【無知の知】「これはわからない」とモデルに識別させる分布外検出手法と新規ベンチマークの提案
3つの要点
✔️ 学習データセットにないデータを識別することをout-of-distribution(OoD、分布外)検出という
✔️ 限られたクラスをよく分類できる優秀なモデルはOoD検出でもパフォーマンスが高い
✔️ 損失関数を工夫することでデータの新規性を検出することに成功
Open-Set Recognition: a Good Closed-Set Classifier is All You Need?
written by Sagar Vaze, Kai Han, Andrea Vedaldi, Andrew Zisserman
(Submitted on 12 Oct 2021 (v1), last revised 13 Apr 2022 (this version, v2)])
Comments: ICLR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
要約
現実の世界には、動物や物品等のオブジェクトは数え切れないほど存在します。そのため分類器が学習できるクラスは現実のほんの一部ですが、分類器は訓練したクラスにないサンプルでも既知のクラスに当てはめようとします。これでは、いくらモデルの性能が高くても分類自体は間違いです。そこで本論文では「これは学習したデータセットに含まれていない」ということを分類器自身に識別させる手法を紹介しています。
本論文では、Semantic Shift Benchmark(SSB)と呼ばれる指標を提案し、サンプルのセマンティックな(意味論的な)新規性を検出することに成功しました。
はじめに
分類クラス数が限られているクローズドな集合(closed-set)に対する画像認識タスクにおいて、深層学習は良い成果をあげてきました。次の課題はオープンなデータセットに対する画像認識(open-set recognition, OSR)です。つまりモデルは、あるデータが学習データセットに含まれているかどうかを判断する必要があります。
OSR問題はScheirerらが形式化し、その後も優秀な研究者らが取り組んできました。OSR問題を評価する上でベースラインとなるのはクローズドなデータセットで学習したモデルです。このモデルは損失関数にクロスエントロピー誤差を使って学習しており、出力はソフトマックス関数を用いています。以降この手法を単にベースライン、あるいは最大ソフトマックス確率(maximum softmax softmax probabilty, MSP)ベースラインと呼びます。なおMNISTやTinyImageNetを利用した既存のOSRに関する報告では、ベースラインを大きく上回っていることを先に述べておきます。
クローズドなデータセットで高い性能を発揮したモデルは、OSRにおいても過剰に既存のクラスに当てはめようとするため、OSRパフォーマンスが低いと予想されています。ところが興味深いことに、closed-setとopen-setでのパフォーマンスには相関があることが示されました。
関連研究
ScheirerらがOSR問題を定式化しました。BendaleとBoultは、Extreme Value Theory(EVT)に基づきOpenMaxアプローチを提唱しました。Nealらは、Generative Adversarial Network(GAN)による生成画像を使ってOSRに取り組み、のちにOSRデータセットの作成につながっています。
OSRは、分布外検出(out-of-distribution detection, OoD detection)、新規性検出(novelty detection)、異常検知(anomaly detection)、新規カテゴリ発見(novel category discovery)に深く関連しており、性質としてはOoD検出と類似しています。そこで本論文では新しいベンチマークを提案することで、OSRとOoD検出を区別し、本分野における新規性を提示します。
クローズドセットとオープンセットでのパフォーマンスの相関
限られたクラス数のデータセット(以後、クローズドセット)に対して優秀な分類器は、逆説的にクラス数に限りがないデータセット(以後、オープンセット)では性能が低くなるだろうと考えられています。なぜならこのような分類器は、入力データを高い確信度でどこか特定のクラスに当てはめようとするためです。しかし本論文では、クローズドセットでの性能がオープンセットでの性能と相関していることを示します。
\begin{equation}\mathcal{D}_{\text {train }}=\left\{\left(\mathbf{x}_{i}, y_{i}\right)\right\}_{i=1}^{N} \subset \mathcal{X} \times \mathcal{C}\end{equation}
まずOSRを定式化しましょう。訓練データD_trainは、入力空間Χ(註:大文字のカイ)と既知のクラス数Cの積に含まれます。
