
分類器の出力確率は信用できるのか?calibration性能を向上させる損失関数「AdaFocal」
3つの要点
✔️ Focal Lossのハイパーパラメータγを適応的に調整するAdaFocalを提案
✔️ 既存手法と比べ、同等の分類性能を保ちながら高いcalibration性能を達成
✔️ 分布外検出タスクにおいても有効性があることが確認された
AdaFocal: Calibration-aware Adaptive Focal Loss
written by Arindam Ghosh, Thomas Schaaf, Matthew R. Gormley
(Submitted on 21 Nov 2022 (v1), last revised 16 Jun 2023 (this version, v2))
Comments: Published in NeurIPS 2022.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
code:
本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
データがどのカテゴリに属するかを推定する分類問題は、機械学習が活用される代表的なタスクの一つです。例えば、画像に映っているものが犬なのか猫なのかを判別する問題が考えられます。この問題に対して、機械学習モデルでは犬である確率と猫である確率を算出し、確率が大きい方が映っているものだと判断します。様々な分類問題において、機械学習モデルは90%以上の分類性能を達成してきました。
しかし、分類の際に用いられた確率は正しいものなのでしょうか?
例えば、「90%犬である」と判断されたサンプルを集めると、本当にそのうちの10%は犬ではないという結果が得られるのでしょうか?近年、分類器の出力確率を正しい確率に一致させるcalibration problemに関する研究が進められています。Focal Lossはcalibrationを改善する手法の一つです。この論文ではさらなるcalibration改善を目指し、Focal Lossを改良したAda Focalを提案しています。
Calibrationの評価方法
ここではcalibration problemにおける評価指標について説明します。
有限のデータセットでは、厳密にcalibration誤差(calibration error)を求めることはできません。そのためcalibration errorの推定値を用いて評価することになります。様々な推定の仕方がありますが、ここではこの論文で主に用いられているExpected Calibration Error(ECE) について説明します。
![]()
ECEは近い確率を持つサンプル群ごとでcalibration errorの計算を行い、その総和をとることで得られます。Mはサンプル群の個数[1]、Nは全(評価)データ数を表します。
