深層学習で映像から単一音響を立体化する。「2.5D音響」の新手法とは
テキサス大学とFacebook AI Researchの研究チームは、deep learningを用いて、動画から、単一なモノラル音響を3Dに近い「2.5D」音響に変換するシステムを発表しました。今回提案された2.5Dビジュアルサウンドにより、音源の位置を感じれるような没入感のあるオーディオ体験ができるようになりました。
2.5D音響とは
人が多くの同時のものを組み合わせることによって世界を知覚することは、実世界の感覚と環境の豊富さを捉えるために不可欠です。特に、視覚と聴覚の流れを含む感覚の流れは非常に重要な情報を伝えることが多く、音声データと視覚データの両方が重要な空間情報を伝達します。
例えば、近くの木で鳥のさえずりが聞こえれば、見なくても比較的素早くそのおおよその場所を特定できます。
このように人間の聴覚系は2つの耳を使って複雑な混合物から個々の音源を抽出しますが、人間の空間認知に対し、あたかも録音現場にいるが如く、再生音響によって感じさせるというのが3D音響です。
3D音響は立体音響、または3Dオーディオとも呼ばれ、音を再生する際に3次元的な音の方向や距離、拡がりなどを聴覚に与えます。
例えばゲームで、人が反対方向から歩いて自分とすれ違う場面があったとします。この場合3D音響の環境では、足音やきぬ擦れの音が遠くから来て耳元で聞こえてまた遠くなっていくというのを体感できます。
しかし、リアルな3D音響の生成は難しく、入手するには専門知識と高価な機器が必要でした。
そこで今回、ビデオフレームに含まれる空間情報を注入することによって、サウンドを立体化させるというアプローチが提案されました。
論文内では、ビデオフレームに見られるオブジェクトとシーン構成を利用して、単一のモノラル音を3Dにかなり近い立体的な音響に変換させる方法を開発しており、これを2.5D音響と呼んでいます。