$$\mathcal{D}_{\text {test-closed }}=\left\{\left(\mathbf{x}_{i}, y_{i}\right)\right\}_{i=1}^{M} \subset \mathcal{X} \times \mathcal{C}$$
上記のように検証データセットも同様に表すことができます。これがクローズドセットの設定です。
$$\mathcal{D}_{\text {test-open }}=\left\{\left(\mathbf{x}_{i}, y_{i}\right)\right\}_{i=1}^{M^{\prime}} \subset \mathcal{X} \times(\mathcal{C} \cup \mathcal{U})$$
オープンセットでは、クラス数に制限がないので既知クラス数Cだけではなく未知クラスU分だけ要素が増えます。
$$p(y \mid \mathbf{x})$$
クローズドセットの場合、そのクラスである確率分布pは上記のように表すことができますが、オープンセットの場合は既知クラスCに含まれるかどうかの確率も必要になります。
$$p(y \mid \mathbf{x}, y \in \mathcal{C})$$
$$\mathcal{S}(y \in \mathcal{C} \mid \mathbf{x})$$
そのため、確率pに条件が付与されます。Sは既知クラスCに含まれるかどうかのスコアです。
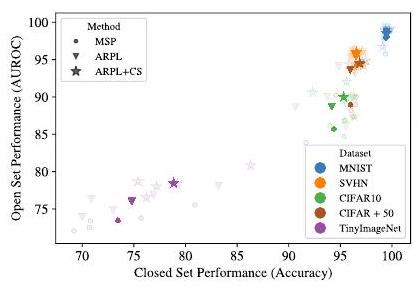
さて、上記はクローズドセットでの性能(Accuracy)とオープンセットでの性能(AUROC)の相関図です。本論文では、VGG16を軽量化したモデル(VGG32)とOSRに関する既存のデータセット(MNIST、SVHN、CIFAR等)を用いて評価しています。OSRベンチマークにはMSP(ベースライン)、ARPL、ARPL+CSの3つを用いています。色付きの点が、5つのデータセットに対する平均です。VGG32の場合、データセットが変わろうともクローズドセットとオープンセットの性能に相関が見られます。
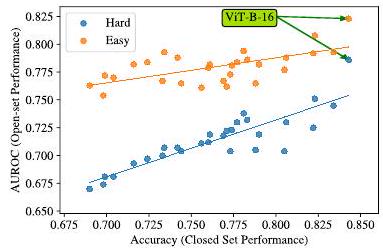
今度はデータセットをImageNetに固定して、モデルを変更した結果(各点がモデル)です。Hardは未知クラスが多く、Easyは既知クラスが多いという設定です。ViT-Β-16モデルは外れ値(性能がとても良い)ですが、データセットが共通の場合、モデルアーキテクチャを変更しても、クローズドセットでの性能とオープンセットでの性能に相関が見られます。
上記の結果は、大規模データセットでも同様でした。
新しいOSRベンチマークの提案:semantic shift benchmark
現状のOSRベンチマークには2つの欠点があります。1つはデータセットが小さいこと、もう1つは「セマンティッククラス」の定義が曖昧であることです。つまり何を持って新しい未知のクラスか判断する基準が曖昧ということです。本論文では新しいデータセットと評価方法を提案し、これをベンチマークとしています。
ImageNetをもとにしたデータセットでは、意味的距離(semantic distance)を使って未知クラスを定義します。ImageNetは、動物>脊椎動物>哺乳類>象のような階層構造で分類されています。この階層構造のノード間距離を意味的距離とみなします。ImageNet-1Kの1000クラスを既知クラスとして、ImageNet-21Kの21000クラスから画像をランダムに選択して、個々の画像と既知1000クラスの意味的距離の総和をとります。これをソートして、意味的距離が小さい群をDifficult、大きい群をEasyと分けます。

上記はその例です。緑がEasy、黄がMedium、赤はDifficultを示すペアで、実戦で囲まれた方が既知クラスです。赤ペアは近縁種の鳥であり、区別が難しいというわけです。
新しい評価方法:最大ロジットスコア
本論文の最初に述べたように、ベースラインの評価方法は最大ソフトマックス確率(MLP)でした。これに対して著者らは、新しく最大ロジットスコア(MLS)という手法を提案しています。ロジットとは、ソフトマックス関数の入力であり、出力層の1つ前の層の出力です。実は、未知カテゴリのロジットは小さくなる傾向があり、これを利用しています(註:ソフトマックス関数を通過すると出力の総和が必ず1になり、確率値ではロジットの大小がマスクされるためです)。
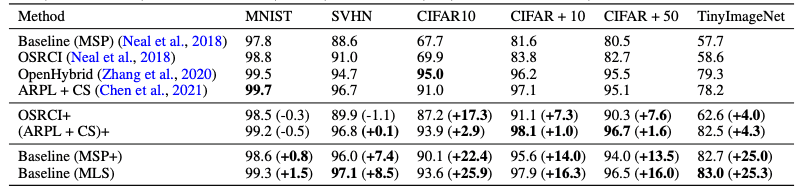
上記は、既存研究(OSRのSOTAであるARPL等)との比較です。既存研究ではデータ拡張を工夫したりすることでクローズドデータ性能を上げてきましたが、評価関数をMLSに変更するだけでオープンセット性能が向上することがわかりました。
結論
クローズドデータ性能が高いほど、オープンデータ性能も高いことが明らかになりました。やはりクローズドデータ性能を向上させることが重要であると再確認され、本論文では新しい評価関数であるMLSを提案しています。またOSRのために新しいデータセットも提案し、セマンティッククラスを明確にすることでより正確なベンチマーク法を今後の研究に提供しました。






この記事に関するカテゴリー