Biはi番目のサンプル群に含まれるデータ集合を表しています。ECEEMでは以下の式のように、すべてのサンプル群の個数が同じになるように分けます(EM:Equal Mass)。
![]()
Aiはサンプル群Biにおける正解率を表しています。
![]()
Ciはサンプル群Biにおける平均確率を表しています。
![]()
Focal Loss
提案手法(AdaFocal)のベースである、Focal Lossについて説明します。
概要
Focal Lossは当初、Cross Entropy Lossにおいて簡単に分類できているサンプル(easy sample)に対する学習重みを減らし、分類が難しいサンプル(hard sample)の集中的な学習を可能にすることで、分類器の性能を向上させる目的で提案されました。Focal Lossは数式で以下のように表せます。
![]()
数式を見ると、Cross Entropy Lossの -logp に (1-p)γをかけた形になります。 pが1に近い(easy sampleである)ほど (1-p)γの値が小さくなるため、相対的にhard sampleの重みを大きくすることができることがわかります。γはeasy sampleとhard sampleの重みの違いを調整するハイパーパラメータであり、γ=0でCross Entropy Lossと同じになります。
Calibration特性
その後Focal Lossはcalibrationを改善する効果があることも示されました。その理由は以下の関係式を用いて説明することができます。
![]()
上の式からFocal Lossを減少させると、KL Divergenceを小さくし、予測ベクトルpのエントロピーが増加することが分かります。そのため、モデルが過信して間違った予測をすることを防ぐことができ、calibrationが向上すると考えられています。
課題
Focal Lossの課題はハイパーパラメータγをどのように決めるかという点にあります。
下の図はCIFER-10においてResNet50をCross Entropy Loss(CE:γ=0)、Focal Lossのγ=3,4, 5(FL-3/4/5)、モデルの予測結果に応じてγを変化させるSample-Dependent Focal Loss(FLSD-53)[2]で学習させたときのcalibrationの精度を比較しています。(a)は上で説明したcalibrationの評価指標の一つであるECEEMによる全体的な評価、(b)は予測確率が低い(Bin-0)、真ん中(Bin-7)、高い(Bin-14)サンプル群におけるcalibration誤差のepochごとの変化をそれぞれ示しています。
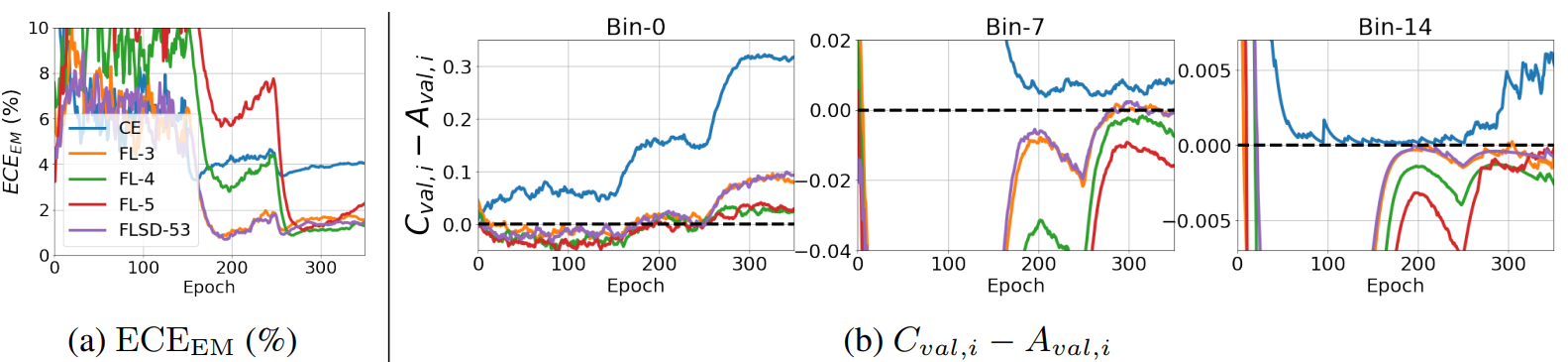