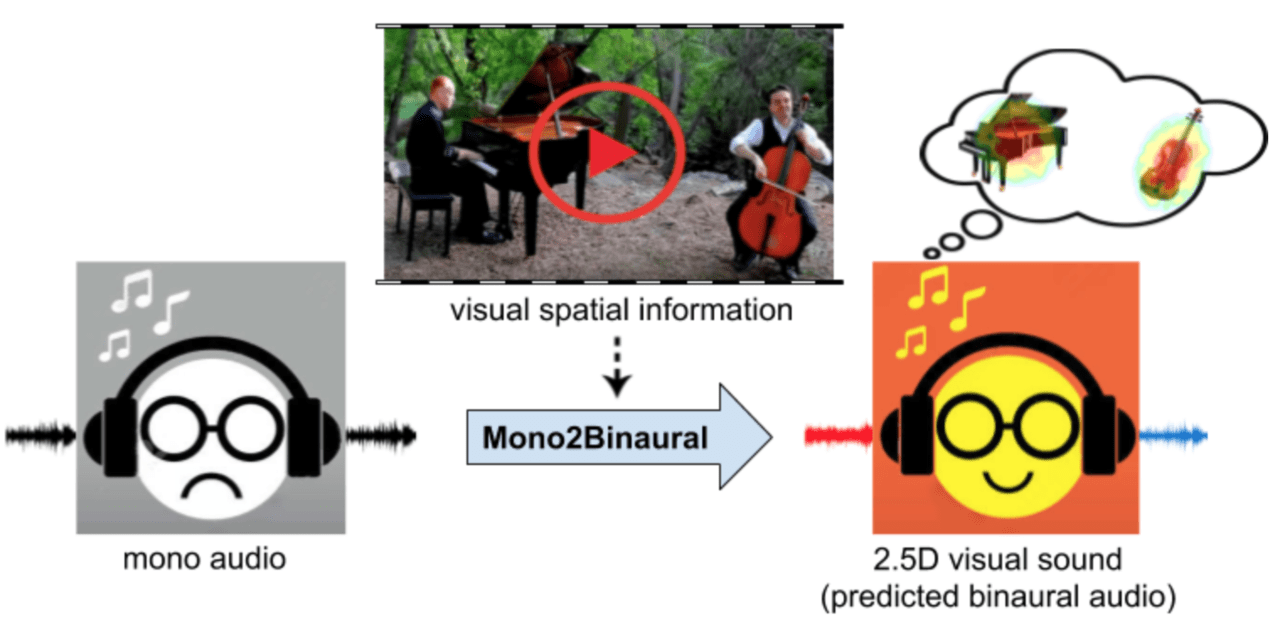
例えば、上図の動画では、左にピアノ、右にチェロを弾く人がいます。通常の音響ではどこから聞こえているか分かりませんが、本提案手法を用いると、音源の位置を感知しながら視聴することができます。
音響を立体化させるアルゴリズム

研究者たちは、ビデオ付きの2,000以上の音楽クリップの3D音響のデータベースを構築することから始めました。オーディオとビデオをキャプチャするために使用されたのは、人間の耳を模倣した、3Dioバイノーラルのマイクの上にGoProカメラを取り付けた偽耳レコーダーで、それぞれのマイクが方向の変化を拾いました。
その後、このデータセットを使用して機械学習アルゴリズムをトレーニングしたとのこと。
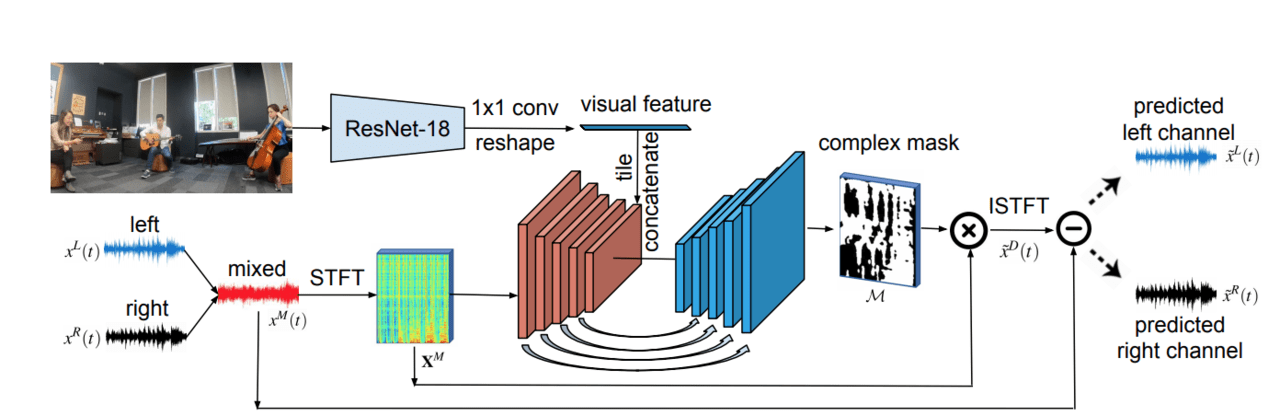
本提案手法は、U-NetとResNetの畳み込みニューラルネットワークに基づいたMono2Binauralと呼ばれるフレームワークを使用しています。
単一モノラルオーディオとそれに付随するビジュアルフレームを入力とし、ResNet-18で視覚的特徴を抽出、U-NETで音響的特徴を抽出して共同視聴覚分析を行い、ビデオの空間構成と一致する2.5D音響を推定します。
これにより推定された2.5Dビジュアルサウンドは、音源の位置を感じさせることができ、より没入感のあるオーディオ体験を提供できます。
課題
しかし、今回の手法では、音源がビデオに表示されていない場合は音の方向を近似できなかったとのこと。今後の課題としては、オブジェクトの位置特定と動きを取り入れ、シーンサウンドを明示的にモデル化する方法を模索する予定としています。



この記事に関するカテゴリー






