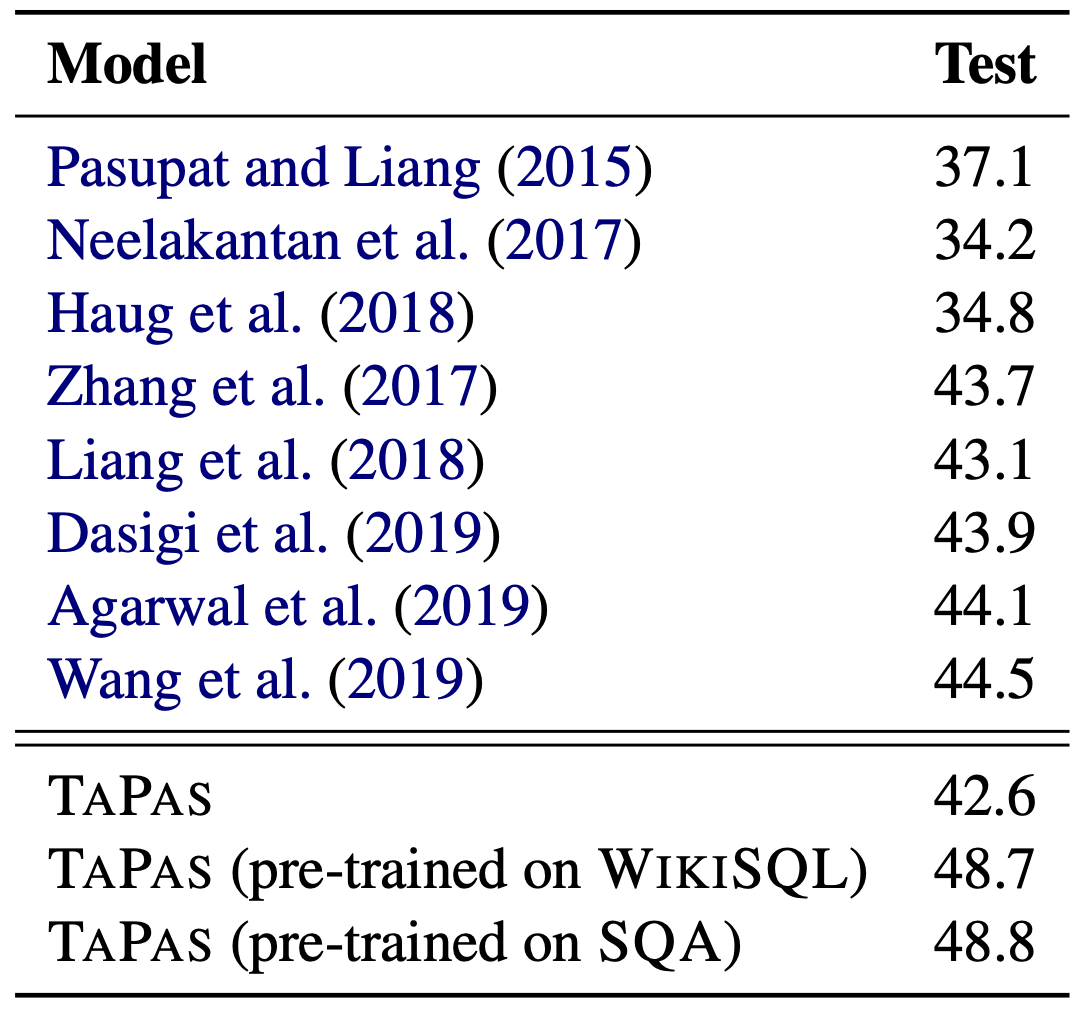
上の表はWIKITQに対するパフォーマンスです.TAPASをWIKISQLやSQAで事前学習させると,最も高いパフォーマンスを示すことがわかります.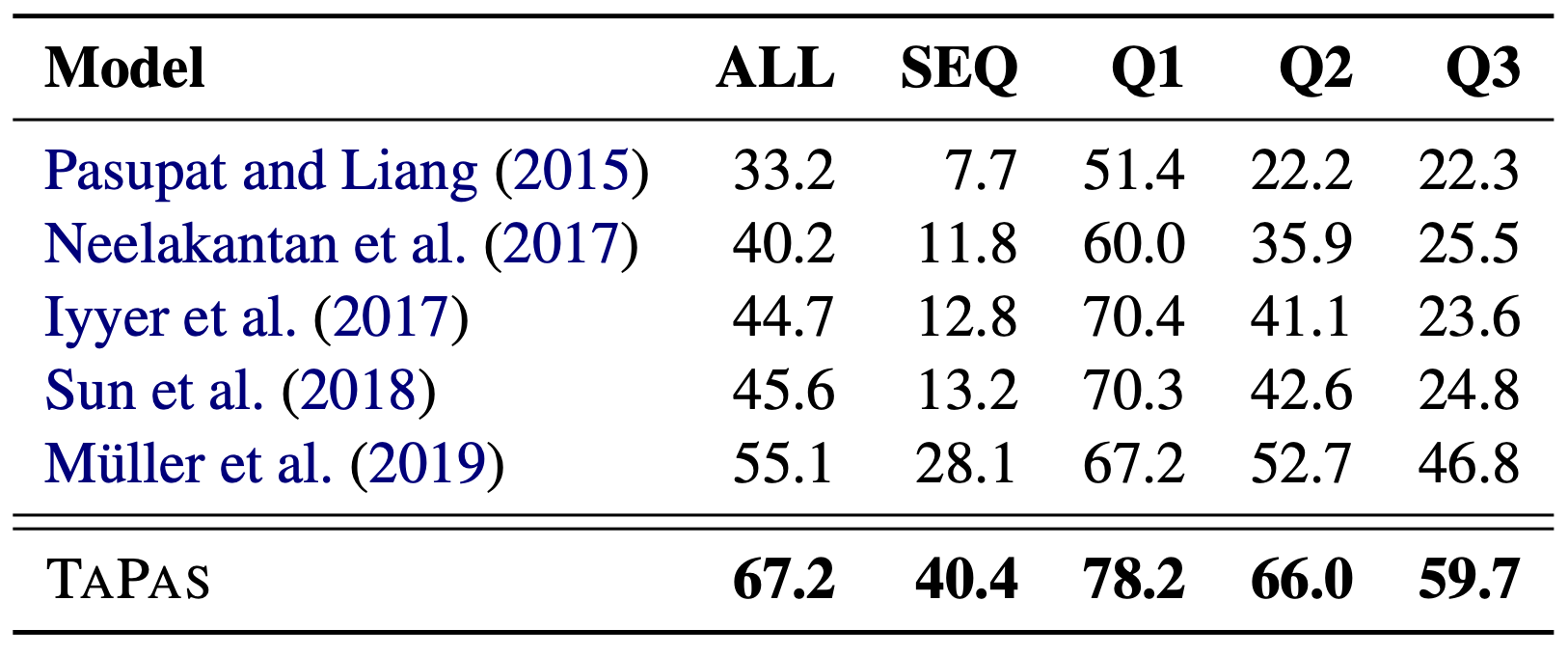
上の表はSQAに対するパフォーマンスです.TAPASがどの指標においても,最も高いパフォーマンスを示しているのがわかります.
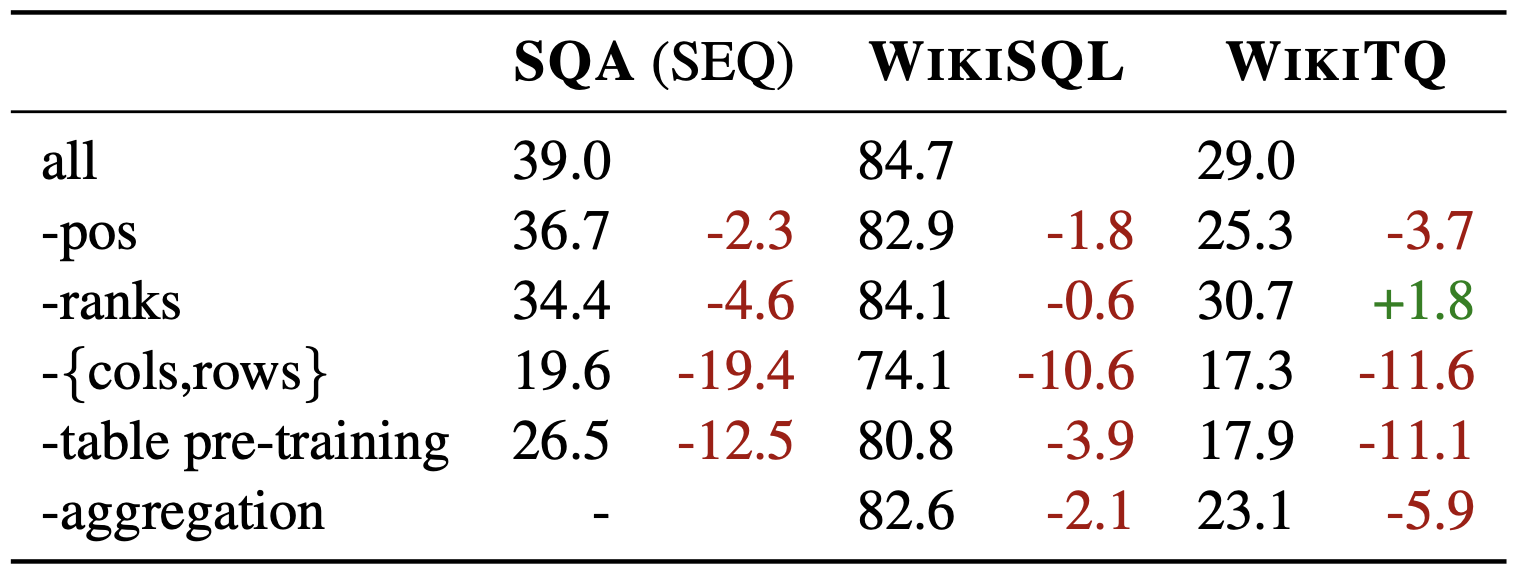
上の表は,各エンべディングや事前学習などを省くことでどのような性能の下落が見られるかをアブレーションスタディで示した結果です.
表形式データセットでの事前学習や,列や行の位置エンべディングが性能の向上には重要であったことが読み取れます.
限界
本論文で提案された手法は,単一の表形式データを文字列化してモデルに与えるものであるため,扱える表形式データのサイズに限界がある上,複数の表を含んだデータに対しては適用できません.また,定式化の都合上,平均値の比較など,2ステップ以上の処理を要する複雑な処理は扱えません.
まとめ
今回ご紹介したモデルTAPASはBERTベースのモデルで,タスクに特化したfine-tuningが必要なものの,表形式データを効果的にエンべディングする方法を提案したものでした.この分野の今後のさらなる発展が期待されます.






この記事に関するカテゴリー