γを固定した(CE, FL-3/4/5)中で比較すると、(a)のグラフから全体的にはγ=4のときが最も良いcalibrationとなっていることがわかります。しかし、(b)を見ると予測確率の大きさによってはγ=4が最良でないことがわかります(Bin-7)。すなわちcalibrationにおいて適切なγを1つに定めることは難しいと言えます。
また、予測確率の大きさに応じてγを変化させるFLSD-53もBin-0, 7, 14のすべての場合で最良の結果とはなっていません。
これらの結果から予測確率の高さごとにより適切な方法でγを定めることが必要だと言えます。
提案手法
AdaFocalではFocal Lossに加えて、Inverse Focal Lossとうまく切替えながら学習を進めます。Focal Lossについては上で説明しましたが、Inverse Focal Lossについては説明していないので、AdaFocalの説明に移る前に説明します。
Inverse Focal Loss
Focal Lossはeasy sampleに対する重みを小さくすることで、モデルが過信して間違った予測をすることを防ぐ効果があることを上で説明しました。逆にモデルが自信不足の場合はどうすればよいのでしょうか?
この論文では、モデルの自信不足の解消にInverse Focal Lossを用いることを提案しています。Inverse Focal Lossは以下の式で表されます。
![]()
Focal Lossでは(1-p)だった項をInverse Focal Lossでは(1+p)に変更しています。これにより、Focal Lossとは逆にeasy sampleに大きな勾配を与え、モデルをあえて過信させるように学習させることができます。
AdaFocalでは、Focal LossとInverse Focal Lossを適切に使い分けることで過信しすぎず、自信不足でもない、ちょうどいい確率を出力するモデルになるように誘導しながら学習を進めます。
AdaFocal ~γの更新方法~
Focal Lossの課題であったハイパーパラメータγをAdaFocalではどのように調整するかを説明します。AdaFocalのγの更新式は以下の通りです。
![]()
AdaFocalではvalidationデータで観測されるCalibration ErrorであるEval, b = Cval, b - Aval, bを基にγを調整していきます。その際、前のepochでのγt-1に依存させることで、γが急激に変化するのを防ぎます。γtは出力確率が近いものを集めたサンプル群ごとに計算しており、bはそのサンプル群のインデックスを表しています。λは1回の更新(epoch)ごとにどれくらいγを調整するかを決めるハイパーパラメータです[3]。
γの更新式は以下に示す考え方を基に設計されています。
- Cval, b - Aval, b > 0 (Cval, b > Aval,b)のとき:
モデルの出力確率が実際の正解率を上回る傾向がみられるので、モデルの過信を抑制するように学習させます。そのため、easy sampleに対する重みが小さくなるように、γを増加させます。 - Cval, b - Aval, b < 0 (Cval, b < Aval,b) のとき:
モデルの出力確率が実際の正解率を下回る傾向がみられるので、モデルを過信させるように学習させます。そのため、easy sampleに対する重みが大きくなるように、γを減少させます。
また、γtを展開すると次のように表すこともできます。![]()
この式から、epoch数(t)が増えるとγtの値が爆発しやすい性質があることがわかります。そのため、γtに上限(γmax)と下限(γmin)を設けて爆発を防いでいます[4]。
AdaFocal ~Focal LossとInverse Focal Lossの切り替え~
γを減少させていくとhard sampleへの重みよりも小さなeasy sampleの重みが(相対的に)だんだんと大きくなっていきます。γが0になる(Cross Entropy Loss)と重みが同じになります。さらにγを小さくなった場合を考えると、hard sampleへの重みに対して、easy sampleに対する重みが大きくなっていくのが自然ではないでしょうか。そのためγが負になるところでInverse Focal Lossに切り替えます。すなわちγ > 0のときはパラメータγのFocal Loss、 γ < 0のときはパラメータ|γ|のInverse Focal Lossで学習します。
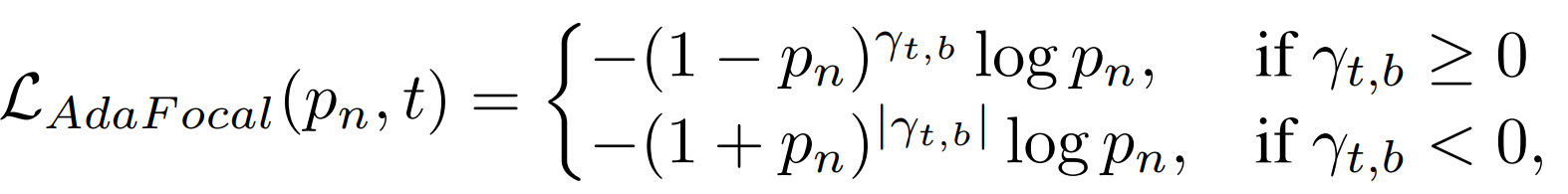
ただし実際に学習する際はγの正負が変わらなくても、|γ|がしきい値Sthを下回った場合にFocal LossとInverse Focal Lossを切り替えるようにしています[5]。
AdaFocal ~まとめ~
ここまで説明してきたAdaFocalのアルゴリズムをまとめると以下のようになります。
実験
分類問題におけるCalibration性能の検証
画像分類(CiFAR-10、CiFAR-100、Tiny-ImageNet、ImageNet)とテキスト分類タスク(20 Newsgroup dataset)において提案手法の性能評価を行っています。画像分類タスクではResNet50、ResNet100、Wide-ResNet-26-10、DenseNet-121、テキスト分類タスクではCNNとBERTをそれぞれ用いています。ベースラインにはCross Entropy Loss(CE)と上で説明したsample-devepdent focal loss(FLSD-53)に加え、他のcalibration学習手法として、MMCE、Brier loss、Label smoothing(LS-0.05)を用い、AdaFocalと比較します。さらに温度スケーリングありとなしの場合で比較を行っています。
ECEEMでそれぞれの手法を評価した結果は以下の表のとおりです。
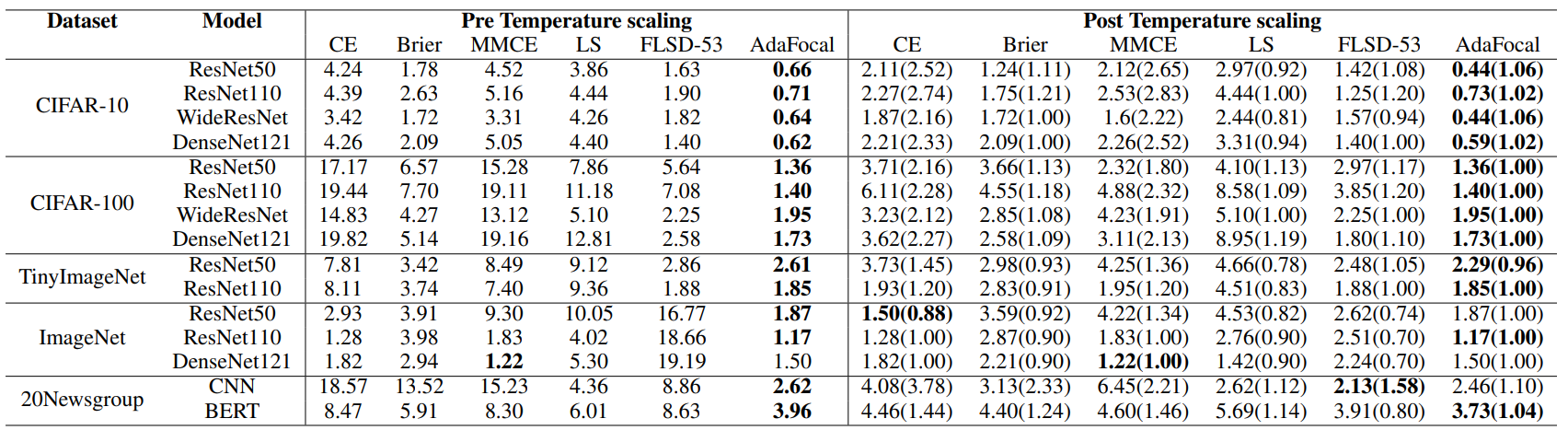
ほとんどのデータセット、モデル、実験設定においてAdaFocalが最も良い性能を示していることがわかります。
以下のグラフは分類におけるエラー率とECEEMのepochごとの変化を可視化したものです。
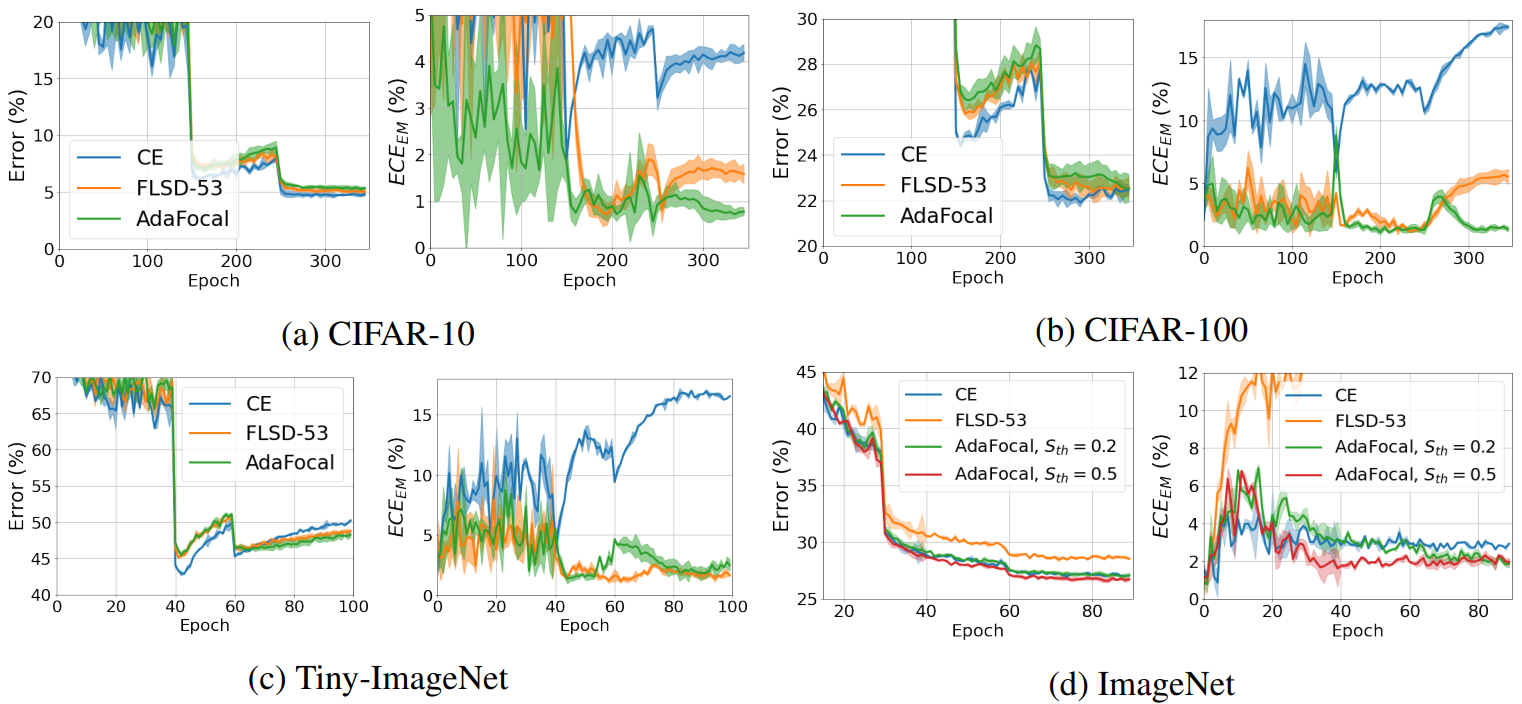
これらのグラフからAdaFocalはその他の手法と同等の分類性能を保ちながら、低いcalibration errorを達成できていることがわかります。
分布外検出タスク(Out-of-Distribution detection)
この論文ではOut-of-Distribution (OOD) detection task[6]においてもAdaFocalの検証を行っています。SVHNとCIFAR-10にガウシアンノイズを加えたデータセットに対して、ResNet-110とWideResNetで学習した結果を比較しています。比較手法はFocal Loss(γ=3)とFLSD-53です。これらの手法は温度なしと温度ありで実験を行っています。
以下のグラフはROC曲線の結果です。
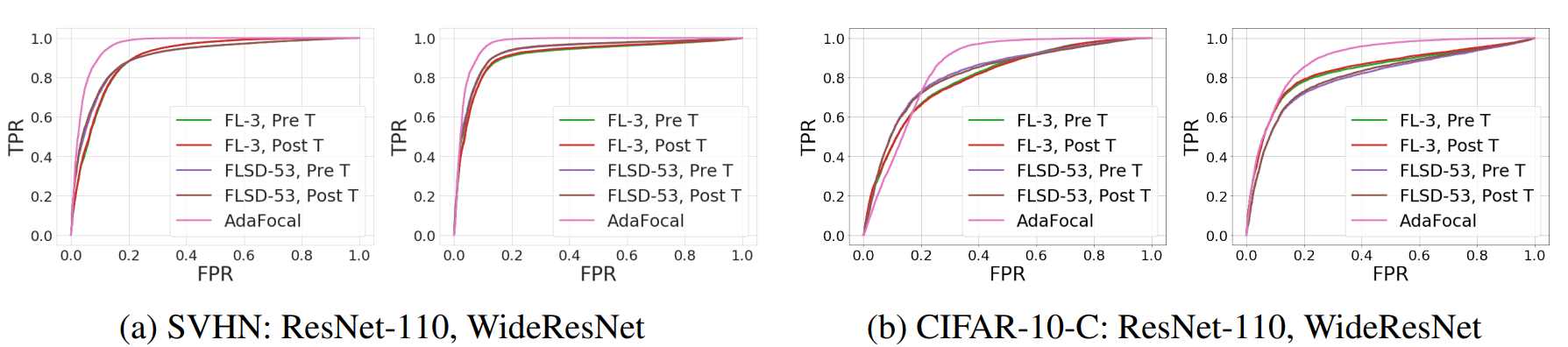
ROC曲線では面積が大きいほど性能が良いことを示します。これらのグラフからAdaFocalが最も性能が高いことがわかります。したがってAdaFocalはOOD detection taskにおいて有用性があるといえます。
まとめ
Focal Lossを改良したAdaFocalについて説明しました。
分類タスクにおいて、AdaFocalは既存手法と同等の分類性能を達成しながらもcalibrationを多くの場合で改善できることが示されました。
またOOD detection taskにおいても有効性があることがわかりました。
これらのことから、AdaFocalはAIの説明性や信頼性の向上において役立つのではないかと感じました。
補足
[1]この論文ではM=15としています。
[2]FLSDでは正解ラベルにおけるモデルの予測確率に応じてγを変更させます。この論文では、モデルの予測確率が0から0.2のときはγ=5、0.2以上1以下のときはγ=3としています。
[3]λ=1のとき精度が高いことが確認されたため、この論文ではλ=1としています。
[4]この論文ではγmin=-2 γmax=20としています。
[5]この論文ではSth=0.2としています。
[6]分布外検出タスク(OOD detection task)は学習データに含まれない入力データを検出するタスクのことです。AI-Scholarでも何度か取り上げられているので詳しくは以下のリンクをご覧ください。
・データの不確実性に備える|分布外データの検知性能を改善する「尤度比」とは?
・【無知の知】「これはわからない」とモデルに識別させる分布外検出手法と新規ベンチマークの提案



この記事に関するカテゴリー

